Basic Deep Learning math and 知识笔记
Basic DL Notes
Basic Deep Learning math for Coursera Course Deep Learning by Andrew Ng, Kian Katanforoosh and Younes Bensouda Mourri.
Please expect some loading time due to math formula.
Basic NN
Matrix size: m training examples, n_x features. Matrix.shape = (n_x,m)
Activation function:
Relu:
Logistic regression with sigmoid: ,when
Logistic Regression loss function:
Logistic cost function:
Gradient decent:
partial derivative: Do check the relationship of and other parameters.
Chain rule:
Logistic Derivative (sigmoid):
Vectorization:
Softmax function:
Bias & Variance & human level performance:
- it is important to clear Bayes error
| % | high variance | high bias | bias + variance |
|---|---|---|---|
| Dev set error | 11 | 16 | 30 |
| Train set error | 1 | 15 | 15 |
| optimal (Bayes) error | 0% | 0 | 0 |
L2 regularization:
Dropout: randomly close some nodes
D1 = np.random.rand(A1.shape[0],A1.shape[1])
D1 = D1 < keep_prob
A1 = A1*D1
A1 = A1/keep_prob
He initialization: after np.random.randn(..,..), multiply the initialized random value by
Mini-batch gradient descent:
- If mini-batch size == 1, noise up, stochastic Gradient Descent. If mini-batch == m, time cost up, batch gradient descent.
- small training set (m<2000) use batch gradient.
- mini-batch size recommend to set as to fit GPU, CPU memory.
Momentum: Momentum takes into account the past gradients to smooth out the update.
where L is the number of layers, 𝛽 is the momentum and 𝛼 is the learning rate. Common values for 𝛽 range from 0.8 to 0.999
RMSprop:
Adam:
where:
- t counts the number of steps taken of Adam
- and are hyperparameters that control the two exponentially weighted averages. around 0.9, around 0.999
- is a very small number () to avoid dividing by zero.
Gradient Checking:
Learning rate decay:
Learning rate or or or manual decay
Tuning process: 1. 2. , #layers, mini batch size 3. # layers, learning rate decay. Do not use grid, choose random number
Error Analysis:
- Consider Train, Test different or Train, Dev different.

Artificial Data Synthesis: if just synthesize a small subset, you will overfit to the synthesize subset.

Transfer Learning: Task A B have same input, low level feature from A could help for learning B.
End-to-end learning: e.g. speech recognition. Need large amount of data. Let data speak, less hand-designed needed.
Computer Visualization
CNN
padding:
- same convolution:
- valid convolution: no padding. input size , filter size , output size
stride convolutions: for stride = 2, output size is
multiple filters:
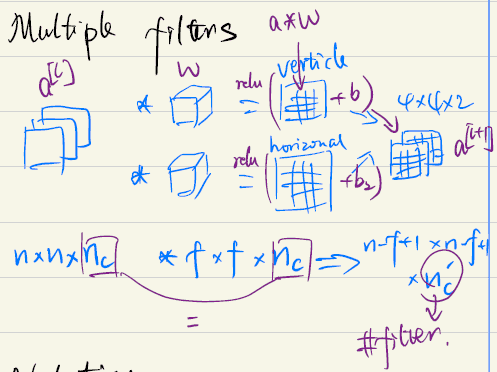
codes for understand process only
def conv_forward(A_prev, W, b, stride, pad):
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
# output dimension
n_H = int((n_H_prev-f+2* pad)/stride)+1
n_W = int((n_W_prev-f+2* pad)/stride)+1
Z = np.zeros((m,n_H,n_W,n_C))
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m): # m example
a_prev_pad = A_prev_pad[i,:,:,:]
for h in range(n_H):
vert_start = h * stride
vert_end = vert_start + f
for w in range(n_W):
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C): # c: number of channels(filters) in each layer
a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
weights = W[:,:,:,c]
biases = b[:,:,:,c]
Z[i, h, w, c] = conv_single_step(a_slice_prev, weights, biases)
cache = (A_prev, W, b, hparameters)
return Z, cache
Pooling Layer: Max pooling, Average pooling
Convolutional NN backpropagation:
mask for max pooling backward pass, average for average pooling backward pass
Model Examples Summary
Notation:
- filter: [filter size, stride]
- A: (Height, Width, Channel)
LeNet-5 (activation: sigmoid or tanh)

AlexNet (Relu)
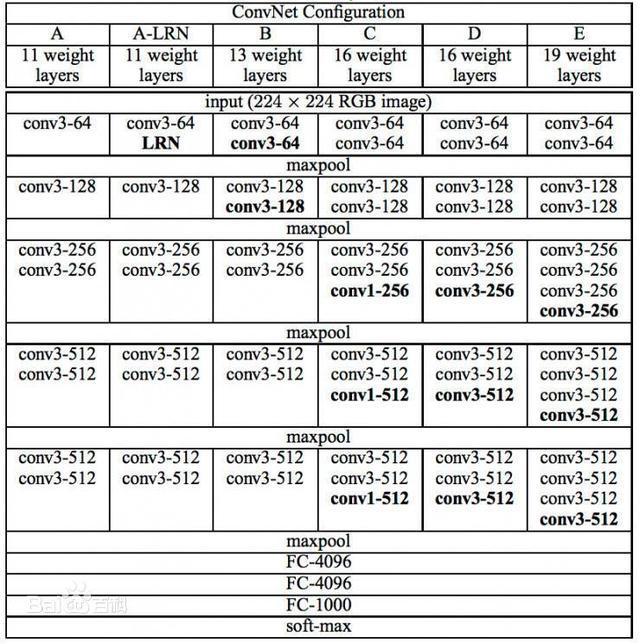
VGG-16 (source code here)
Residual Network (ResNets)
- ResNets not hurt NN, if lucky can help.

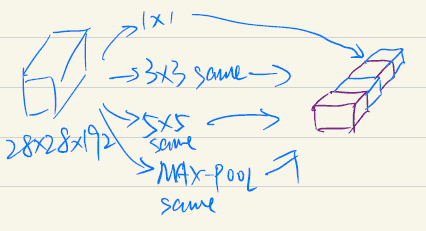
Inception net keras source code
Data argumentation: 1. mirroring 2. random cropping 3. rotation shearing, local wraping 4. color shifting
YOLO
bounding box: : middle point,height, width
Anchor boxes : same box overlap objects
Intersection over union
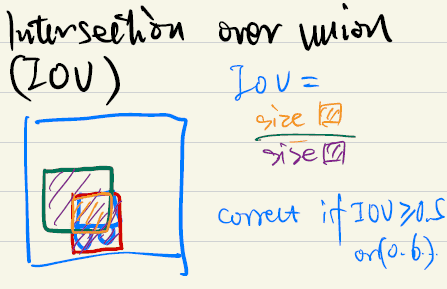
Non-max suppression
- discard all picture with low score (e.g. <0.6)
- select only one box (e.g. with max score) when several boxes overlap with each other and detect the same object.
Face recognition
Make sure Anchor image is closer to Positive image then to Negative image by at least a margin .
minimize the triplet cost:
Neural Style transfer
Notation: : the hidden layer activations in the layer after running content image C in network.
Notation: : the hidden layer activations in the layer after running generated image G in network.
- The content cost takes a hidden layer activation of the neural network, and measures how different 𝑎(𝐶) and 𝑎(𝐺) are.
- When we minimize the content cost later, this will help make sure 𝐺 has similar content as 𝐶.
Gram matrix
Notation:
Notation: : correlation of activations of filter i and j
Notation: : prevalence of patterns or textures
- The diagonal elements measure how "active" a filter is.
- For example, suppose filter is detecting vertical textures in the image. Then measures how common vertical textures are in the image as a whole.
- If is large, this means that the image has a lot of vertical texture.
Style cost:
Combine style cost for different layers:
HINTS:
- The style of an image can be represented using the Gram matrix of a hidden layer's activations.
- We get even better results by combining this representation from multiple different layers.
- This is in contrast to the content representation, where usually using just a single hidden layer is sufficient.
- Minimizing the style cost will cause the image 𝐺G to follow the style of the image 𝑆S.
Total cost to optimize:
- The total cost is a linear combination of the content cost and the style cost .
- and are hyperparameters that control the relative weighting between content and style.
RNN
Basic RNN
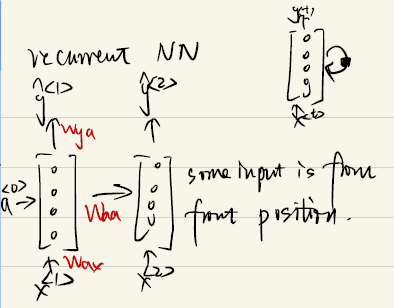
Forward Propagation
Backpropagation
Gate Recurrent Unit
Forward Propagation
LSTM
LSTM cell
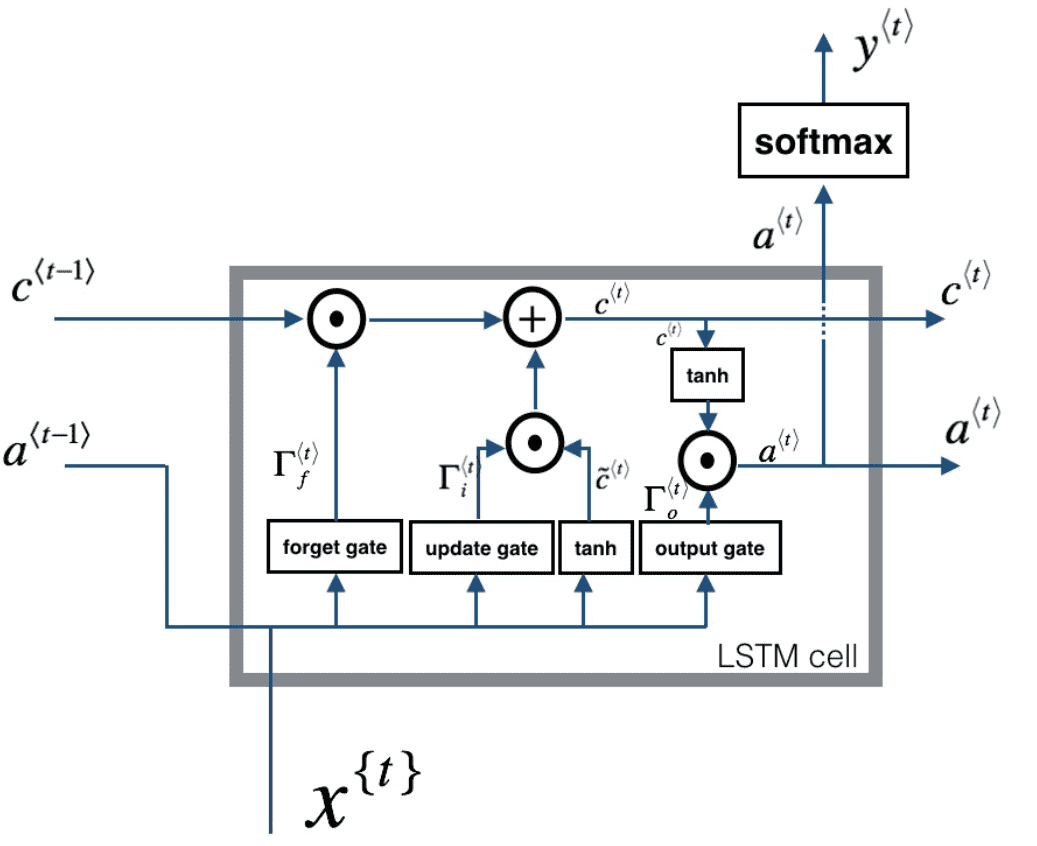
Forward Propagation
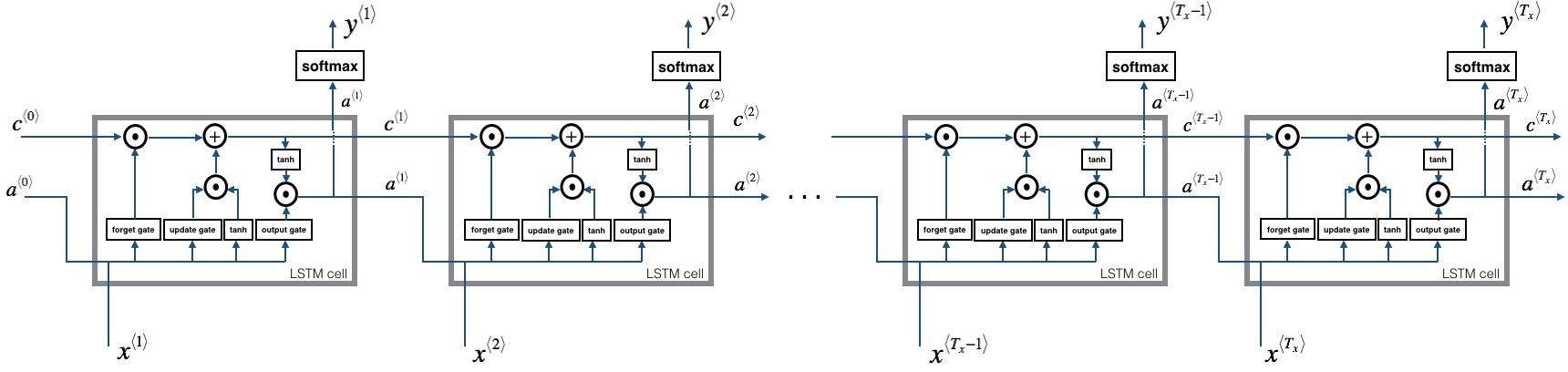
concatenate hidden state and input into single matrix:
Backpropagation
Notation: is same as in previous discussion.
in the following, . Same for $\gamma_u^{\langle t \rangle}, \gamma_f^{\langle t \rangle} $
Parameter source hints for partial derivative: : , and : , : , : ,
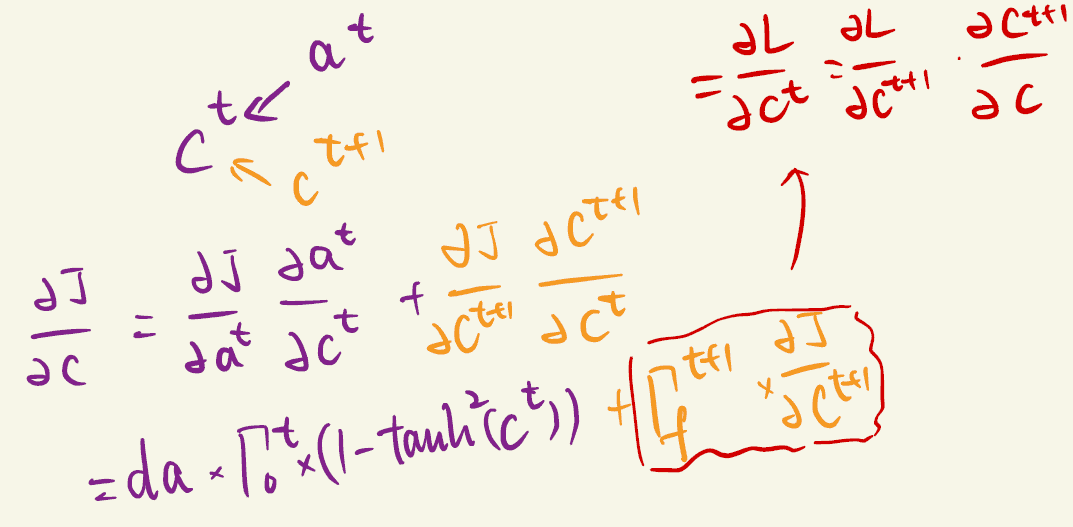
NLP
Word2Vec
Cosine similarity:
Debiasing word vectors:
Neutralize bias for non-gender specific words
Equalization algorithm for gender-specific words
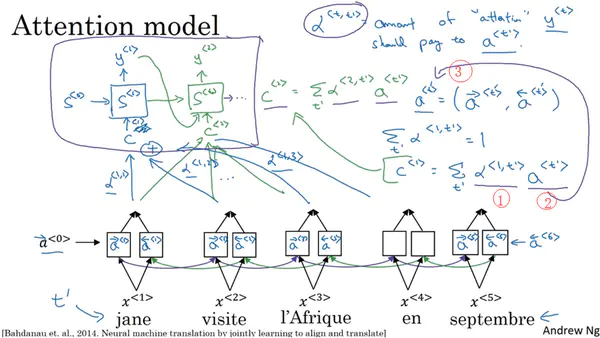
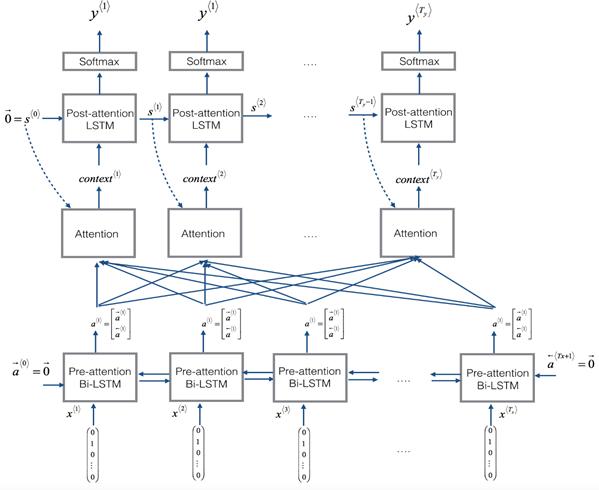
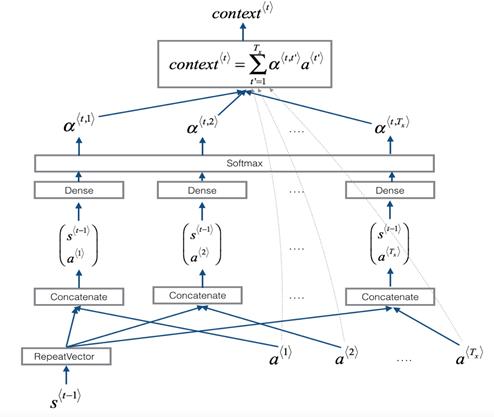
Attention model