白板机械学习笔书|线性回归
线性回归基础数学。笔记思路源于 shuhuai-白板机械学习 系列教程。
线性回归基础
最小二乘法
最小二乘法矩阵表达的损失函数:
我们的目标就是使得以上的均方差最小。对齐求导并令导数为零。
几何意义
将 中的每一列看做一个向量,那么 可以看做一个 维空间。
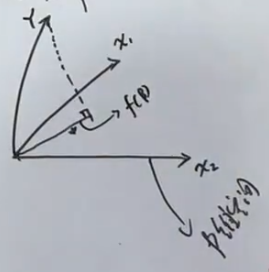
不在该空间内,因此 在该平面内的投影就是误差最小的预测值。假设 的投影在 上,那么虚线为 。
虚线垂直与 ,所以 。求得
从概率角度看,最小二乘法即为假设噪声符合高斯分布的最大似然估计。
假设
使用最大似然估计求解:
因此结果与上节最小化损失函数结果一样。 可以看出最小二乘估计假设了噪声服从正态分布。
正则化
从数学角度看 ,用上文方式求解最优 时,若 不成立,则 可能是不可逆的。导致不能求得 的解析解。
添加了正则化后的损失函数为:
令导数为零:
其中 为半正定,加上 后为正定,即可逆。
从直观角度看,正则化系数越大,偏差也就越大,但也防止了过拟合。
加入了 L2 正则化的最小二乘估计其实也等价于服从高斯分布的噪声和先验的最大后验估计 MAP。 MAP 假设参数服从某个分布,而后根据先验知识对参数进行不断调整。数据越多,先验知识的主导地位越大。
给定: 假设
因此:
这个结果与上一节中加入了 L2 正则化的损失函数一致。
线性分类
线性回归(Linear Regression)在统计机器学习中占据核心地位,其有三大特性: 线性 、 全局性 和 数据未加工性
非线性可能出现在三方面: 属性非线性,如多项式回归。 全局非线性,如激活函数非线性; 系数非线性,指系数不确定性,如神经网络(感知机)。
全局性指模型在全部特征空间上是恒定的,没有将特征空间划分为不同区域。决策树就不符合全局性。
数据未加工,即使用原始数据。如 PCA、流形都属于数据加工。
线性分类主要通过激活函数和降维带来分类效果
感知机
模型:
其中 为正负符号
损失函数为预测错误的样本个数:
无法直接对上市求导,因此可以间接通过 SGD 优化下面函数来求解:
逻辑回归
逻辑回归可以理解为:激活函数使用了 sigmoid 的线性回归。
为什么选 sigmoid
逻辑回归不能使用平方损失的其中一个原因是,MSE 的梯度为: 当误差越大,更新越小,与我们的期望不符。相比较交叉熵的梯度:
逻辑回归,线性回归均属于 Generalized Linear Model。考虑一个分类或回归问题,GLM 有以下三个假设:
- 服从指数族分布
- 给定 x,问题的目的是预测 在条件 x 下的期望
- 指数族分布的参数
因为是二分类问题,假设 服从伯努里分布,因此:
指数族分布
伯努利的指数族分布形式:
所以
使用 MLE 求解最优参数:
此处 为负的交叉熵。 因此最小化交叉熵与 MLE 是等价的。
由于概率的非线性,在实际训练中,采用梯度下降或拟牛顿法来进行优化。
朴素贝叶斯
为简化运算,提出了条件独立假设: