bert 蒸馏小综述
主要参考了 BERT 蒸馏完全指南|原理/技巧/代码 一文,其中对部分论文的笔记有些抽象,因此遍对提及的蒸馏论文进行了阅读与笔记补充总结。同时总结了 textbrewer 相关使用说明。先来对所有介绍到的模型做个总结:
Distilled BiLSTM - 将 BERT LARGE 蒸馏到了 BiLSTM 上,采用 MST 目标函数与数据增强。 BERT-PKD - 不同于前者,BERT-PKD 加入了对中间层
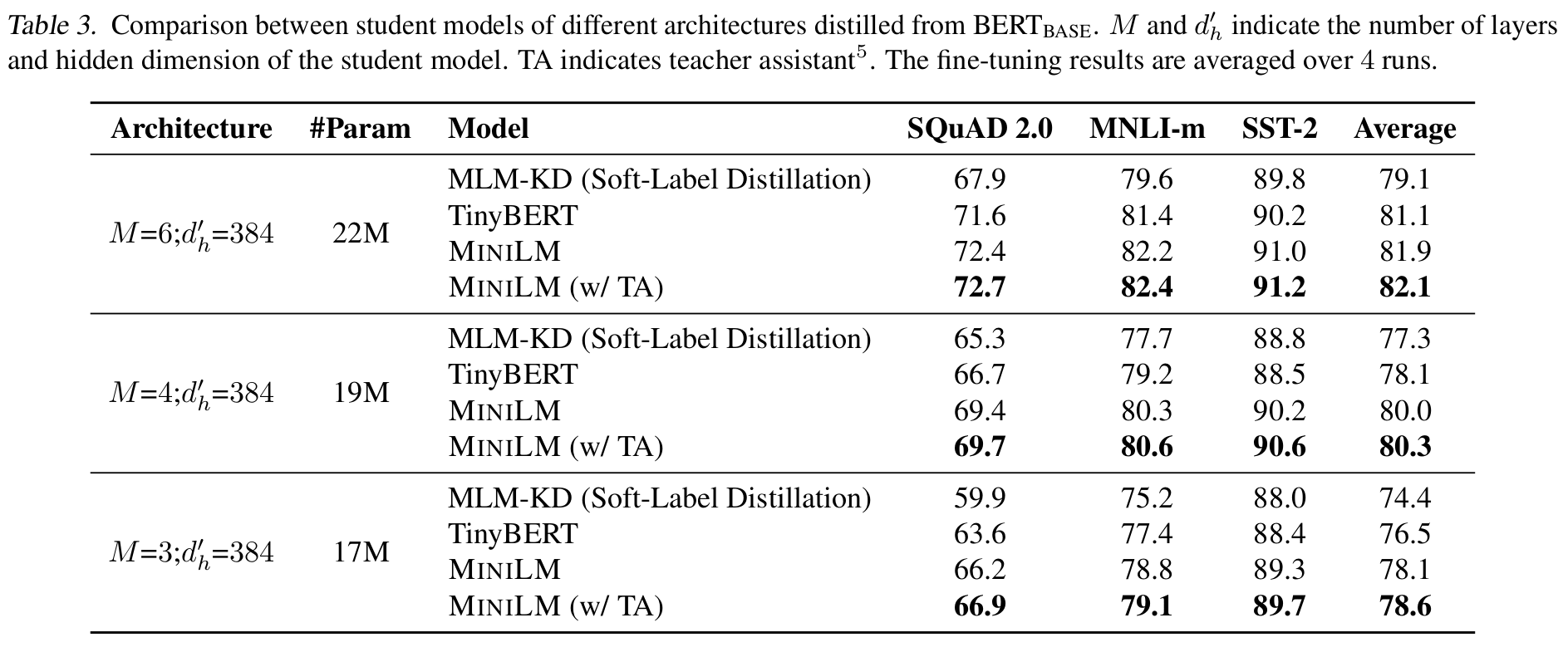
[CLS]位置上隐状态的拟合。 DistilBERT - 在预训练阶段进行蒸馏,6 层保留了 97% BERT 的表现 TinyBERT - 结合预训练蒸馏与微调蒸馏,提出注意力矩阵蒸馏。速度 x9.4 的 4 层 BERT 达到 96.8%BERT 效果。 MobileBERT - 保持层数,使用 bottlenect 减少维度。速度 x5.5,各种任务上与 BERT 相差约 1%。 MINILM - 提出 Value-Relation Transfer 与助教机制。同样参数数量下,效果由于 TinyBERT,DistillBERT。TextBrewer - 实用的蒸馏框架。
最基础的蒸馏
论文[1]提出了基础的蒸馏方案。在大模型(又称教师)蒸馏到小模型(又称学生)的过程中。学生需要尽可能的拟合教师模型的输出概率 (又称 soft target):
在此之上同时拟合真实概率 ,于是我们有了新的 loss(又称 hard target):
其中 可以使 hard 和 soft 两个 target 比重相当,避免因 soft target 过小而导致的训练问题。
在蒸馏时考虑使用高温度 T 来使 softmax 分布变得平滑,新模型在相同 T 下进行蒸馏,在训练结束以后使用正常温度 T=1 进行预测。这样做也可以防止过拟合。(感觉有点 label smoothing 的效果)
当 T 足够大,且 logits 的分布均值为 0 时,优化概率交叉熵与优化 logits 的平方差是等价的。论文中也给出了相应的数学证明。
bert 蒸馏
Distilled BiLSTM
将 BERT LARGE 蒸馏到了 BiLSTM 上,采用 MST 目标函数与数据增强。
Distilled BiLSTM 一文采用的目标函数为:
他们发现采用 MSE 的蒸馏目标会比交叉熵好。
面对数据集小的问题,作者随机使用以下方式进行数据增强,来获得更多的无监督语料。
- 随机的 mask 掩码
- 将随机词替换为相同 POS 属性的词
- 随机截取 n-gram 作为样本
他们使用教师模型在无监督语料上进行标记,从而扩大训练的数据集。
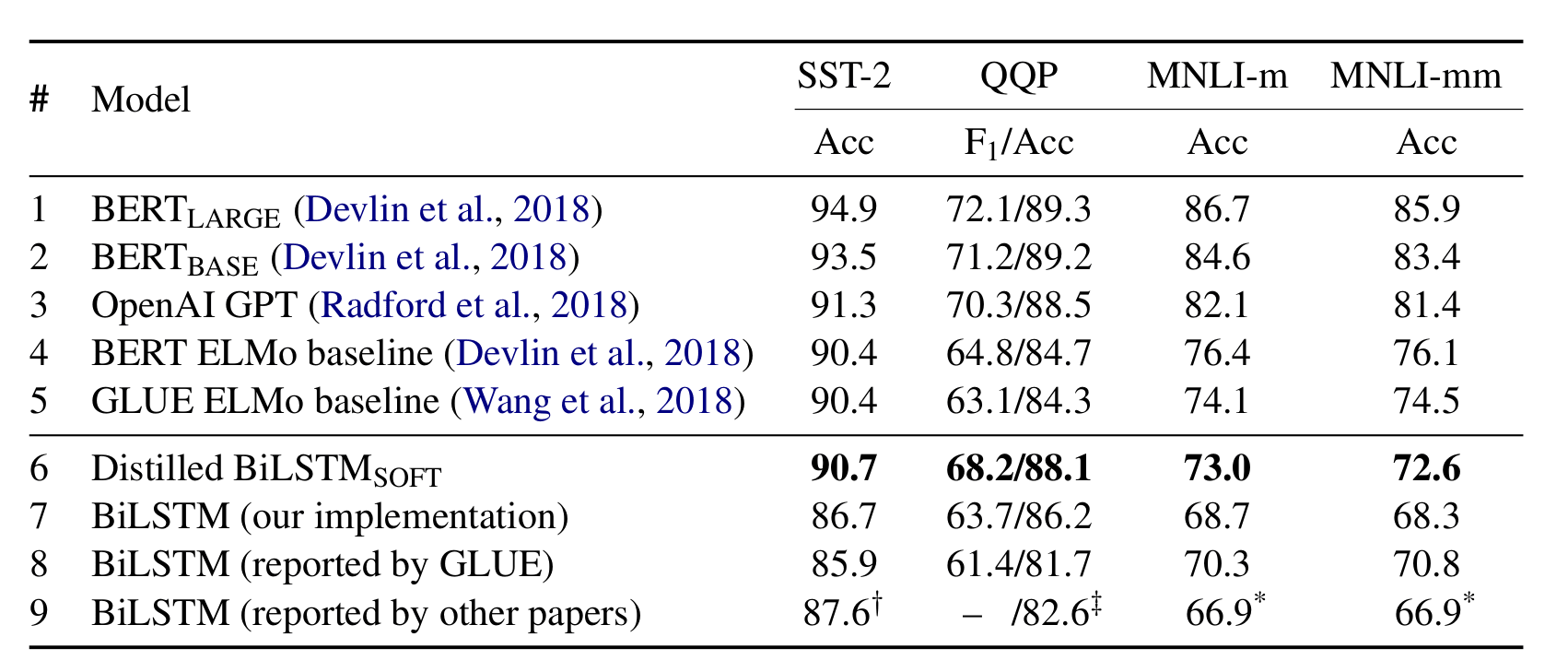
(实验结果,蒸馏比得上 ELMO 了)
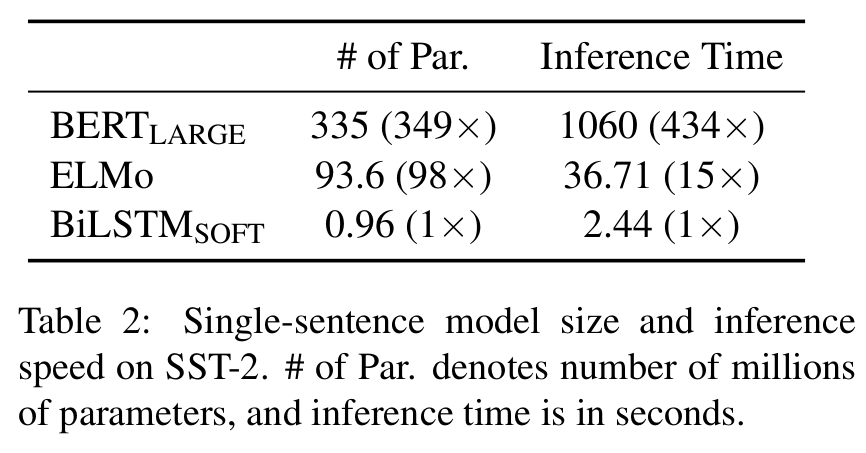
(参数与运行速度对比)
BERT-PKD
不同于前者,BERT-PKD 加入了对中间层
[CLS]位置上隐状态的拟合。
使用教师与学生模型 [CLS] 隐状态之间的 MSE 作为额外的损失。
为了计算 学生模型的 hidden size 需要与教师模型一致。这也限制了蒸馏的大小。
那么要选择哪些层进行蒸馏呢?作者对 skip 和 last 两种方法进行了测试。发现 skip 的结果会相对好一点点。可能蒸馏层的分布更广泛,能够更好的概括模型精髓?
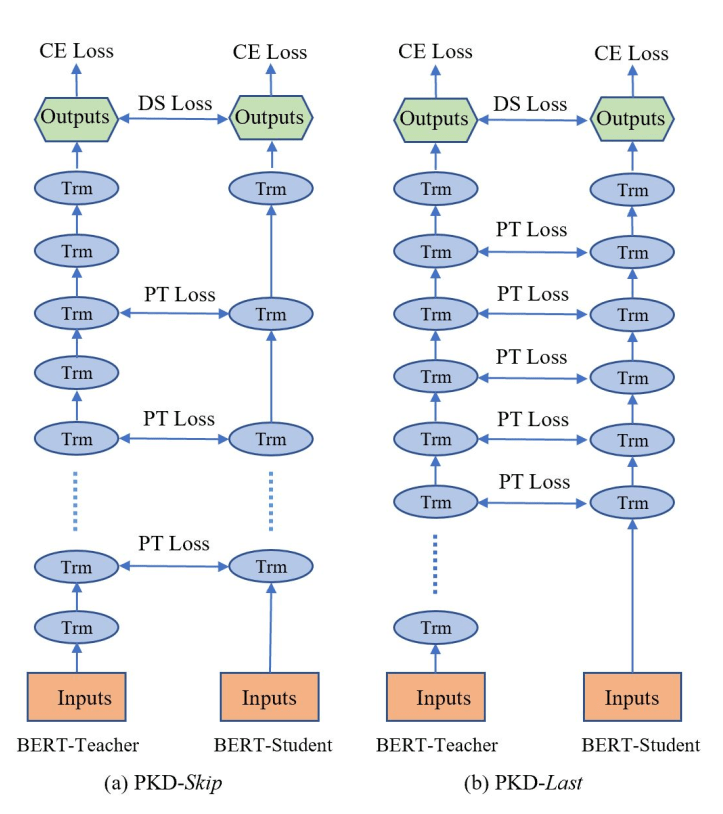
(skip 与 last 两种蒸馏选择方案)
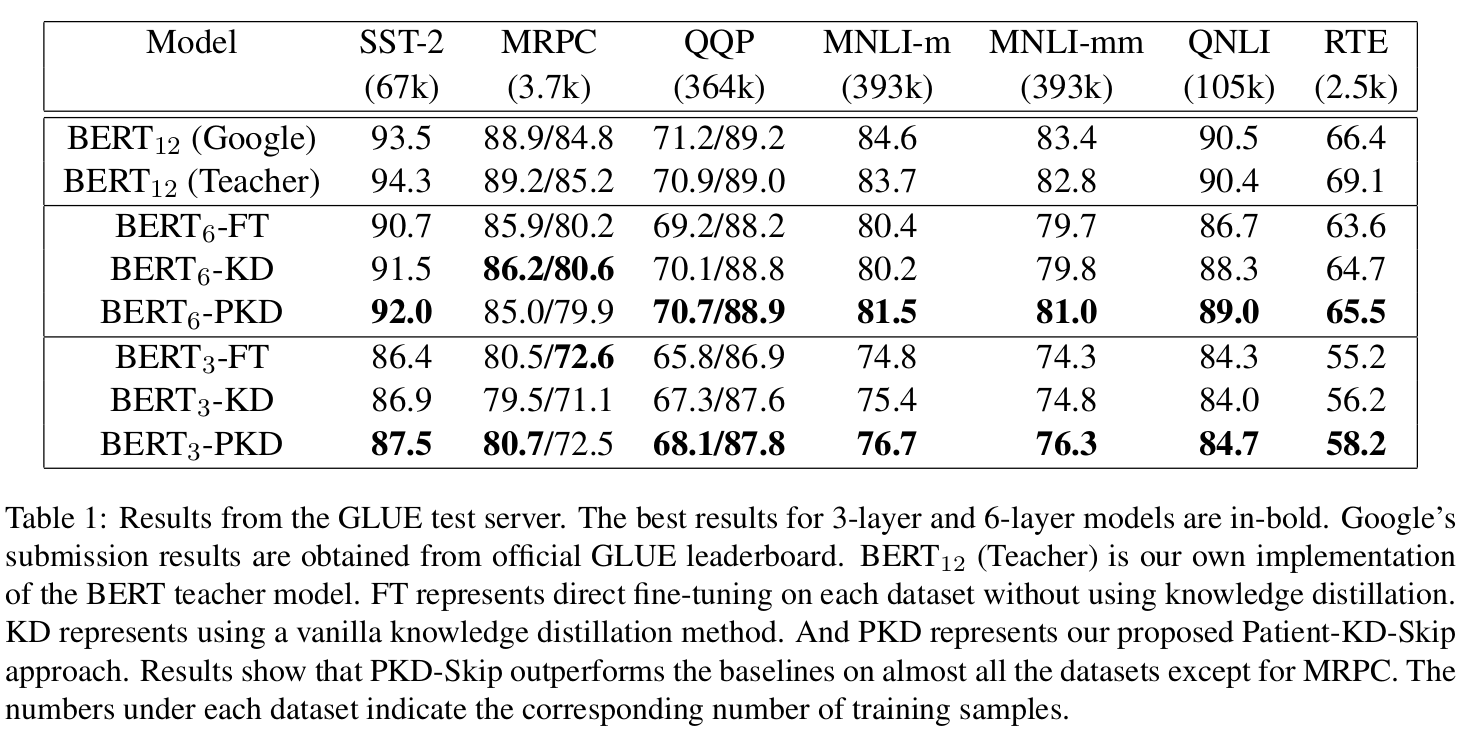
(蒸馏前后对比,BERT3 表示蒸馏到 3 层)
DistilBERT
在预训练阶段进行蒸馏
学生模型使用了与 BERT 相似的架构,移除了 token-type embeddings 和 pooler,层数消减了一半(12 层的 bert 蒸馏成了 6 层)。
学生模型的初始化比较重要 ,学生模型采用了教师模型的参数初始化(层数选择与 PKD-skip 一样)
训练的目标函数由:1.学生与教师模型见的 概率交叉熵 。2.训练任务对应的损失函数(如对于 MLM 预训练就是用 )。3.最后一层隐状态之间的 cosine loss 组成。
预训练蒸馏时使用与 BERT 预训练相同的语料。在 8 个 V100(16GB)上耗时 90 小时。
最终 DistillBERT 保留了 97% BERT 的表现。 参数数量减小一半 ,运行时间减少 1/3。
TinyBERT
结合预训练蒸馏与微调蒸馏,提出注意力矩阵蒸馏
TinyBERT 采用了两阶段的蒸馏,首先对没有 finetune 的预训练 BERT 模型进行蒸馏。
在下游任务中借助 finetune 好的 BERT 和 GLOVE 通过字符级别的自向量替换来进行数据增强。最后使用 finetune 好的 BERT 作为教师模型进行蒸馏。
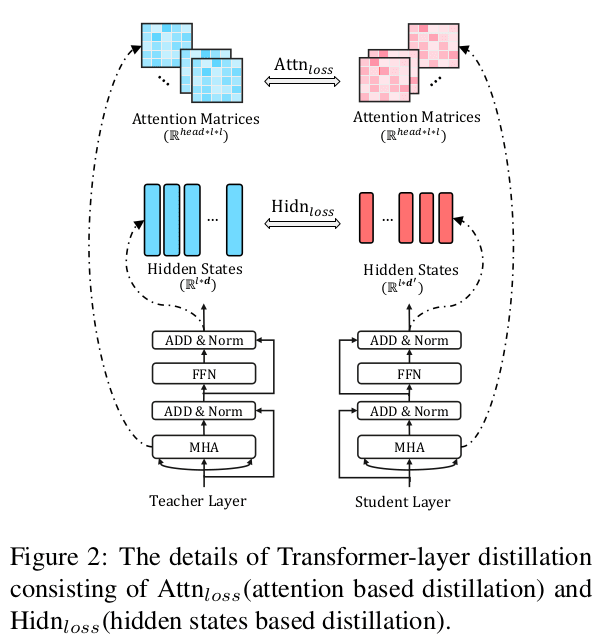
(图: 注意力蒸馏 Transformer distillation)
整个模型的 loss 函数为不同 Transformer 层损失函数的加权平均,
其中,注意力矩阵的损失函数被定义为:。 为注意力头数, 为注意力矩阵。相比于使用 Softmax 之后的 ,论文发现使用未归一化的注意力矩阵蒸馏效果更好,收敛更快。
注意力层的输出损失被定义为:。其中 为注意力模块中前向传播(FFN)输出的隐状态结果。 为可学习矩阵,用来将学生隐状态的维度 转换为与教师模型相同的维度 。
Embedding 层的损失定义为: 。其中 为模型对应的 Embedding。
输出层的损失为传统的交叉熵损失 。 为 logit。
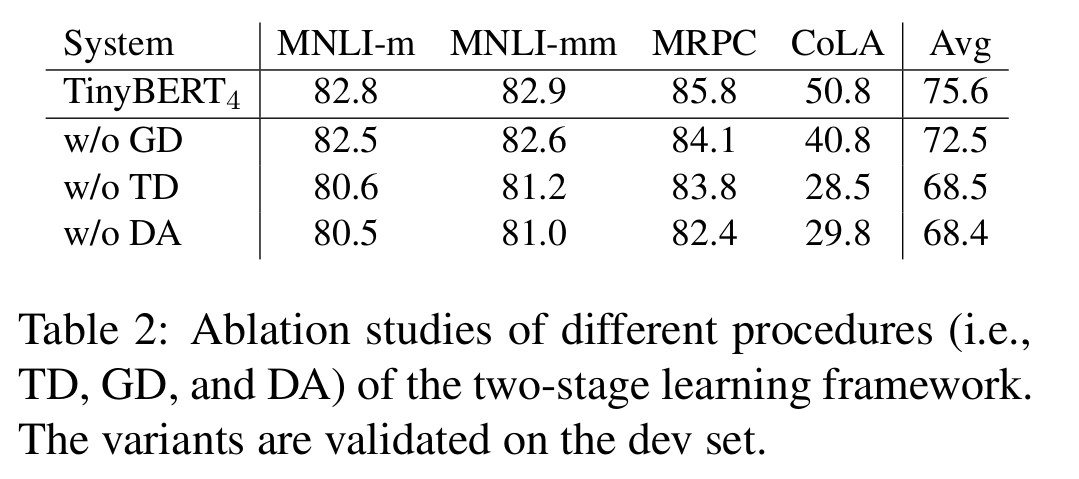
由不同阶段的消融实验看出,数据增强>精调蒸馏>预训练蒸馏
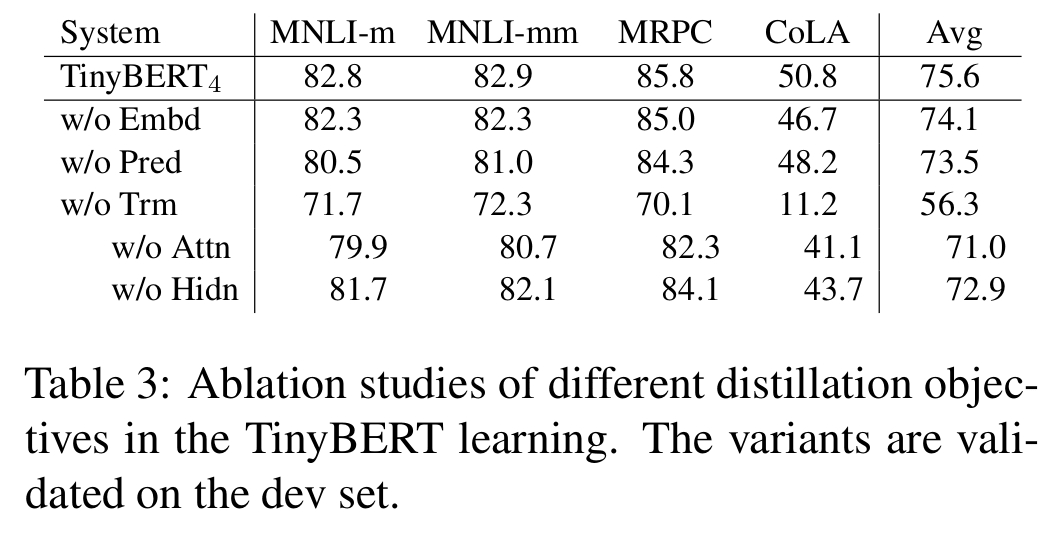
整体来说,对注意力模块蒸馏带来的收益是最大的,其次是输出层、嵌入层。
MobileBERT
保持层数,减少维度
要对不同维度的模型进行蒸馏,一个关键点在于 Bottleneck。如下图 MobileBERT 使用两个 线性层将模型的输入与输出映射到了 512 维度。 (对 BERT-LARGE 就是 1024 映射到 512,对 MobileBERT 就是 128 到 512)。当然单单对学生矩阵添加 Bottleneck 也可以实现维度匹配,但作者发现同时对教师与学生模型进行维度转变效果最好。
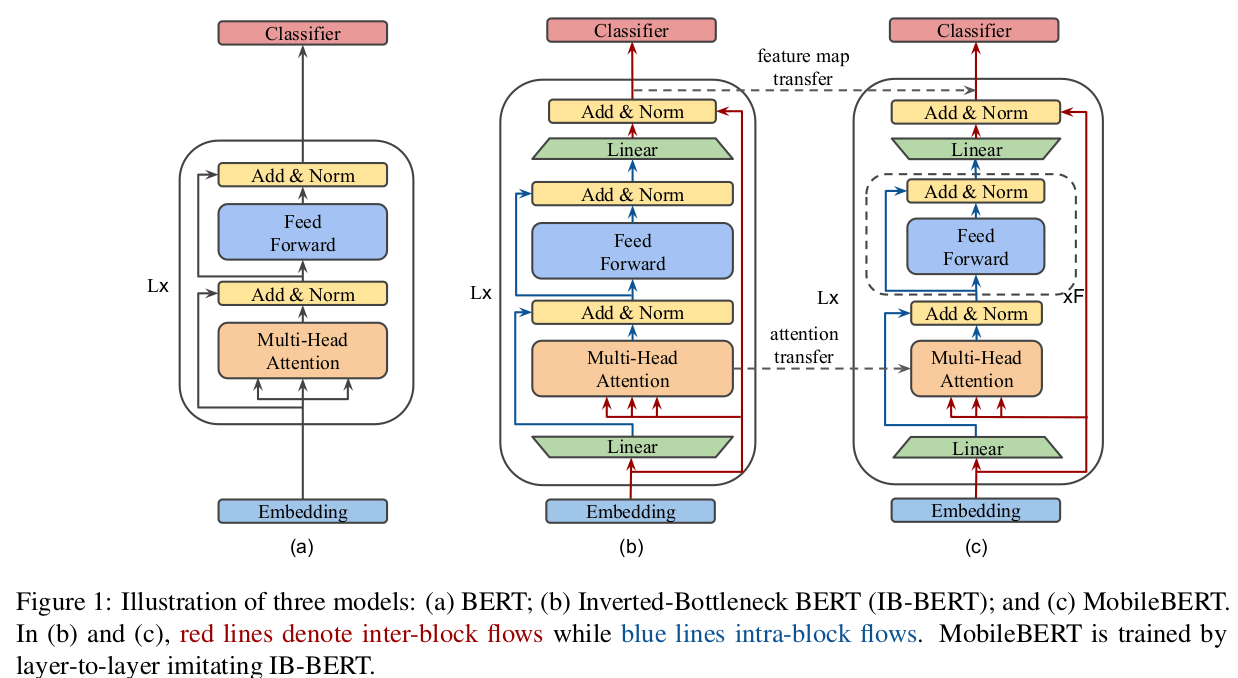
embedding 层使用大小为 3 的 1D 卷积核将嵌入维度从 128 映射到 512
蒸馏目标
pre-training distillation 预训练蒸馏的目标函数为: 即 MLM 任务,NSP 任务的损失加上 MLM 蒸馏的损失。
Attention Transfer 注意力模块的蒸馏目标为:。即每个多头自注意力矩阵的 KL 散度。
Feature Map Transfer 每个模块的隐状态输出之间的 MSE 也被作为蒸馏目标: 。作者发现,将这项差异分解成归一化后的差异与统计差异有助于训练的稳定性。
训练策略
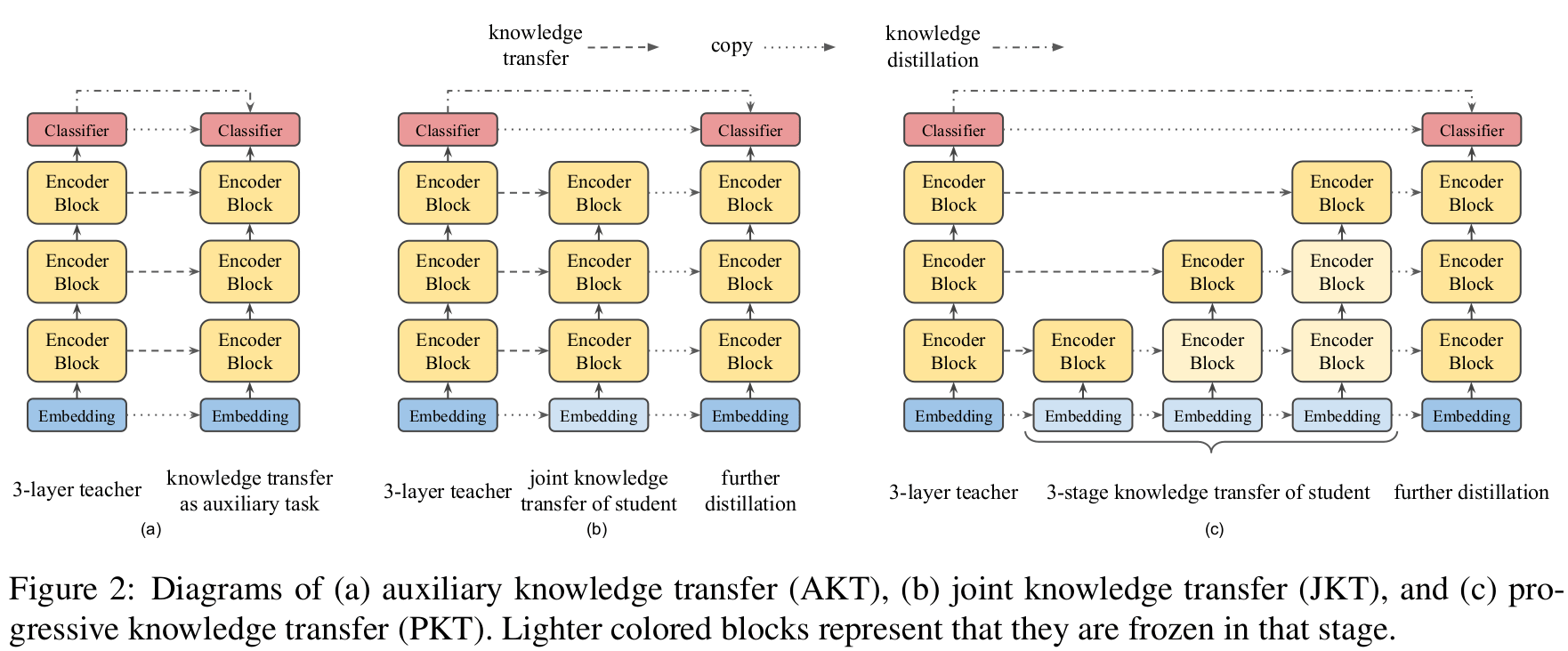
可以通过先优化 Attention Transfer 与 Feature Map Transfer,最后在优化 pre-training distillation 来实现先蒸馏主体,最后蒸馏输出层的效果。也可以做到分层蒸馏。
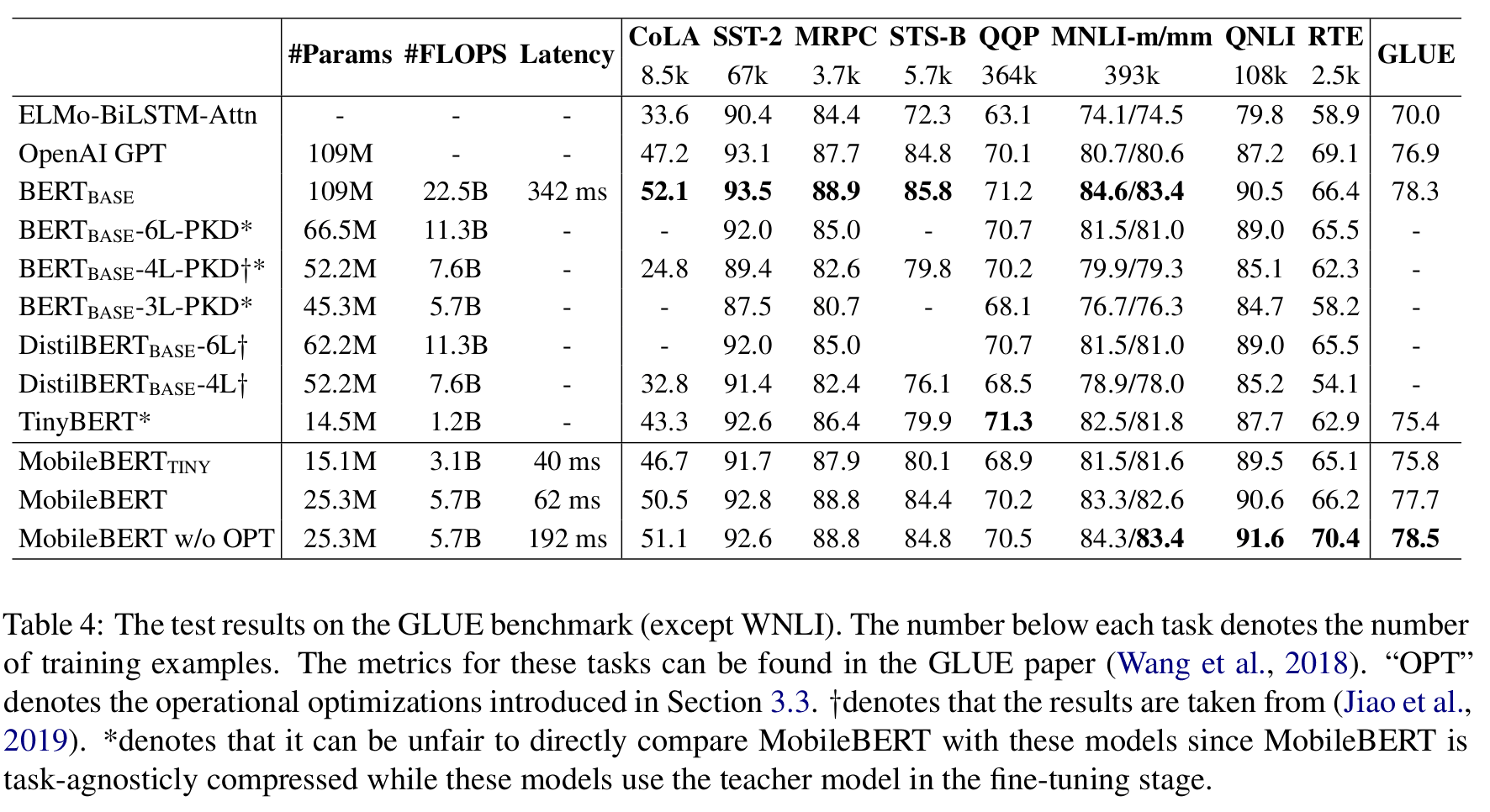
其中 OPT 表示:使用 relu 代替 gelu,移除 layer Norm。这不优化比优化了效果还好,但是花的时间也更多了。
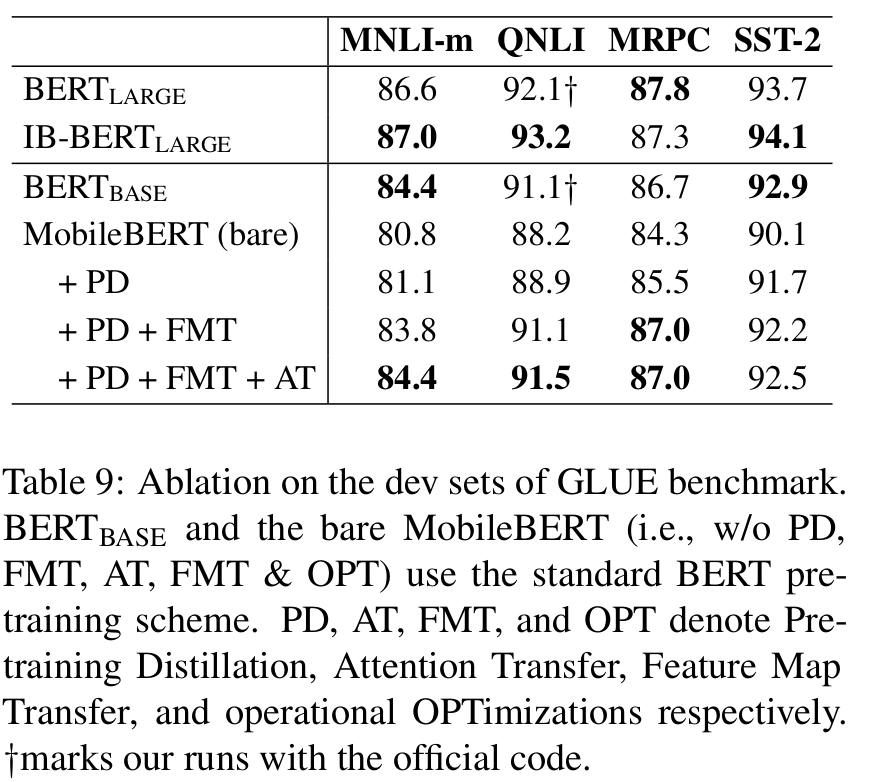
从蒸馏损失消融实验结果可以看出 FMT 带来的提升最大。
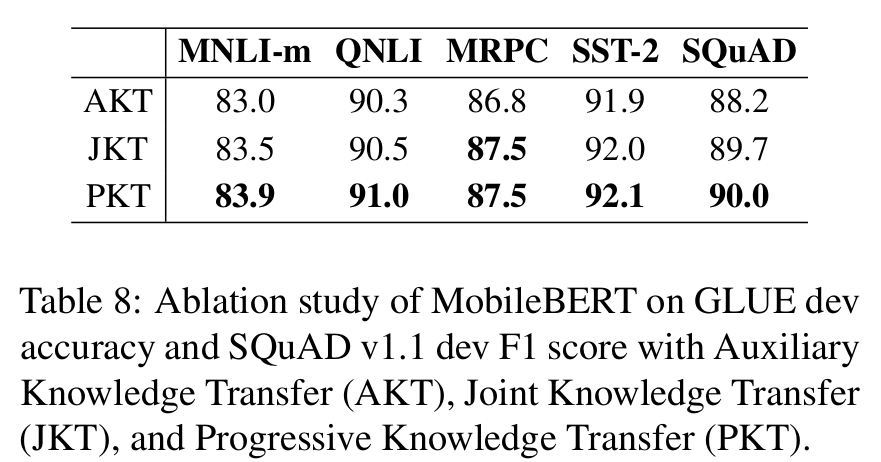
对于训练方法,果然是逐层蒸馏效果最好。
MINILM
Value-Relation Transfer 与助教机制
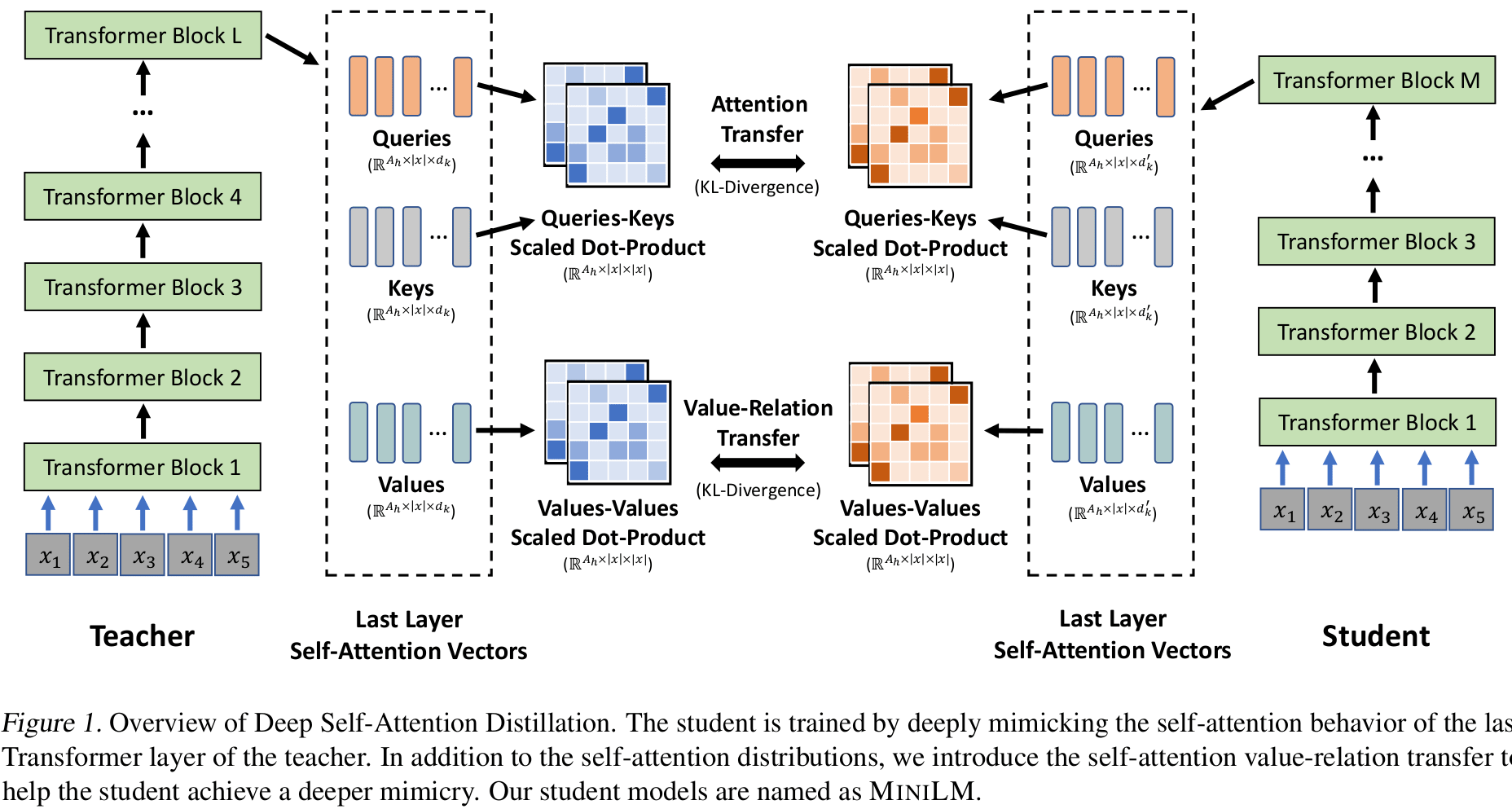
论文提出,我们需要对 transformer 模块进行深入蒸馏。MINILM 对模型层数,模型维度都没有要求,也不需要教师模型与学生模型之间的层层对应。
如上图所示,蒸馏注意力时,除了将 query 和 keys 生成的注意力矩阵 KL 散度 用来蒸馏之外,我们加入 Value-Relation Transfer,将教师与学生 value 矩阵的 KL 散度作为额外损失:
其中, 分别是教师与学生的一个注意力头中的 Value 矩阵。因此,总体的蒸馏目标为: 。
并且在蒸馏时,我们只针对最后一个 transformer 层进行蒸馏。(实验效果说明这杨作比层层蒸馏更好。可能是学生与教师模型不匹配,层层对应可能导致学生死板?只学到部分教师的知识。)

(图:与其他蒸馏模型对比)
针对教师模型与学生模型结构十分不匹配的情况(层数与维度都缩小了一半以上),可以引入一个与层数与教师相同,维度与学生相同的助教模型,实现教师蒸馏助教,助教蒸馏学生的操作。从下图可以看出,有 TA 效果会更好一点。(非常奇怪,不应该老师直接教的更好吗?)
蒸馏知识与技巧
这部分完全引用于网友的分享,毕竟个人蒸馏经验不是很多,总结过来先。
引用与BERT 模型蒸馏完全指南(原理/技巧/代码) ,模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
选择哪种蒸馏方案?
预训练蒸馏的数据比较充分,可以参考 MiniLM、MobileBERT 或者 TinyBERT 那样进行剪层+维度缩减。
对于针对某项任务、只想蒸馏精调后 BERT 的情况,则推荐进行剪层,同时利用教师模型的层对学生模型进行初始化。
用什么蒸馏目标函数?
(引用图)
使用 finetune 任务自身的 loss 是有效的,但是效果不大,大概能够提升 0.2 个百分点。
使用 attention output 输出 logits 的 mse 效果甚微,基本没有太大提升。我推测可能是当前对于序列标注任务来说,attention 的学习提升不大。建议使用更多不同的任务来实验。
使用 hidden output 输出 logits 的 mse 是 非常有效 的,能够提升 1 个百分点。
使用概率输出做蒸馏和使用 logits 输出做蒸馏差距不大,并不能看到显著的区别,建议用更多不同的任务来实验。
超参 T 和的设置
超参 用来控制各个蒸馏目标的权重。
超参 越大越能学到 teacher 模型的泛化信息。一部分文章发现 T=1 时候效果最好,大部分文章与 1-20 之间调 T。
蒸馏方式
逐层蒸馏可以提高一些成绩,但是花费还是很大的。
助教机制似乎有效
miniLM 发现的,论文中它的最终目标是将模型裁剪到 4 层,hidden_size 裁剪一半。实际操作时,它并非直接使用蒸馏训练一个最小模型,而是先用原始模型蒸馏一个中介模型,其层数为 4 层,但是 hidden_size 不变,然后使用这个中介模型作为 teacher 模型来蒸馏得到最终的模型。我尝试了这种方式,发现有一定的效果,为了蒸馏得到 4 层的模型,我先将原始模型蒸馏到 6 层,然后再蒸馏到 4 层。这种方式比直接蒸馏小模型能够有 3-4 个百分点的提升。 当然,我这里要说明一点,我比较的是训练相同 epoch 数下的两个模型的精度,也有可能是一步到位蒸馏小模型需要更多的训练步数才能达到收敛,并不能直接断定一步到位为训练法一定就比较差,但至少在相同的训练成本下,采用中介过渡是更有效的。 [9]
尽量沿用 teacher 模型的权重,如初始化
TextBrewer
通用知识蒸馏框架 [8],github
TextBrewer 提供了通用的蒸馏框架,使用者只需要提供一些配置与数据就可以进行简单的蒸馏。
快速开始
参考 textBrewer 官方文档 。
使用 TextBrewer 框架,我们需要:
- 一个训练好的教师模型
- 定义并初始化学生模型
- 构建
dataloader,optimizer和learning rate scheduler。 - 创建
TraningConfig和DistillationConfig,初始化distiller - 定义
adaptor和callback - 运行
distiller.train()
TextBrewer 采用的是 pytorch 的框架,前三步可以参考 pytorch 相关文档。第四步开始配置训练与蒸馏参数:
TrainConfig 源码
初始化 train_config = TrainConfig(...) 用于传递配置的训练相关参数。其中比较特殊的参数有: ckpt_frequency = 1, # 每 epoch 保存模型频率,选择模型根据 num_epoch 训练时提供,下同。 ckpt_epoch_frequency = 1, # 保存模型的 epoch 频率 ckpt_steps = None, # 模型训练根据 num_step 训练时候提供。
num_step 和 num_epoch 的训练节奏由 distiller 的参数决定。
DistillationConfig 源码
初始化 distill_config=DistillationConfig(...),用于传递配置的 temperture等蒸馏相关参数,其中包括蒸馏中间层所使用的 intermediate_matches。
intermediate_matches 例子:
intermediate_matches = [{'layer_T':10, 'layer_S':3, 'feature':'hidden', 'loss':'hidden_mse', 'weight':1, 'proj':['linear',384,768]}]
其中 layer_T:对应教师模型层数,layer_S:对应学生模型层数。后续计算蒸馏损失的过程中,代码将通过层数索引进行匹配,如模型前向传导输出全部层的隐状态 hidden_states,那么大致:
# inters_X 为储存模型前向传导的输出的字典,参考下文 adapor 部分
inter_S = inters_S[feature][layer_S] # inters_X['hidden'] 应为储存各层隐状态 tensor 的 list
inter_T = inters_T[feature][layer_T]
intermediate_loss = match_loss(inter_S, inter_T, mask=inputs_mask_S)
因此,配置 layer_S 时应该检查模型输出格式,必要时进行调整。
feature 为用来蒸馏的特征,支持:
attention形状(batch_size, num_heads, length, length)或(batch_size, length, length)hidden形状(batch_size, length, hidden_dim)
loss : 对应蒸馏时的 loss,目前支持以下 loss:
# 在官方 github 的 src/textbrewer/losses.py 文件下可以看到各种 loss 的实现
MATCH_LOSS_MAP = {'attention_mse_sum': att_mse_sum_loss,
'attention_mse': att_mse_loss,
'attention_ce_mean': att_ce_mean_loss,
'attention_ce': att_ce_loss,
'hidden_mse' : hid_mse_loss,
'cos' : cos_loss,
'pkd' : pkd_loss,
'gram' : fsp_loss,
'fsp' : fsp_loss,
'mmd' : mmd_loss,
'nst' : mmd_loss}
weight:loss 对应的加权系数。
proj 为 list 当教师模型与学生模型特征的形状不一样时提供。用来定义一个中间转换层。
proj[0](str):激活函数。linear,relu,或tanhproj[1](int):学生模型特征大小。proj[2](int):教师模型特征大小。proj[3](dict):其他参数,如learning_rate等。
初始化 distiller
distiller 通过 GeneralDistiller 定义。也可以使用 BasicDistiller 但这个不支持中间层的蒸馏。
# 样例
distiller = GeneralDistiller(train_config=train_config, # TrainConfig
distill_config=distill_config, # DistillationConfig
model_T=model_T, # 教师模型
model_S=model_S, # 学生模型
adaptor_S=simple_adaptor, # 教师模型的 adaptor 参考下文
adaptor_T=simple_adaptor)
adaptor
adaptor 用于整理模型前向传导的输出,便于 textbrewer 框架计算蒸馏的 loss。例子:
def simple_adaptor(batch, model_outputs):
return {'logits': model_outputs[2][-1], # 输出层对应 tensor
'attention': model_outputs[3], # 中间层注意力矩阵
'losses': model_outputs[1], # hard label 计算得出的 loss
'hidden': model_outputs[2]} # 中间层的 hidden state
这个基础的 adaptor 传入 batch 和 model_outputs ,并输出计算蒸馏时需要的字典。字典的内容根据用户蒸馏目标设定。蒸馏目标为:
callback
callback 在模型保存的时候会一并执行,由 TrainConfig 的 ckpt_steps 或 ckpt_epoch_frequency 和 ckpt_frequency 决定。callback 需要(只能)有 model 与 step 两个参数,例子:
def mycallback(model, step):
model.eval()
print('开始你的测试')
# callback 结束后 textbrewer 会自动执行 model.train()
执行 distiller.train() 开始蒸馏
distiller.train(optimizer,
scheduler=None,
dataloader=trainloader,
num_epochs=99999,
callback=mycallback)
distill general 大概做了什么
以下部分为 distiller.train() 代码执行逻辑总结。
def train(self, ...):
optimizer, scheduler, tqdm_disable = self.initialize_training(optimizer, scheduler_class, scheduler_args, scheduler) # 初始化,见下文
assert not (num_epochs is None and num_steps is None)
if num_steps is not None: # 通过 num_step 参数,选择根据 steps 或者 epoch 训练
self.train_with_num_steps(optimizer, scheduler, tqdm_disable, dataloader, max_grad_norm, num_steps, callback, batch_postprocessor, **args)
else:
self.train_with_num_epochs(optimizer, scheduler, tqdm_disable, dataloader, max_grad_norm, num_epochs, callback, batch_postprocessor, **args)
initialize_training(): 源码
大致做了:自动添加 project layer(教师模型与学生模型维度不对应时添加的层)对应的参数进入 optimizer;若 fp16 则进行相应配置;自动配置 distributedDataParallel;根据线程个数自动屏蔽 tqdm。
train_with_num_steps(): 源码 pytorch 训练框架相似,重点在于 loss 的计算。代码执行架构大致如下:
def train_with_num_steps(self, optimizer, scheduler, tqdm_disable, dataloader, max_grad_norm, num_steps, callback, batch_postprocessor, **args):
# ... (line 124-137 配置各种全局参数)
for step, batch in tqdm(enumerate(cycle(dataloader)),disable=tqdm_disable):
if batch_postprocessor is not None:
batch = batch_postprocessor(batch)
# `train_on_batch()` 中调用了一次模型的前向传播,同时根据模型输出计算了各项蒸馏的 loss。
total_loss, losses_dict = self.train_on_batch(batch,args)
self.write_loss(total_loss, writer_step, losses_dict)
writer_step += 1
total_loss /= self.t_config.gradient_accumulation_steps
# ... (line 147-176 scheduler,optimizer 与 callback 的相关操作)
if global_step >= total_global_steps:
logger.info("Training finished")
return
蒸馏损失的计算可以在 compute_loss() 函数可以看出(源码),整个蒸馏的 loss 由 hard label,logits 和 中间层的蒸馏损失构成。
具体计算哪些 intermediate loss 可以参考 match.py 编写中间层的映射,并传递到 d_config DistillationConfig 中的 intermediate_matches 参数。 与 也是在 DistillationConfig 中配置。
def write_loss(self, total_loss, writer_step, losses_dict=None):
if self.rank == 0:
cpu_total_loss = total_loss.cpu().item()
self.tb_writer.add_scalar('scalar/total_loss', cpu_total_loss, writer_step)
if losses_dict is not None:
for name, loss in losses_dict.items():
cpu_loss = loss.cpu().item()
self.tb_writer.add_scalar(f"scalar/{name}", cpu_loss, writer_step)
MultiTaskDistiller
蒸馏不同任务的教师模型到一个学生模型上。
MultiTeacherDistiller
蒸馏统一任务的教师模型到一个学生模型上
参考
- Hinton et al., Distilling the Knowledge in a Neural Network, 2015
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
- Patient Knowledge Distillation for BERT Model Compression
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- TinyBERT: Distilling BERT for Natural Language Understanding
- MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
- MINILM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
- TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing
- 2019,11 All The Ways You Can Compress BERT