知识图谱|实体链接 - 论文解读
刚开始接触知识抽取部分的内容,在阅读 《Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions》后对部分实体链接的框架和内容进行了梳理。
该论文从实体链接的角度出发,介绍了部分应用场景,并针对实体链接的不同计算流程总结了学者们的研究成果(2015 年前)。个人认为该文章对与刚入门知识抽取,想要构建整个任务大致框架的读者有很好的帮助。
原文链接:Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions
概要
实体链接顾名思义,将不同来源的、相同意义的实体进行匹配。如,将下图中的 Michael Jordan 匹配到原知识库中的实体上。
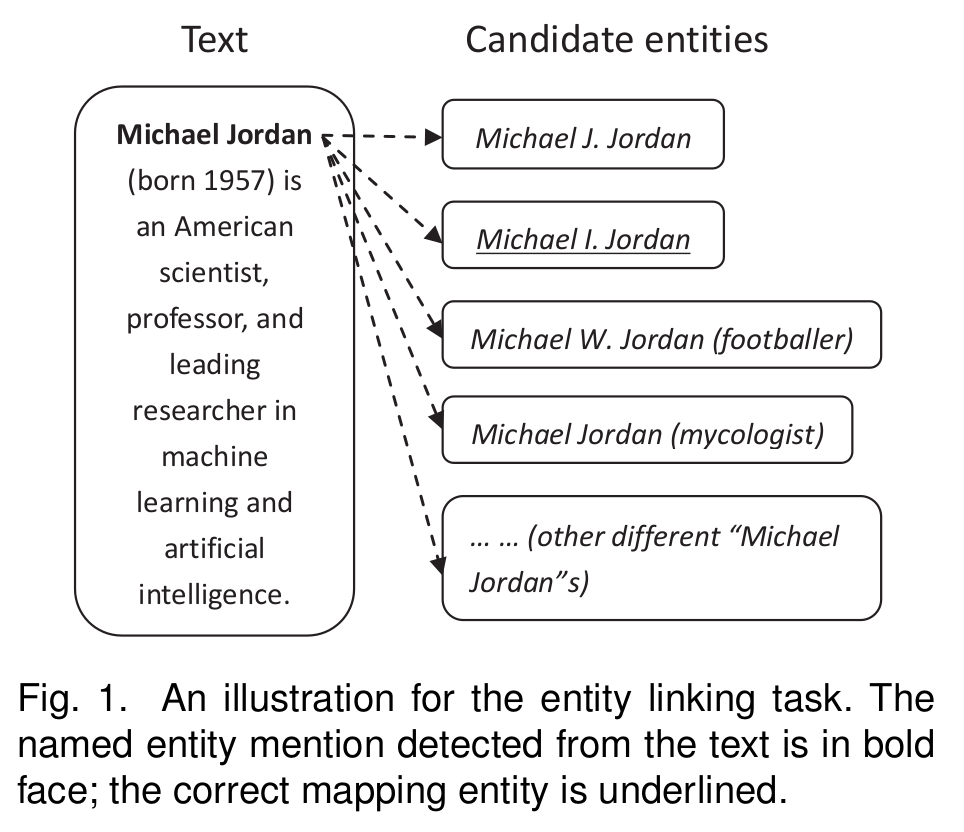
通常的,做实体链接前我们需要对命名体进行抽取(识别)。常用的英文道具有 Stanford NER,OpenNLP,LingPipe 等;中文的有 jieba, hanlp 等。也有学者使用 joint 的方式将命名体识别和实体链接两个任务合并完成。
实体链接与词义消歧挺( word sense disambiguation)的不同在于,词义消歧可以在原文本中找到完整的目标实体,而实体链接并不。
相对于记录链接(record linkage, entity matching, referenciliation),比如从京东和淘宝上面的商品链接进行匹配,将相同商品的便整合到一起。实体链接的特殊点在于它需要从非结构性的文本出发链接实体。而记录链接则可以根据结构化属性进行匹配。
为啥要进行实体链接?
实体链接 相关任务有 知识库扩充 KBP (knowledge base population), 问答 (question answering), 和信息整合 (information integration)等。
在信息抽取过程中,命名体识别得出的实体往往是模棱两可的。将这些实体与知识库进行匹配有利于今后的研究,减少不确定性。而今对数据库的检索已经从传统的检索关键字,转变为了基于实体的语义检索,以使得用户有更好的搜索体验。这样的转变需要高质量的实体链接。
将新闻中的实体与知识库进行链接能够生成更好的主题分析结果,强化推荐效果。
知识问答(KBQA)中我们需要实体链接来确定问题中的部分名词具体指代了什么。比如将问题 “怎么看苹果好不好吃?” 中的苹果一实体与苹果水果链接,以消除歧义。
最后,随着科技的发展。有许多新的实体被创造,将他们添加现有知识库的时候也需要用到实体链接。
实体链接大致步骤
生成候选实体 Candidate Entity Generation:
此步任务是从知识库中筛选出所有候选实体。
基于实体字典的方式
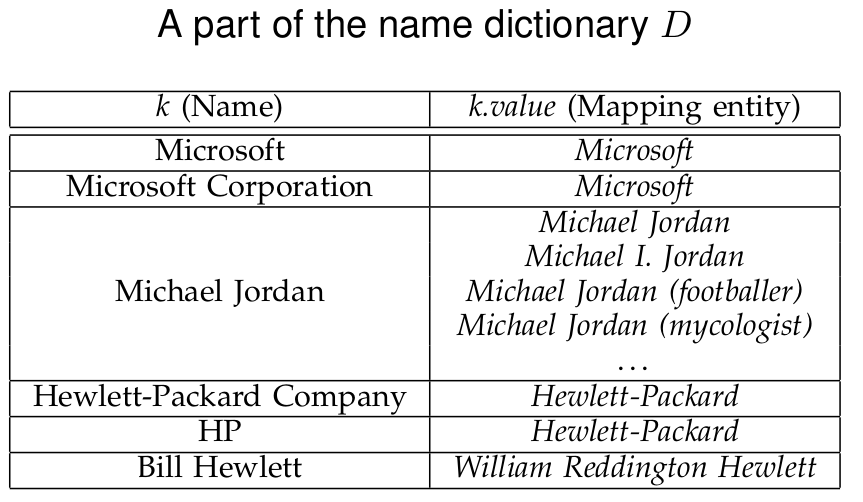
考虑创建一个实体字典,使得他的每一个键值都映射到了可能与他有关联的实体上。
以上为一个实体字典例子,以 wiki 百科这个知识库为例子。我们可以考虑这样构建他的实体字典。
将百科该词 A 上的:
- redirect page(一般为缩写,别名等)添加到字典键中,对应的值为 该词 A 。
- Disambiguation pages (一般为容易混淆的词)添加到字典中。
- 第一段加粗字体(有学者发现他们一般为 别名,全名等,与 redirect page 内容相似)添加到字典键中。
除此之外,超链接,网页的搜索记录也可以提供字典构建的信息。
在匹配实体时候,通常只需要做到部分匹配即可,这样可以提升召回率,但是会加大噪声:
- 字典 键值 k 完全覆盖了 搜索词 m 或者相反。
- 一些高频词共同出现在 k 与 m 中。
- k 与 m 之间的相似度高。相似度可以通过 character Dice score, skip bigram Dice score, Hamming distance 等计算。
除此之外,我们需要对输入词的拼写进行检测,部分学者有使用 Google 的搜索引擎拼写纠正功能。
通过本地文本集来对实体词进行扩充
很多时候我们要搜索的实体词都是缩写,简写。学者们提出可以使用启发式的办法,在出现被检索词的文章中进行检索。若相关文章中的某些词涵盖了被检索词。则可以将他们考虑为被检索词的全称。也可以使用 NER 判断这些词是否是实体。
对于部分无法匹配的词组如,采用首字母开头作为缩写的单词。可以考虑使用规则或者监督学习来匹配他们。
候选词排名 Candidate Entity Ranking
实体链接中使用的词特征
词特征(feature)可用来给候选词排序,主要的词特征分为两类:
不考虑上下文含义的单词特征 Context-Independent Features
- 单词之间的字符差异特征 :常用的算法有 edit distance , Dice coefficient score , character Dice, skip bigram Dice, and left and right Hamming distance scores;
- 候选单词本身的流行程度(Entity Popularity) :Ji and Grishman [2] 通过实验表明,仅仅通过单词在网络上的流行程度进行排名,便可以取得 71%的准确率。这也说明词语流行度十分重要。
- 单词的词性,自身特征 :如他属于人名、地名、组织名等。
考虑上下文的特征 Context-Dependent Features
- 使用 bag of word,concept vector(通过标签,关键词等组成的向量) 等算法提取候选词所在文本的特征向量;
- 单词主题相似度(topical coherence)部分学者使用 Wikipedia Link-based Measure;
假设两个实体 ,链接到他们的文章集合分别为 。 为知识库中所有文章的集合。那么他们之间的主题相似度可以有下面几种定义方式:
- 其他相似度(Coherence)的计算方法具体可以参考论文 [1]
没有什么特征是绝对的好的,应全方面考虑特征的计算方式,包括计算复杂度等。
基于特征矩阵,可以使用 dot-product, cosine similarity, Dice coefficient, word overlap, KL divergence, n-gram based measure, 或 Jaccard similarity 来计算相似度。Hoffart etal. 提出了 KORE 来解决长尾分布或者新词频率较低的问题。
监督学习的方法 Supervised ranking methods
二分类法 Binary Classification Methods
我们可以将要匹配的词组 与所有候选词组 组合成,对于每个输入 ,当 与 匹配正确时(即他们所指代的实体一致),这个输入对应的输出定为 1,反之为 0。
缺点是训练样本极度不平衡,并且当模型输出多个 1 的时候。我们还需要用其他手段来选出最好的匹配结果。
排名学习 Learning to Rank Methods
不同于二分类法,排名学习的训练集中,候选单词 都会按照与 的关联度进行排序标记。
基于概率的方法 Probabilistic Methods
Graph Based Approaches
Model Combination
训练数据的生成
部分的模型使用 Wiki 的超链接来构建训练集,但 Wiki 的训练集并不能涵盖所有领域,并且上面的数据是有限的(对于某些领域的资料而言)。有学者提出可以修改只出现一个实体的文本,将其中的实体替换为一个较为模糊的表达方式来增加训练集的数量。
非监督学习的方法 Unsupervised Ranking Methods
向量空间模型 VSM Based Methods
首先通过 bag of words 或者单词的特征属性构造他们各自的向量表示。而后计算他们之间的相似度,选取相似度最高的进行匹配。
信息检索模型 Information Retrieval Based Methods
UNLINKABLE MENTION PREDICTION
现实中,我们要匹配的单词可能并不在知识库里。部分学者采用了一下几种方式来判断一个单词是否是不可匹配的单词:
- 当我们对该词进行 候选实体生成(Candidate Entity Generation)后,返回结果为空集时。
- 当我们在 候选词排名 (Candidate Entity Ranking)中,计算得出的候选词相似度得分 中的最大值小于某个临界值时。
- 采用监督学习的方式,对排名顶端的候选词进行二分类预测(这些词是否是正确的匹配词)。
- 将 NIL (表示不可预测)加入到知识库中,如果模型输出 NIL 对应的得分最高,那么则考虑率该词为不可匹配单词。
模型测评 EVALUATION
评价指标
一般采用 Precision, Recall, F1, Accuracy。
参考
- Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions
- H. Ji and R. Grishman, “Knowledge base population: successful approaches and challenges,” in ACL, 2011, pp. 1148–1158.