ERNIE-layout 笔记
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
模型架构
总结:Ernie-layout 整体采用 Transformer Encoder 架构,特点在于:
- 借鉴了 DeBERTa 的解耦注意力,依靠额外的 Layout-Parser 来设计 position_ids。
- 同时对文档图片及文档中的文字进行编码,并设计了 4 种图文结合的预训练方式。
- 需要依靠额外的 OCR 工具来获得图片中的文字内容,及其对应位置信息。
Embedding
Embedding 的输入包括文本的token_ids,文本内容对应的 bounding box(包含 x1, x2,y1,y2,h,w),图片以及图片对应的 bounding box。
其中 bounding box 的数值被转换到 0-1000 范围。而后通过一个 Embedding 来分别计算得到对应的 x1_embedding, x2_embedding, y1_embedding 等等 6 个 embeddings。
文字 Embedding
embeddings = (input_embedings + position_embeddings + x1 + y1 + x2 +
y2 + h + w + token_type_embeddings)
embeddings = self.layer_norm(embeddings)
text_embeddings = self.dropout(embeddings)
其中采用可学习的 position_embeddings 。position_ids 通过 OCR 工具获得。
采用 [Layout-Parser](https://github.com/Layout-Parser/ layout-parser) 对图片中的文本内容,根据阅读顺序进行排序,安排对应的 position_ids。
图像 Embedding
图片被转换成 224* 224 的格式,而后通过 backbone 分割成了 7*7 个 patch。
x = self.visual(image)
# x [batch, 49, 256]
visual_embeddings = self.visual_act_fn(
self.visual_proj(x)
# batch, 49, hidden_size
与文本 Embedding 相同,visual_embeddings 加上 position_embeddings, token_type_embeddigns, bbox_embeddigns 等,得到最终图像 embedding。
Encoder
Transformer Encoder,但采用了基于相对位置编码的注意力机制。
同 DeBERTa 的解耦注意力,对相对位置信息进行截断:
而后计算 内容-内容, 内容-1D 位置信息, 内容-2D 位置信息 对应的 attention 权重:
尽管论文中提到计算注意力权重的 scaler_factor 更换为 :
一些疑问
论文中的该 scaler_factor 与 DeBERTa 相同,为 。
对于 DeBERTa ,个人猜测 是为了保持 self-attention 前后张量方差相同,DeBARTa 的相对位置注意力计算方式为:
此处对 除以 ,个人猜测是由于作者假设 式中 几乎相互独立,若 方差为 1,期望为 0,则 各自方差为 ,要保持输出方差为 1 的话,则需要对 除以 ,hugging face 上的 DeBERTa 代码 scale_factor = 1 + len(self.pos_att_type) 也与该猜想符合,其中 self.pos_att_type=['p2c','c2p] 。
对于 Ernie-Layout,可能假设 1D 位置编码与 2D 位置编码相关系较大,因此 scaler_factor 仍为 ?不过超参这种事情也挺玄学的,在 Ernie-layout 源码中,scaler_factor 依旧与传统的 self-attention 相同,为 。
Decoder
训练方式
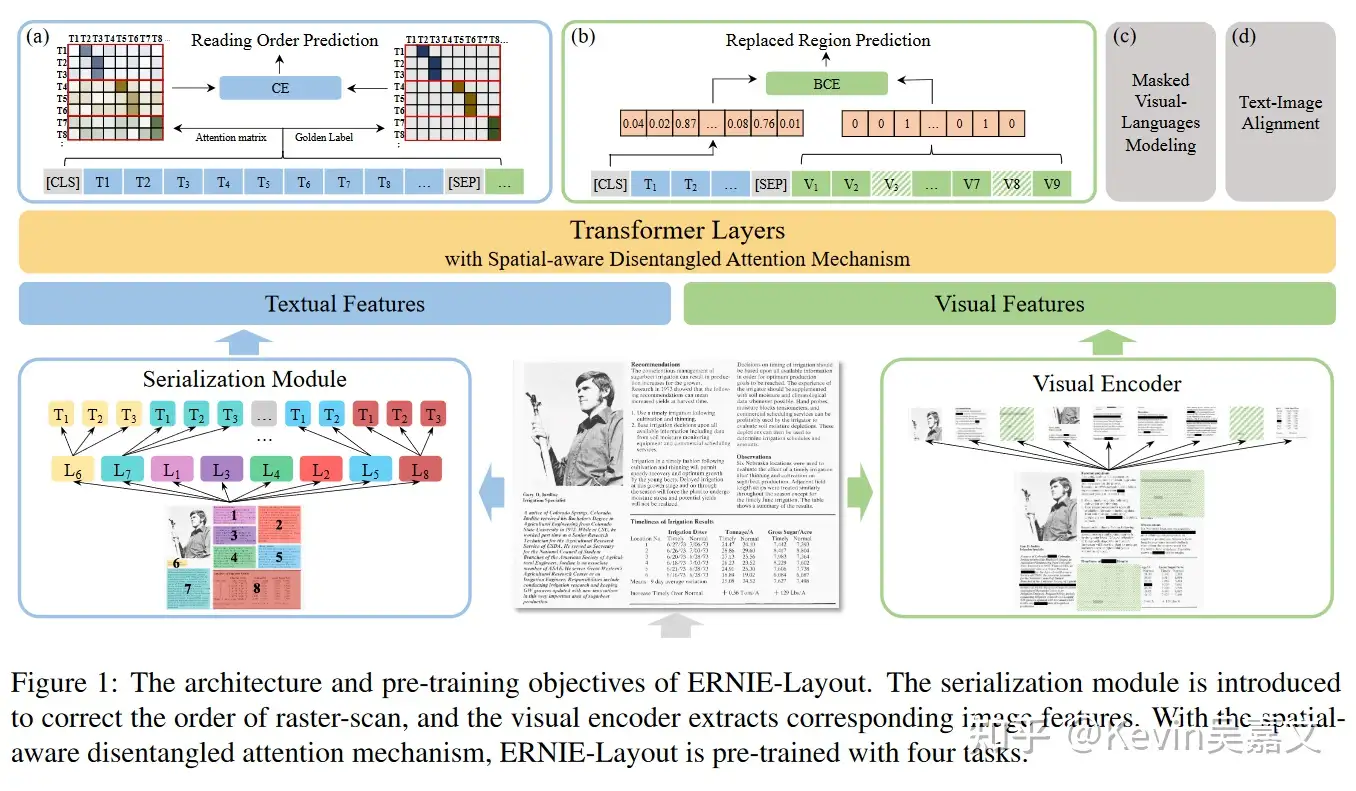
预训练
- Reading Order Prediction: 对文字部分,判断 token 之间的先后阅读顺序。可以通过阅读顺序构建一个包含 01 的邻接矩阵,而后与 attention matrix 计算交叉熵。
- Replaced Region Prediction: 对于图片部分,有 10% 的概率替换图片 patch,通过 cls 位置的编码判断哪些 patch 被替换了
- Masked Visual-Language Modeling :类似 MLM,只是这次我们可以用图片部分的 embedding 信息来预测被遮盖的文字内容。
- Text-Image Alignment :随意覆盖几行文字,然后用一个线性层进行分类任务,判断文字是否被覆盖住了。
使用案例
关于 taskflow 使用案例
Ernie-layout 可以加上不同解码层来实现不同任务效果,参考 paddlenlp 提供的 文档。比如可以进行简单的 DocVAQ:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
>>> pprint(docprompt([{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}]))
[{'prompt': '五百丁本次想要担任的是什么职位?',
'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},
{'prompt': '五百丁是在哪里上的大学?',
'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},
{'prompt': '大学学的是什么专业?',
'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]
该 taskflow 模型主要步骤:
- 使用 paddleocr 提取文字及对应的 bounding box 。
- 将用户 query (prompt) 与输入拼接,而后通过
ernie-layout编码,得到seq_logits,形状为[batch_size, len_text_tokens, 3] - 解码 BIO 标注(使用 viterbi 算法)。
心得
尽管部分文档抽取的问题可以通过 OCR + 规则很好解决,如文档字段不规范,目标文案跨行等,但对于文档样式不统一等问题, ERNIE-LAYOUT 可以是一种不错的尝试。整体系统依赖于 PaddleOCR 的抽取结果,对于内容遮盖、文字弯曲等问题的解决能力并没有提升。