图网络模型(二)
谈谈这些 GCN 模型 - NRI、RGCN
读论文总是枯燥且难熬呢,于是便尝试在阅读时便对论文进行了知识点的梳理与记录,希望有助于加深理解与记忆。希望这份笔记也能提供一些小小的帮助
本文总结的模型为 NRI(Neural Relational Inference for Interacting Systems)、RGCN(Modeling Relational Data with Graph Convolutional Networks)。
NRI
NRI 出自论文:Neural Relational Inference for Interacting Systems。在有向图与无向图都可以使用。
背景
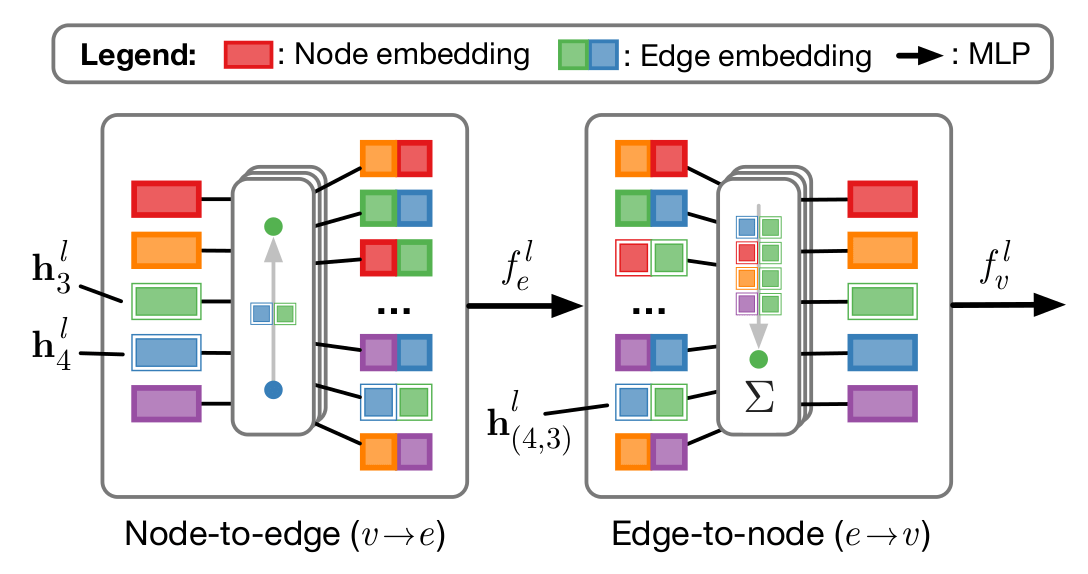
(图:GNN 点之间的前向传播)
首先讨论一下 GNN,传统的 GNN 可以定义为以下节点到节点的传播
其中 [·,·] 为拼接操作, 分别表示节点 与节点 的特征表示。而 表示在传递过程中发生了改变的节点特征。
NRI 架构
首先定义:
- 节点在时间步 的特征向量为:
- 节点 i 的特征向量由 T 个时间步组成:
- 边类型 (discrete edge type), 为点 之间的边属性。
对于 ,可以将他理解为 LDA 中的隐藏主题。即代表了连个节点之间的复杂关系,如节点 代表了 A,B 两个人,他们之间的隐藏关系可能是情侣,同桌,舍友。此时隐变量 便可以代表对应关系的概率。
优化目标
NRI 采用了 VAE,优化对象为 ELBO:
Encoder
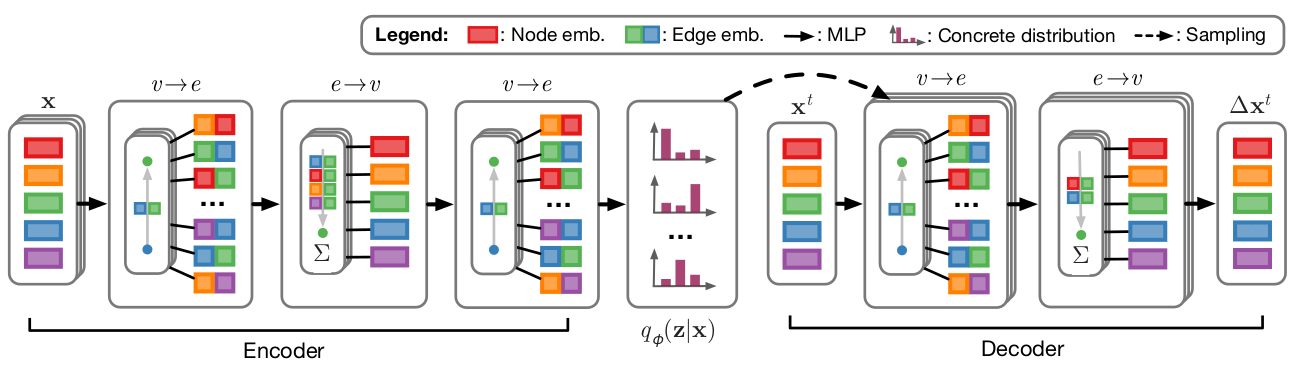
(图:NRI 框架图)
NRI 的 encoder 操作与 GNN 类似,不过它由三层 MLP 构成,大致思想是:首先通过 1,2 步进行节点信息的更新。而后使用更新后的节点信息输出边信息求隐变量 z。
经过以上编码器后可以求得 edge type posterior:
Sampling
由于上一步得到的 服从离散分布,因此作者从下面这个近似的连续分布中进行了采样:
其中, 是从 Gumbel(0,1) 分布中采集的随机值。 为 softmax 的 temperature。
Decoder
其中 表示向量 的第 k 个元素, 为一个固定方差。
论文中使用了两个方法来解决塌陷问题:
- 预测未来多个时间步的值
- 对每个 edge type 采用独立的 MLP。
预测未来多个时间步的值 这一步中,作者将解码层的输入 更换为 。如果我们将上述 Decoder 的传播定义为 ,则计算流程将改变为:
GRU 解码
考虑到原来 decoder 遵循的马尔科夫假设在大多数情况下不成立。作者采用了 RNN 结构进行解码,使用的单元为 GRU。具体操作如下:
实验与结果
实验采用了物理仿真数据集,这些实验系统有着简单的规律,但却能够表现出复杂的动态形式。因此模型会尝试从复杂的动态中发现隐藏的规则,如下图所示,模型对轨迹的预测效果很好。
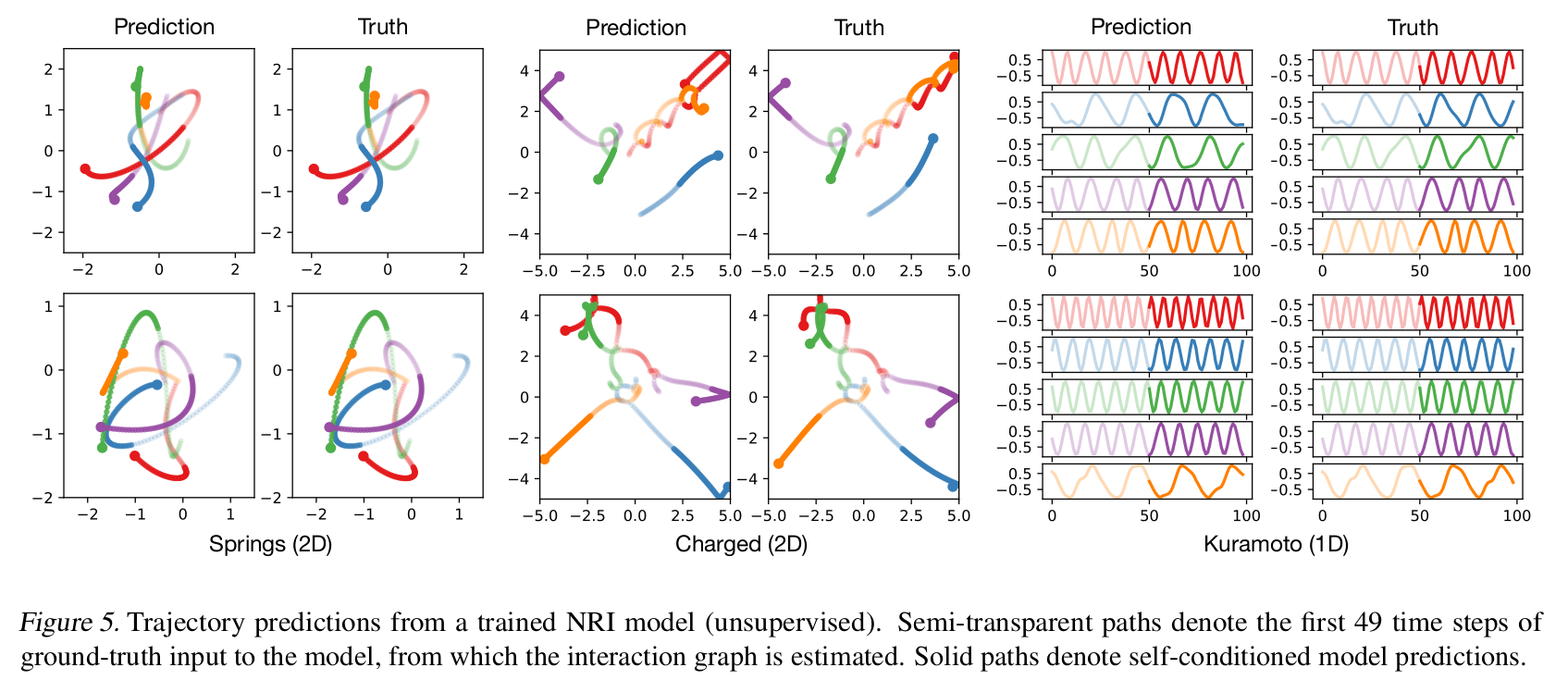
监督学习下的三个实验也都达到了 94+%的准确率。尽管数据集不是真实的,但符合物理与数学逻辑,感觉实验结果还是具有部分参考价值的。
RGCN
RGCN 出自 Modeling Relational Data with Graph Convolutional Networks ,最近在知识图谱领域用的比较多。RGCN 采用了 GCN 的思想,并将其应用在了知识图谱上,论文对 Link Predition 和 entity classification 连个任务进行了研究。
模型架构
首先,定义有向的、多重的、有标记的图(directed and labeled multi-graphs) 为,其中 为节点,有标记的边为 , 节点之间的关系类型为 。受到 GCN 的启发,论文作者在 relational (directed and labeled) multi-graph 上定义了以下前向传导方式:
其中 为归一化因子。
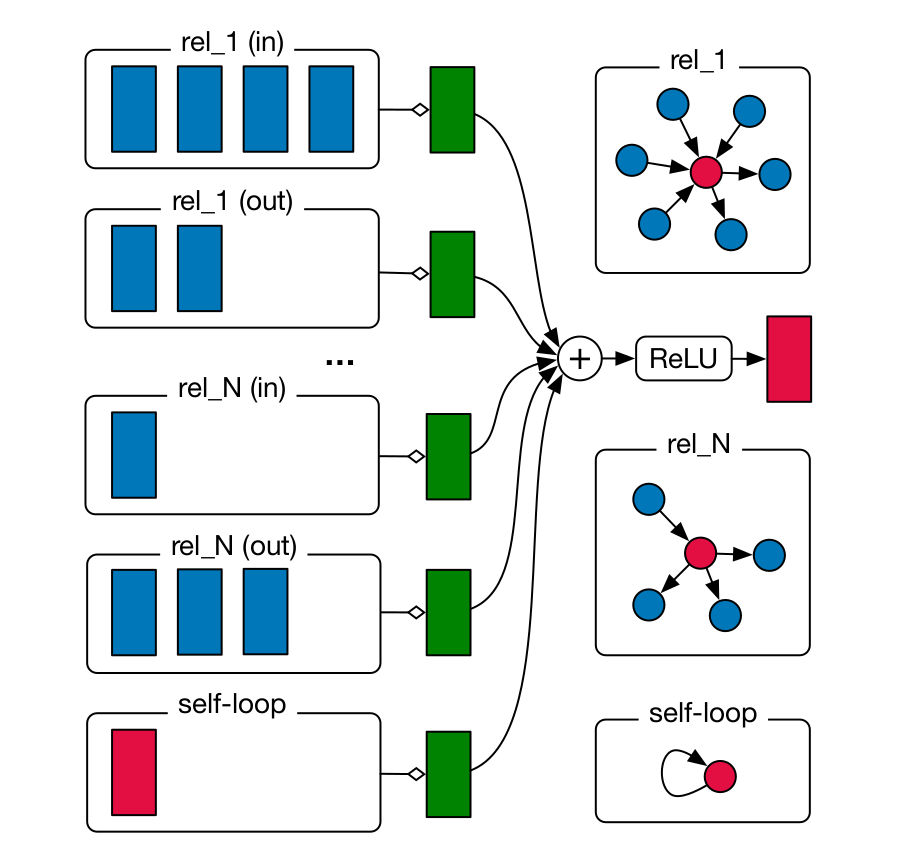
(图:R-GCN 在有向图上的前向传导)
Regularization
通过 decomposition,减小训练参数,提高训练效率,同时起到了防止过拟合的效果。R-GCN 采用了一下两种分解方式:
基础分解 basis decomposition
这种方式可以考虑成不同点间关系的权重共享。
其中 ,超参 用来调整分解的力度。通过矩阵分解,从 层到 层上的 参数数量从 减少到了 。根据论文末的节点分类讨论,B 的范围大概在 , 0 表示不使用 decomposition。
Block-diagonal decomposition
对 进行 LDU 分解,保留矩阵 D。
其中
Entity classification
节点分类预测的操作与 GCN 类似,在输出层使用 softmax 激活函数。然后训练时候最小化交叉熵损失:
其中 表示带有标记的节点, 为 ground truth。 为节点 在输出层的 hidden state。
Link Prediction
在这个任务中,作者首先将节点信息 使用 R-GCN 进行编码,得到了 。而后每两个节点和他们之间可能的关系可构成三元组 (subject, relation, object),使用解码器对这些三元组进行打分,得到两点之间的关系预测。在实验中,作者使用了 DistMult factorization[1] 作为得分方程:
其中 。在训练中采用了负采样的训练方式,优化目标为:
其中 为所有三元组的集合, 为 sigmoid 函数, 为 indicator,0 表示负样本,1 表示正样本。
实验结果
Entity Classification
作者使用了关系型数据集 AIFB, MUTAG, BGS, 和 AM 对 Entity Classification 任务进行测试。
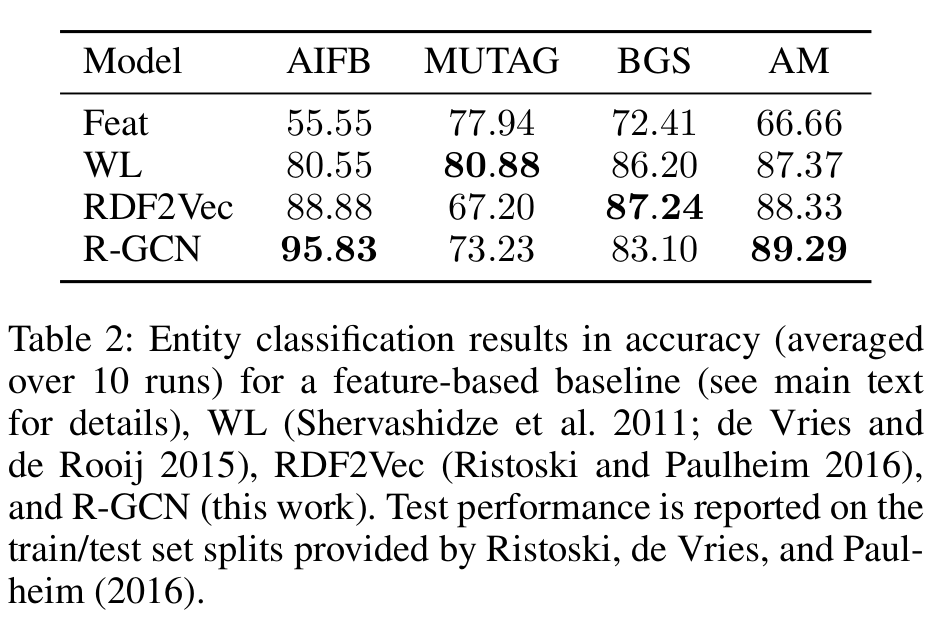
R-GCN 在 AIFB 和 AM 上都取得了 SOTA,对 MUTAG 和 BGS 的效果却没那么好。作者猜测,如果在权重计算时引入注意力机制,而非采用固定的归一化系数 ,效果应该会更好。
Link Prediction
该任务采用的数据集为 WN18,去除了 inverse triplet pairs 的 FB15K-237 和 FB15k。在训练过程中,作者对编码层采用了 edge dropout (对 self-loop 是 0.2,对其他节点是 0.4),解码层采用了 0.01 的 l2 regularization。
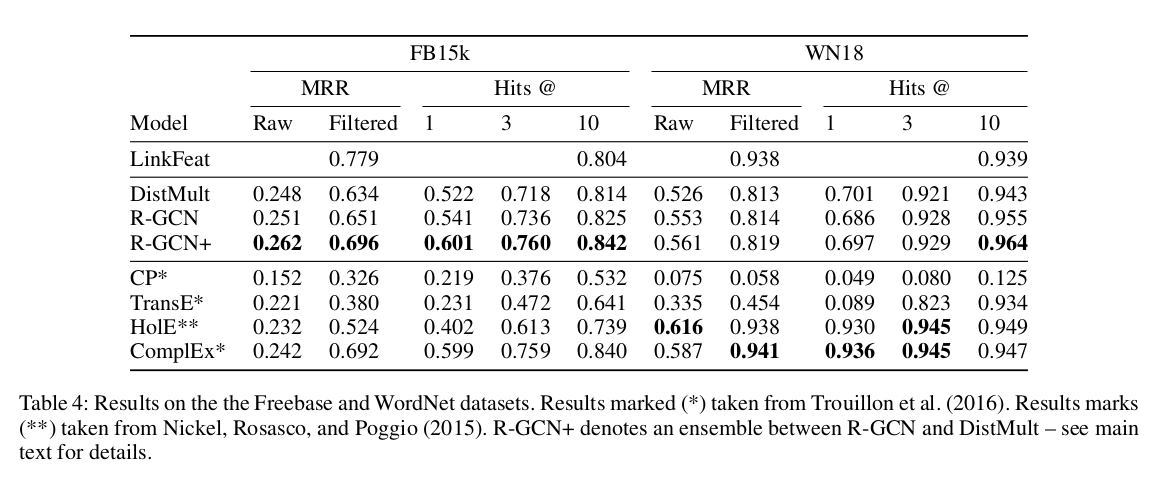
(图:FB15k, WN18 实验结果。)
其中 R-GCN+ 表示 DistMult 和 R-GCN 的 ensemble 模型。
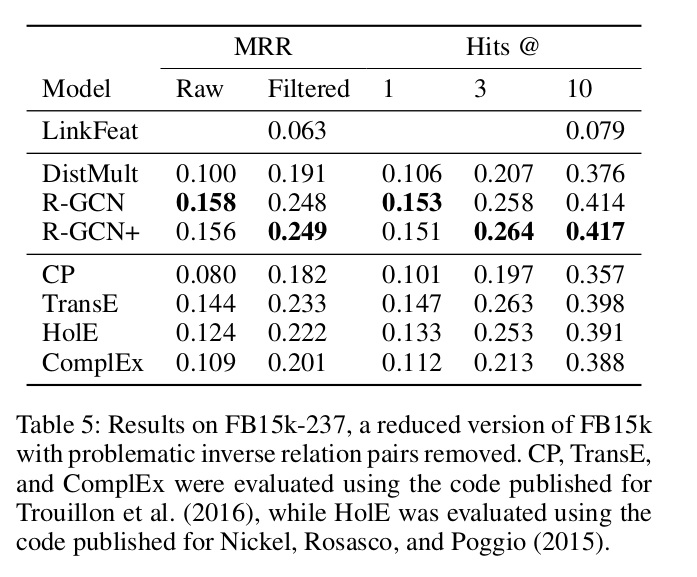
(图:FB15k-237 实验结果)
其他参考
- Yang, B.; Yih, W.-t.; He, X.; Gao, J.; and Deng, L. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575.