图网络模型(三)
纸上谈兵系列 - CompGCN、KGNN
读论文总是枯燥且难熬呢,于是便尝试在阅读时便对论文进行了知识点的梳理与记录,希望有助于加深理解与记忆。希望这份笔记也能提供一些小小的帮助
本文总结的模型为 CompGCN(Composition-Based Multi-Relational Graph Convolutional Networks)、KGNN (Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems)
CompGCN
CompGCN 来自 Composition-Based Multi-Relational Graph Convolutional Networks。它在节点更新方式上做了优化,减小了参数数量,大大降低了运算时间开销,效果也不错,但个人认为模型可解释性感觉差了那么一点。
模型架构
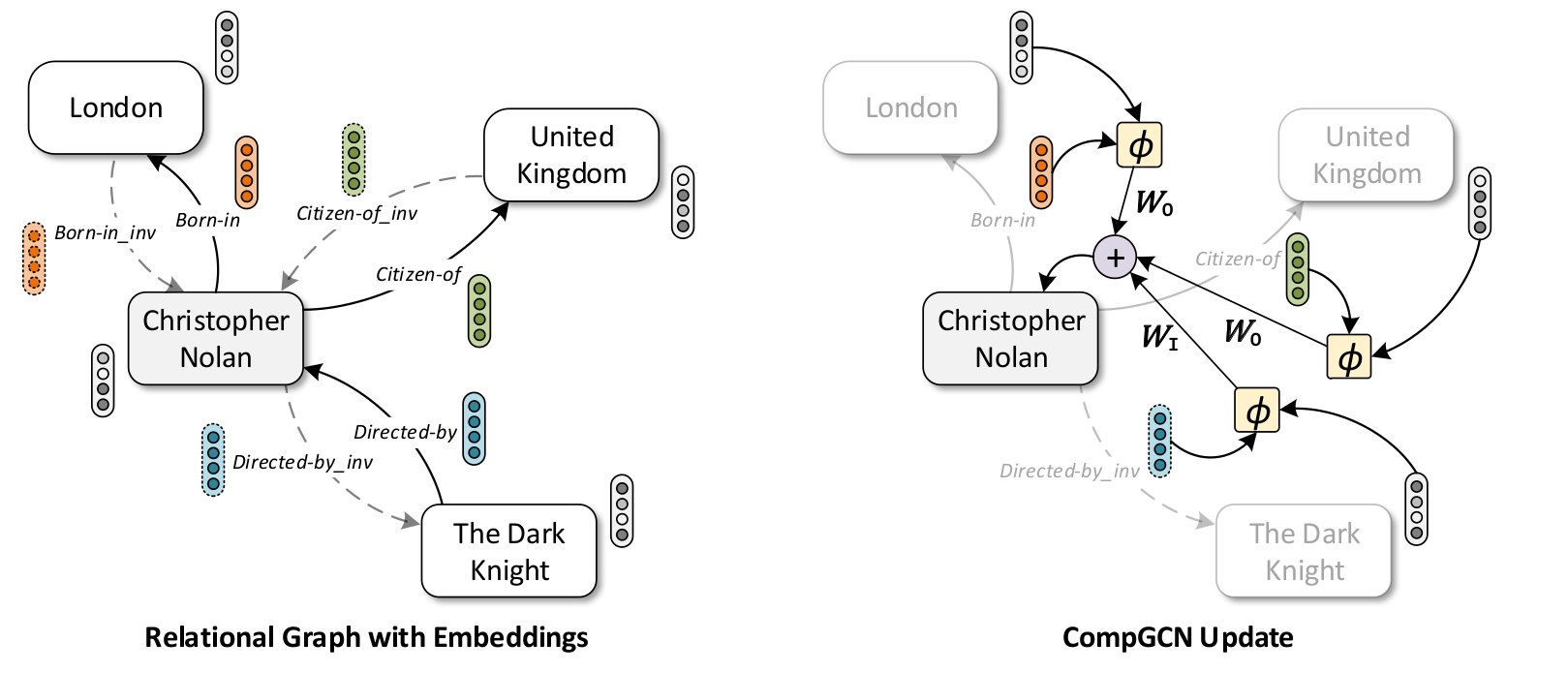
节点更新方式
RGCN (Modeling Relational Data with Graph Convolutional Networks)将 GCN 应用在了知识图谱上 GCN 对于节点 的主要更新思想为:
在 RGCN 中,隐状态 (hidden state) 代表 的邻居节点 的嵌入表示,它们被赋予初始值 并在计算过程中更新迭代。CompGCN 与 RGCN 的节点更新方式不同,首先我们定义 ,其中 为节点 与邻居节点 之间关系的嵌入表示初始值( 表示关系类型 edge relation type,每种 edge relation type 都被定义了一个单独的嵌入表示 ), 为邻居节点初始向量,隐状态 通过 来计算。
隐状态 经过 投影加总后便得到了新的点 嵌入表示。
在完成节点 更新后,对节点间关系的嵌入表示进行更新:
总结 CompGCN 的节点更新方式如下:
其中 为初始值 。
论文作者对不同的 (composition 方式)进行了测试,其中包括:
通过实验发现各个方案的表现效果取决于得分函数(score function),第二与第三种方式整体稍微好一点。
参数分解
类似 RGCN,CompGCN 论文作者也进行了参数分解。不同的是 RGCN 是对矩阵参数 分解,而 CompGCN 则对嵌入向量进行分解: ,整体的模型参数数量相对减少了:

(图:CompGCN 与不同模型的参数数量复杂度对比)
实验结果
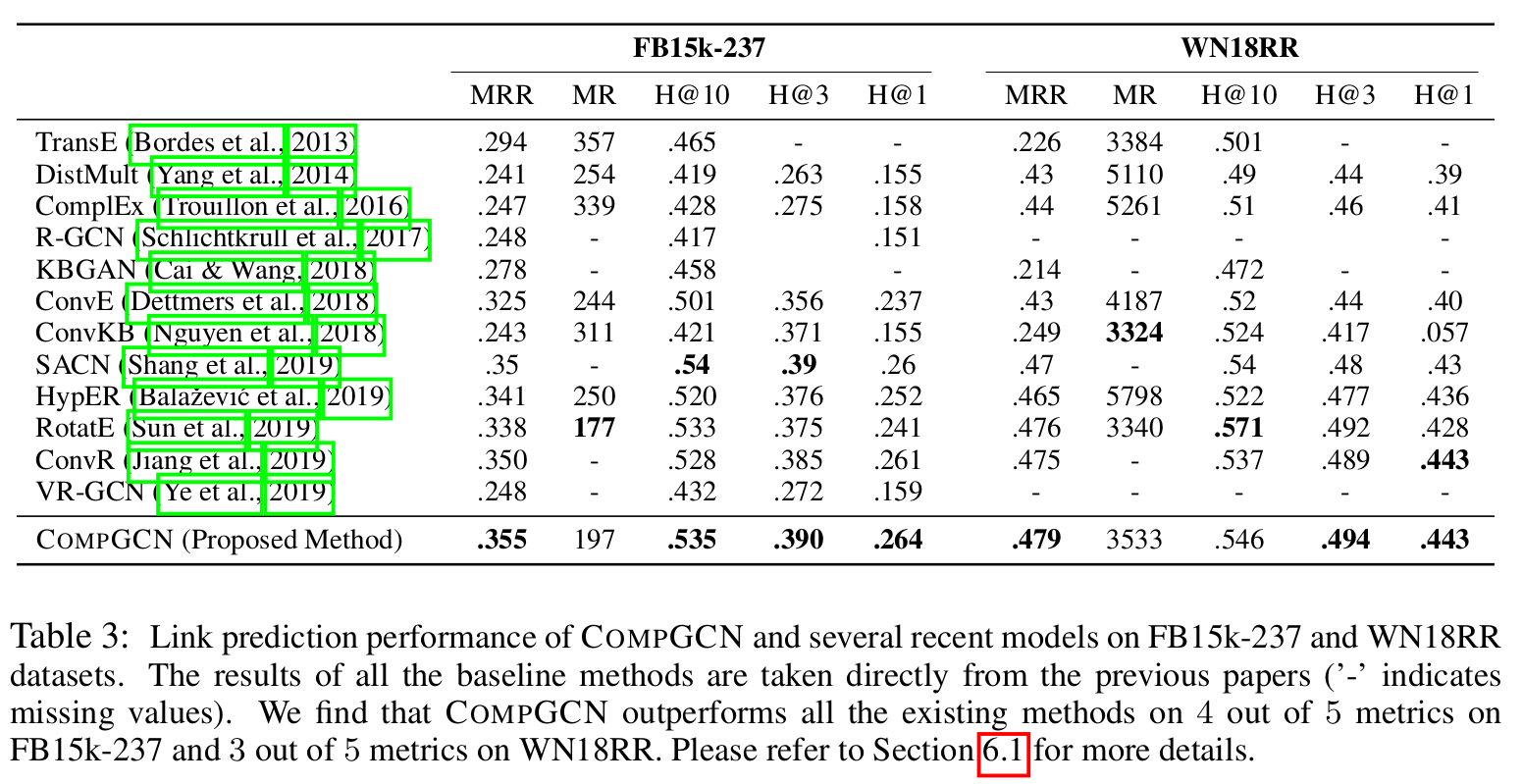
link prediction
首先 CompGCN 在 link prediction 任务上的大部分指标都超过了表中其他模型。
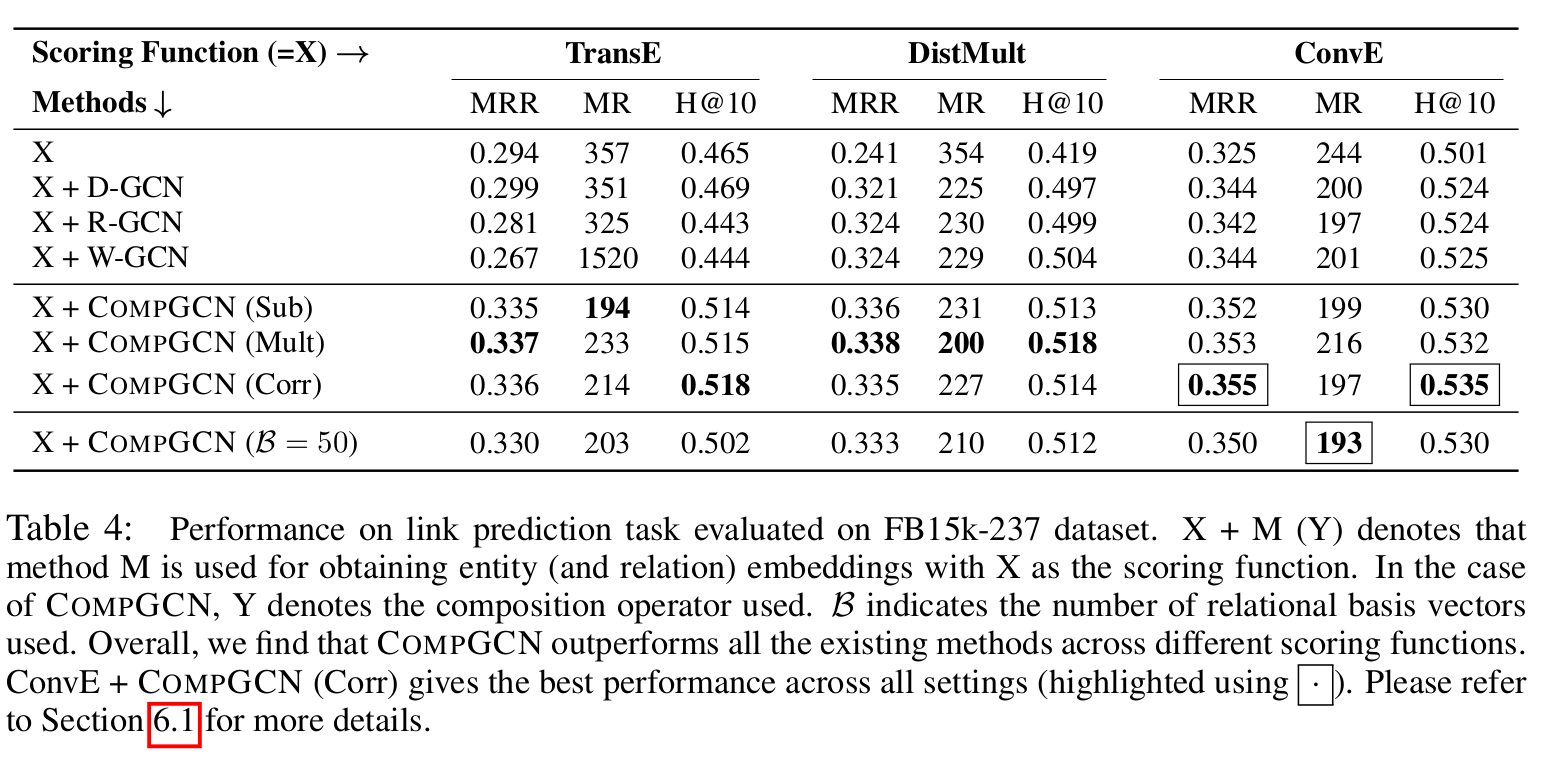
从下表中可以看出,采用了 ConvE 作为 Score function,corr 作为 函数时的表现最佳。 DistMult 配合 Mult 也不错。
Node and Graph Classification
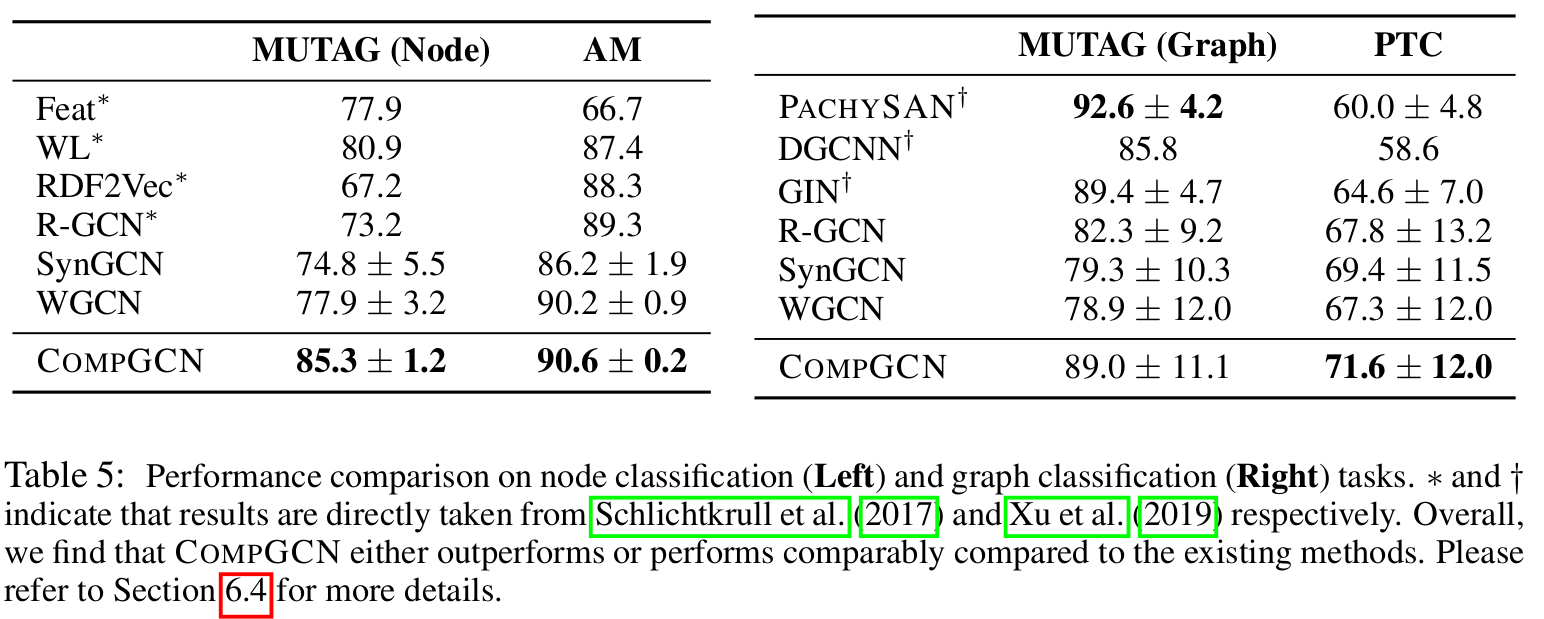
作者似乎没有建议 number of relations 和 basis vectors 两个超参如何选值。不过根据论文相关实验结果,似乎 B=50,number of relations=100 表现较为出色。
KGNN
KGNN 出自 Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems,其研究了图神经网络在基于知识图谱的推荐系统上的应用与优化。该模型主要用来发现用户可能喜欢,但之前从未接触、浏览过的商品。
首先,论文定义了:
- 用户集 ,商品集
- 由用户隐形反馈(点击,观看,购买等)构成的用户与商品的交互集 ,也就是训练时候需要用的 ground truth。
- 知识图谱: ,与大部分图谱定义相似, 代表头尾两个节点, 代表节点关系类型。
模型架构
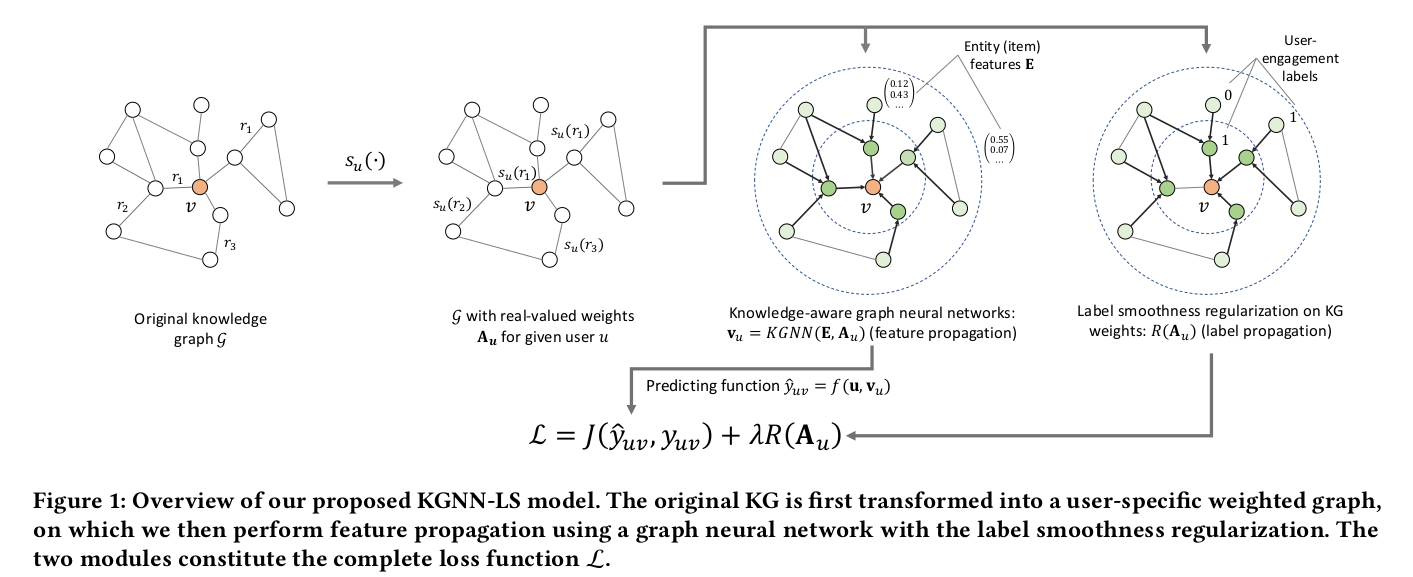
KGNN-LS 的节点的更新方式与 GCN 相似,为:
其中 为用户 “专属“ 邻接矩阵(针对不同用户,邻接矩阵不同), 由 两个节点的关系 和打分函数 决定。 为 的度矩阵。最终输出 可以理解为所有节点(商品与商品属性)对于用户 的特征表示。在预测用户 对商品 评分时使用: 。其中 ,即我们采用模型最后一层输出的 hidden state 作为节点表示进行计算 。
两个打分函数 均为可导函数,如内积。对于 甚至可以加入可学习参数,使得我们的邻接矩阵 能够更好的表现用户特点。
优化目标
在分类任务下对模型进行优化,其中 为交叉熵损失, 为 l2 正则, 为 label smoothness,与传统的标签平滑方式有点小不同,此处的 其中 为:
作者在实验中尝试了 ,发现使用 label smoothness 可以很好的提升模型效果,0.1 与 0.01 两个值效果最佳。同时作者在论文中也给出了 label smothness 的相关数学推导,以证明这样的 label smoothness 方式是有效果的,具有可解释性的。(关于这部分可以参考论文具体计算与证明)

(图:KGNN-LS 算法伪代码)
实验结果
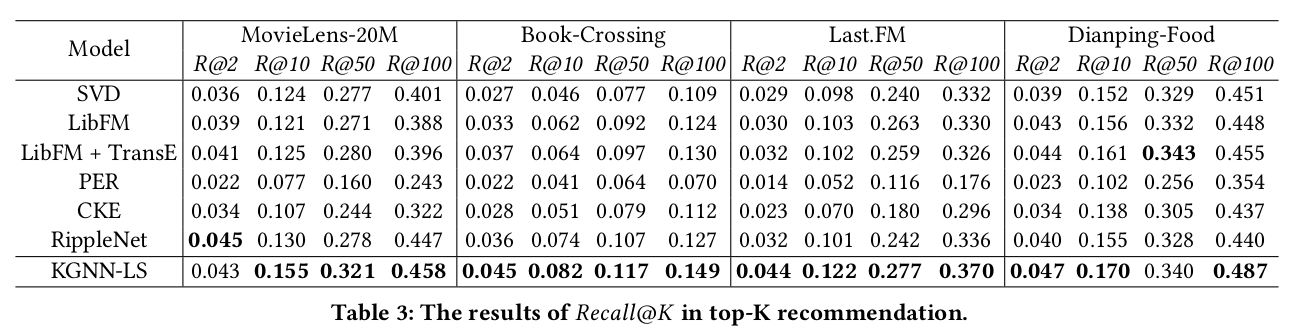
(图:KGNN-LS 基于几个推荐系统数据集的测试结果)