大数据 - Hadoop
Hadoop 笔记,中文官方文档
大数据概述
Hadoop
Hadoop 用 Java 语言实现。包括 HDFS 数据存储,YARN 资源任务调度,MapReduce 数据计算

Google 三篇相关论文启发了 Hadoop:"The Google file system", "MapReduce","bigtable" Hadoop 特点:成本低(单机成本)、扩容能力、效率高、可靠性、通用性高。 Hadoop 1.0 中只包括 MapReduce 和 HDFS;Hadoop 2.0 中新增 YARN 模块负责集群资源管理、任务调度;3.0 版本着重与性能优化。 Hadoop 集群分为 HDFS 与 YARN。如下集群,每个灰色机器上分别运行不同的进程任务,HDFS 与 YARN 间的进程互不影响。

Hadoop 部署有:单机模式(1 机器 1 进程完成)、伪分布式(1 机器多进程)、集群模式(多机器多进程)、HA 高可用(单点故障备份)。
环境准备:
源码编译,获取 hadoop-3.1.4-src.tar.gz 根据 building.txt 安装。 官方编译安装包能够在大部分平台上运行,但并不能很好地在具体平台上执行。 源码构建官方的 dockerfile 时,建议修改软件为为阿里镜像源。否则 findbugs 等软件下载会出错导致无法构建。 pip2 需要指定 pip2 install --upgrade pip==20.3.4,需要更换国内 pip 源或者设置 timeout 防止安装失败。 apt-get install net-tools vim openssh-server
快速开始:单节点学习配置
官方文档,下载 hadoop-3.3.1.tar.gz 后解压安装到 /usr/local/hadoop。 运行 sbin/start-dfs.sh 遇到 pdsh@9e434d51f056: node1: connect: Connection refused 问题,更改默认的链接方式为 ssh:export PDSH_RCMD_TYPE=ssh 浏览器登录 http://172.17.0.1:9870 可以看到管理界面

快速案例:多节点集群
集群决策规划:资源上有抢夺冲突的,尽量不要部署在一起。需要配合的,尽量部署在一起。本次案例决策:
| 主机 | 角色 |
|---|---|
| node1 | NN DN RM NM |
| node2 | SNN DN NM |
| node3 | DN NM |
安装 hadoop 前需要配置好主机之间的通讯: 1、配置主机名与网络映射 :修改/etc/hosts 2、关闭内网防火墙 sudo ufw disable 3、ssh 免密登录:重启服务service ssh restart;ssh-keygen 生成密钥对;发送公钥到目的服务器:ssh-copy-id -i id_rsa.pub kevin@node1, /etc/ssh/sshd_config 修改 ssh 配置 4、集群时间同步:install ntpdate, ntpdate ntp4.aliyun.com
hadoop 安装: 1、下载 hadoop-3.3.1.tar.gz 后解压与 /export/server,安装路径可自定义。创建数据储存路径:/export/data 2、配置 hadoop-env.sh,文档最后添加 JAVA_HOME 变量,指向 jdk1.8。 部分文档称:hadoop 3.0 后对决策权限有更严格的限制,需要设置用户执行对应 shell 命令。在 etc/hadoop-env.sh 中加入:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置上面变量的话,需要使用 root 用户开启 hadoop 服务。 3、配置core-site.xml。如果没有自定义配置,则会使用 hadoop 默认提供的配置。
<!-- 设置默认使用的文件系统 Hadoop 支持 file、HDFS、GFS、ali|Amazon 云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置 Hadoop 本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置 HDFS web UI 用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合 hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
当网页端上传文件出现权限问题时
<!-- 设置当前使用用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>kevin</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
4、配置hdfs-site.xml分布式文件
<!-- 设置 SNN 进程运行机器位置信息 -->
<property>
<!--SNN 所运行的主机--> <name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
5、配置 MapReduce:mapred-site.xml
<!-- 设置 MR 程序默认运行模式: yarn 集群模式 local 本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR 程序历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
7、yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置 yarn 历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
根据机器性能,配置资源限制,默认内存限制是 1GB 到 8GB:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
8、workers 配置从角色,配置后脚本会遍历以下机器,分别启动服务
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
9、/etc/profile 添加 HADOOP_HOME 变量
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
所有配置文件中的属性在 官方文档 左下角 configuration 栏目可查。
10、hdfs namenode -format 格式化,查看屏幕中是否有 ERROR,若没有则表示格式化成功:例部分格式化成功语句:common.Storage: Storage directory /export/data/hadoop-3.3.0/dfs/name has been successfully formatted.
注意点:
- 用户配置的数据目录及 hadoop/logs 需要对开启 hadoop 的角色有读写权限。
- format 只能进行一次,后续不再需要。多次 format 会导致 HDFS 集群主从角色之间互不识别。通过删除所有机器 hadoop.tmp.dir 目录重新 format 解决。
- 出现
the ECDSA host key for 'node1' differs from the key for the IP address '172.17.0.4'问题,删除.ssh/known_hosts文件,重新配置无密码登录
11、开启、关闭服务 在每台机器上每次手动启动关闭一个角色进程:hdfs --daemon start namenode 脚本一启动:start-dfs.sh, start-all.sh, start-yarn.sh前提是配置好机器之间的 SSH 免密登录和 workers 文件;停止使用 stop-all.sh 等。 hadoop 进程都是 java 进程,通过 jps 查看。
12、web 页面: HDFS 集群:http://node1:9870/ YARN 集群:http://node1:8088/
想用 WEB 上传文件,那么浏览器所在的计算机需要在 hosts 中配置节点 ip 到主机名的映射
HDFS 初体验:创建和上传 hadoop fs -mkdir /myfile hadoop fs -put file.txt target_dir
MapReduce + YARN 体验: 在/export/server/hadoop/share/hadoop/mapreduce下运行 hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 2 4 在 YARN web 管理界面上可以看到有刚才执行的任务记录。 mapreduce 本质是程序,执行 mapreduce 时候首先请求 yarn 申请运算资源。mapreduce 分为 map 和 reduce 两个阶段。处理小数据时候,mapreduce 速度慢。
hadoop HDFS 基准测试
确保 HDFS 和 YARN 启动成功,出现任务卡死问题时,尝试提高 yarn 内存上限。
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
企业存储系统
磁盘阵列 RAID 根据不同的需求(安全第一、容量第一),使用不同方案组合硬盘。RAID 有哪几种?有什么区别?
存储架构
DAS 存储架构(通过电揽直接链接) NAS 存储架构(通过网络拓扑结构链接) SAN 存储区域网络存储(高速的,用于存储操作的网络)
文件系统
存储和组织数据的方法,使得文件访问和查找变得容易。文件系统使用树形目录的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念 单机文件系统的文件路径不能重复,一般由根目录往下拓展文件数。文件系统通常使用硬盘和光盘这样的储存设备。
文件系统拓展 海量数据存储面临问题:
- 成本高:传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高。
- 性能低:单节点 I/O 性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景。
- 可拓展性差:无法实现快速部署和弹性扩展,动态扩容、缩容成本高,技术实现难度大。
- 难以支撑高效的计算分析。
分布式存储系统核心属性
分布式存储 - 解决存储瓶颈 元数据记录 - 解决查询便捷性 分块存储 - 解决大文件传输问题 副本机制 - 保证数据安全 抽象目录是结构 - 用户查询视角统一
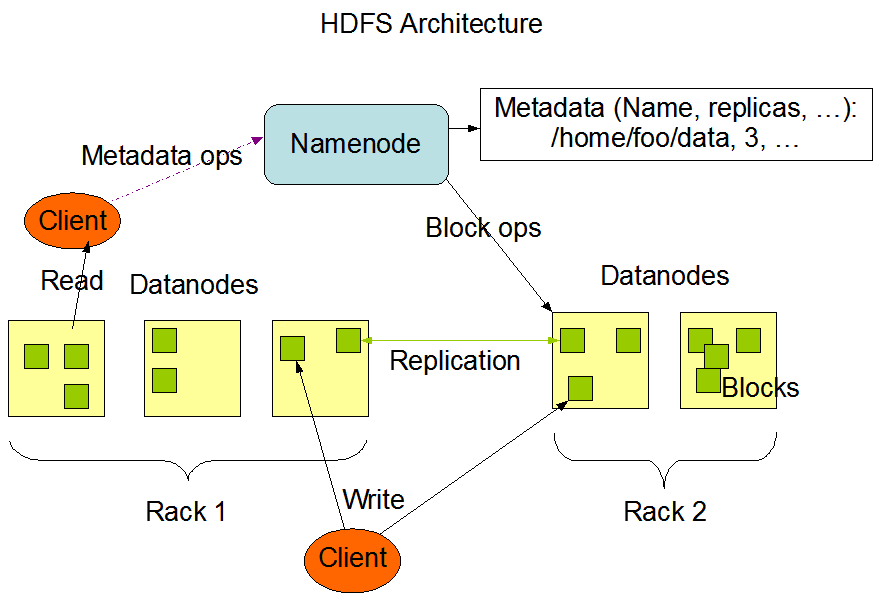
HDFS
HDFS(Hadoop Distributed File System ),Hadoop 分布式文件系统。是 Apache Hadoop 核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。 特点:高容错;分布式;统一的访问接口
根据谷歌在 2003 发布的《分布式文件系统(GFS),可用于处理海量网页的存储》Nutch 的开发人员完成了相应的开源实现 HDFS,并从 Nutch 中剥离和 MapReduce 成为独立项目 HADOOP。
HDFS 特性:
- 故障检测和自动快速恢复
- 用于批处理,注重数据访问的高吞吐量。HDFS 的设计中更多的考虑到了数据批处理,而不是用户交互处理。
- 支持大文件(Large Data Sets)存储(一般一个文件在 G-T 字节)
- write-one-read-many,一个文件一旦创建、写入、关闭之后就不需要修改。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
- 移动计算比移动数据更划算。(程序移动到数据所在地计算)
- 异构软硬件平台间的可移植性
HDFS 概述
主从架构:一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。 分块存储:HDFS 中的文件在物理上是分块存储(block),默认大小是 128M。(hdfs-default.xml 中:dfs.blocksize 配置块大小) 副本机制:文件的所有 block 都会有副本。(由参数 dfs.replication 控制,默认值是 3) 元数据记录:
- 文件自身属性信息:文件名称、权限,修改时间,文件大小,复制因子,数据块大小
- 文件块位置映射信息:记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。 抽象统一的目录树结构(namespace)
一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。 Namenode 是 HDFS 主节点,Datanode 是 HDFS 从节点。 Namenode
- 中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
datanode
- 负责管理它所在节点上的存储
其他
vim /etc/hosts
sudo apt remove --purge openssh-server -y
sudo apt install openssh-server -y
sudo service ssh start
rm ~/.ssh/knonw_hosts
重新设置 ssh 免密登录