更方便的 Training
Huggingface Training
本文参考 transformers 官方指南 link
经过几年的发展,transformers 的训练框架也变得成熟,在 bert 时代我们可能需要手写许多优化过程,当初 huggingface 快速上手中的示例代码,大部分还是类似以下的操作:
for _ in num_epochs:
optimizer.zero_grad()
loss = model(**inputs)
loss.backward()
如果要采用混合精度训练,gradient accumulate 等策略时需要手动添加。而今我们只需要配置 Trainier 和 TrainingArgument 即可:
from transformers import TrainingArguments, Trainer, logging
logging.set_verbosity_error()
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
训练超参梳理
以下对 tranformers.training_args.TrainingArguments 中,部分较使用的方法进行清点:
训练策略相关 strategy 类型
evaluation_strategy:evaluation 的方式,可选择no,step,epoch。通常我们算step或no。logging_dir:日志文件夹
关键训练配置
对于 batch size,可配置的参数有:
per_device_train_batch_size:每个设备上的 batch_size。gradient_accumulation_steps:累计 gradient 的步数,
相关信息
如你有 4 张显卡,显卡最多放入 4 个 batch,那么设置 gradient_accumulation_steps=4, per_device_train_batch_size=4 近似于全局 64 batch size 的效果,当然这也与你是否使用 batch norm,以及多卡状态下所使用的同步策略有关。
对于 learning_rate,相关参数有:
learning_rate:通常结合 batch size 进行缩放调整。lr_scheduler_type:默认采用"linear"。warmup_steps/warmup_ratio:这两者的默认值为 0, 可以参考其他 LLM 训练配置,如 alpaca 配置warmup_ratio=0.03
其他训练配置:
num_train_epochs/max_steps:训练时长,默认是num_train_epochs=3gradient_checkpointing: 是否采用 gradient checkpoint 来对显存进行优化,使用之后可以提高per_device_train_batch_sizeoptim:优化器类型,比较常用的如adamw_torchmax_grad_norm:在 clip gradient 时候采用的参数,可以防止梯度爆炸。group_by_length:将长度低的样本放到一个 batch 当中训练,这样能够尽量控制 padding 数量,提高 transformers 的训练速度。
保存模型时的部分配置:
save_steps:保存模型的周期(以 step 为单位)。如果想要通过 epoch 保存的话,需要额外调整save_strategy=epoch。save_total_limit:限制保存 checkpoint 的数量,在本地磁盘空间不够时候可以用得上。save_safetensors:是否通过 safetensors 格式保存,对于该格式,可以查看 官方指南
metric_for_best_model:默认是使用loss来判断模型好坏。
加速训练主要参数
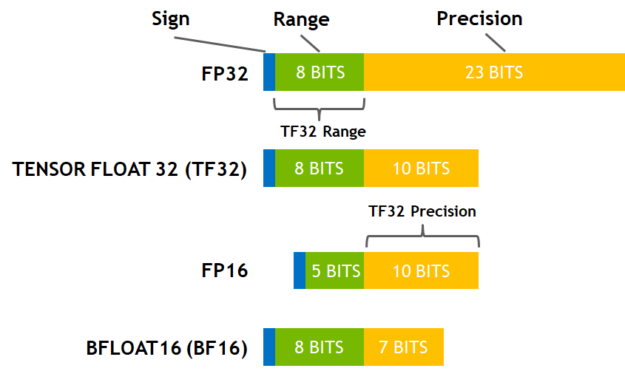
jit_mode_eval:通常,我们使用静态图进行推理时,速度会是动态图的 2 倍以上。使用jit_mode_eval能够提高 eval 时候的推理速度。fp16:是否采用混合精度训练,通过调整fp16_opt_level混合精度训练能够在减少显存占用,提高训练速度的同时,尽可能高地保留训练效果。一般在对 softmax 等 activation 层应用 fp16 后,训练时间可以缩短 2/3,但训练过程中,出现数值溢出的可能性高于 bf16 或者 tf32。bf16及tf32:这两者是 NVIDIA Ampere 架构才支持的数值格式,在 NVIDIA 博客 上可以看到详细的介绍。总结来说,部分显卡对于 bf16 以及 tf32 格式有很好的支持,相对于 fp16,有着更好的精度以及更快的速度。
完成一次训练
在代码中定义:
parser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
model = transformers.AutoModelForCausalLM.from_pretrained(xxx)
tokenizer = transformers.AutoTokenizer.from_pretrained(xxx)
trainer = Trainer(model=model, tokenizer=tokenizer, args=training_args, **data_module)
trainer.train()
trainer.save_state()
trainer.save_model(output_dir=training_args.output_dir)
在启动训练文件时,传入超参进行配置:
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--data_path ./alpaca_data.json \
--bf16 True \
--output_dir <your_output_dir> \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True