Inference-time learning (2026)
对部分 test-time compute / inference-time learning / reasoning models 的记录。
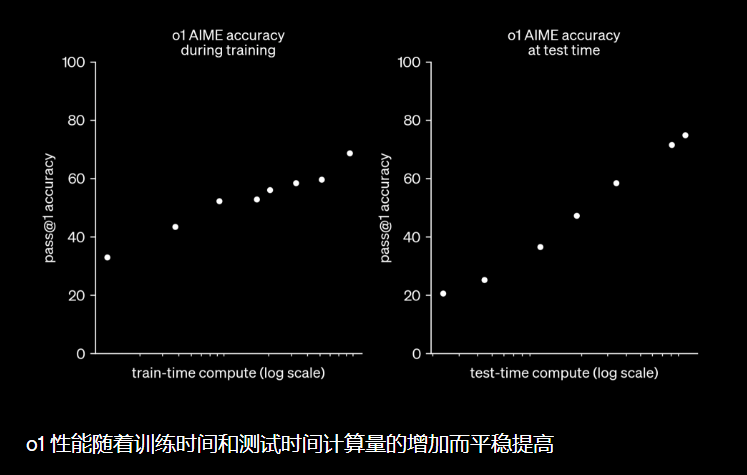
OpenAI O1
在 openai 官方发布中提到:
这里发现,随着强化学习(训练时间计算)和思考时间(测试时间计算)的增加,o1 的性能也在不断提高。这种方法的扩展限制与 LLM 预训练的限制有很大不同,这里正在继续研究。
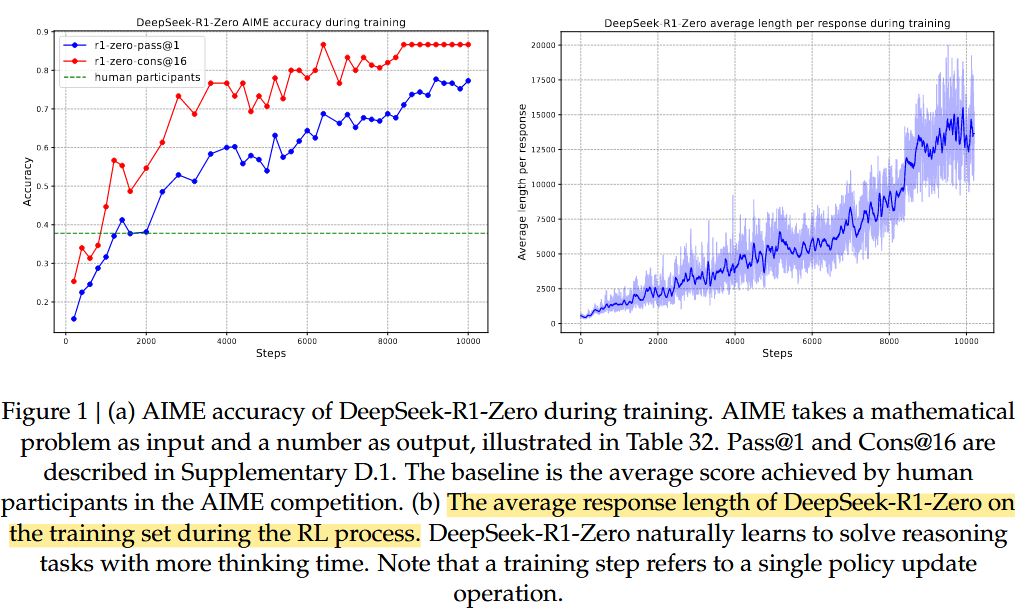
DeepSeek-R1-Zero
在 DeepSeek-R1 论文中,aha moment 并不是由单个现象证明的,而是由一组证据共同构成的。论文中可以看到几个关键趋势:
- 首先,模型在 RL 训练过程中 accuracy 明显上升,说明纯 RL 确实提升了模型在复杂推理任务上的表现。
- 其次,average response length 也随着训练增加。论文将其解释为模型学会使用更多 thinking time,也就是在回答前进行更长的搜索、验证和推导。
- 第三,论文还统计了 reflective words,例如 “wait”“check”“verify”“mistake”“wrong” 等词的频率。尤其是 “wait” 这个词,在训练后期出现了明显 spike。再结合论文中的具体样例,模型在中途说出 “Wait, wait…” 并重新评估自己的解题步骤,作者将这种行为称为 aha moment。
因此,DeepSeek-R1 论文中的 aha moment 更像是一种训练后期出现的推理行为变化:
短回答 / 普通推理
→ 更长 reasoning
→ 自我检查
→ 发现可能的问题
→ 重新评估
→ 修正推理路径
也就是说,论文中的 aha moment 不是简单地说模型出现了某个词,而是模型在 RL 过程中学会了更长、更反思式的推理策略。
Aha Moment 复现结果
1. 总结:这里到底有没有观察到 “Aha Moment”?
用 3B 和 7B 模型分别在 countdown 任务上进行 GRPO/PPO,尝试观察 aha moment
分析了训练过程中部分保存下来的 595 条 response,覆盖 step 1 到 step 139。统计了正确率、response 长度和反思词频率,也进一步观察了不同训练阶段的具体样例,尝试区分“表面反思”和“真正有效的自我修正”。
最终,结论是:
相关信息
这次实验确实观察到了 RL 让模型解题能力提升,也观察到了模型推理策略的变化;但它并没有明显复现 DeepSeek-R1 论文中那种典型的 “response length 增长 + wait 频率爆发 + 长链自我反思” 的 aha moment。 相反,这里看到的是另一种更适合 countdown 任务的策略迁移:模型从早期的长篇混乱试错,逐渐转向更短、更直接、更高效的表达式搜索。
:::
2. countdown 实验观察到了什么?
实验也观察到了明显的能力提升。从整体趋势看,模型正确率随着训练上升:
step 1–30: 8.6%
step 31–70: 53.7%
step 71–110: 64.1%
step 111–139: 68.0%
这说明 RL 训练确实让模型更会做 countdown 任务。
但是, 和 DeepSeek-R1 论文不同的是, response length 并没有随着训练增加,反而呈下降趋势。 早期模型经常输出很长的思维过程,但这些长 reasoning 大多是无效试错;后期模型的输出更短,却更容易正确。
更有意思的是,“wait” 这类反思词在实验中并不是后期出现,而是早期更多。早期模型经常说 “let me check”“try another approach”“this doesn’t work”, 但最后仍然得不到正确答案 。到了后期,这些反思语言反而减少,模型更多时候直接给出简洁的表达式。
这说明:
相关信息
在 countdown 实验里,反思词并不是 aha moment 的可靠信号。 很多时候,反思语言只是模型失败搜索时的表面语言,而不代表真正的有效修正。
3. 从具体 response 中看到的阶段变化
通过每个阶段挑选代表性 response,这里可以更清楚地看到模型策略的变化。
在早期阶段,模型虽然会尝试很多方法,也会使用 “check”“try again” 之类的语言,但它经常违反任务规则,例如引入没有给定的数字,或者最后表达式并不等于 target。这个阶段的模型看起来“想了很多”,但实际上缺少有效约束。
到了中期,模型开始出现更有序的枚举行为。它会尝试多个候选表达式,并检查它们是否等于 target。虽然这种方式仍然比较笨拙,但已经比早期的随机试错稳定很多。
再往后,模型的枚举过程变得更加规范。它开始更频繁地明确比较候选表达式和目标值,比如 “this does not equal 29”。这说明模型学会了一个重要模式:
生成候选表达式
→ 计算结果
→ 和 target 对比
→ 不对就继续搜索
到了最后阶段,模型经常能直接找到短表达式。例如:
45 + 97 - 90 = 52
这类 response 很短,但正确、合法、格式稳定。
因此,四个阶段整体呈现出这样一条路径:
长篇混乱试错
→ 有序枚举
→ target check
→ 短表达式直接搜索
这是一种清晰的策略进步,但它并不是 DeepSeek-R1 论文中那种典型的长链反思式 aha moment。
4. 为什么结果和 DeepSeek-R1 不一样?
最重要的原因可能是: 任务不同,最优策略也不同。
DeepSeek-R1 面对的是复杂数学、代码等高难度 reasoning tasks。这类任务往往需要多步推导、条件检查、反向思考和错误修正。对于这样的任务,写更长的 reasoning、进行更多 self-reflection,可能真的能提高 reward。
但 countdown 任务不一样。它本质上是一个小型表达式搜索问题。很多题可以通过较短的结构解决,例如:
a + b - c
a - b + c
a * b - c
(a + b) / c
在这种任务中,过长的 reasoning 不一定有帮助,反而可能导致模型陷入错误循环、重复数字、引入非法数字,或者格式失败。
所以,RL 在实验中没有鼓励模型“想得更长”,而是鼓励模型“搜得更准、更快、更短”。
这也解释了为什么实验中会出现:
accuracy 上升
response length 下降
wait 频率下降
direct solve / enumerative search 上升
这并不是训练失败,而是说明模型学到了一种更适合 countdown 任务的策略。
5. 一个统一解释:奖励诱导的推理策略迁移
为了同时解释 DeepSeek-R1 论文和实验结果,这里提出一个更大的理解框架:
Reward-Induced Reasoning Policy Shift 奖励诱导的推理策略迁移。
这个框架认为,RL 并不会固定地产生某一种推理行为。它不会必然让模型输出更长,也不会必然让模型说 “wait”。RL 真正做的是:在给定任务、reward 设计、base model prior 和训练约束下,推动模型寻找更容易获得 reward 的推理策略。
换句话说,模型在 RL 中学习的是:
面对这个任务,我应该如何分配我的 token?
对于复杂数学任务,最优策略可能是:
多推导
多检查
多反思
必要时重新开始
于是这里看到 DeepSeek-R1 中的 response length 增加和 wait spike。
而对于 countdown 任务,最优策略可能是:
快速生成合法表达式
检查是否等于 target
找到答案后立即停止
减少无效解释
于是这里看到本次实验中的 response length 下降和搜索效率提升。
因此,DeepSeek-R1 的 aha moment 和这里实验中的搜索效率提升并不是矛盾的。它们可以被看作同一个机制在不同任务环境下的两种表现。
6. 这里对 “aha moment” 的重新理解
经过这次实验,我认为不能把 aha moment 简单理解为:
模型说了 wait
模型输出变长
模型用了反思词
这些只是表面信号,更合理的定义应该是:
Aha moment 是 RL 训练过程中,模型解题策略发生可观察的阶段性重组。
在 DeepSeek-R1 中,这种重组表现为:
更长 reasoning
更多 self-reflection
更多重新评估
而在 countdown 实验中,这种重组表现为:
更少无效反思
更稳定的候选搜索
更明确的 target check
更短、更直接的正确表达式
因此,aha moment 不一定总是“想得更长”。在某些任务中,它也可能表现为“想得更短、更准”。
这次实验最重要的发现不是“这里复现了 DeepSeek-R1 的 aha moment”,而是:
这里观察到了另一种 RL 诱导的推理策略迁移。
DeepSeek-R1 论文中的 aha moment 表现为模型在复杂任务中扩展 thinking time,学会更长的反思式推理。
而 countdown 实验则显示,在较简单、可验证、搜索空间有限的任务中,RL 可能会推动模型压缩无效 reasoning,形成更短、更稳定、更高效的表达式搜索策略。
相关信息
Aha moment 或许不应该被狭义地理解为 “wait” 的出现或 response length 的增长。 更本质地说,它是 RL 奖励压力下模型推理策略的重组。 在不同任务中,这种重组会呈现出不同形态:有时是长链反思,有时是高效搜索。
Minimax-M1
RL 训练时候的一些指标。该结论与 DeepSeek-R1-Zero 类似,仅用 RL 就把 “inference-time thinking length” 提高了。
这三类都属于更偏 可验证任务 的 benchmark,所以它们反映出来的增长, 很大程度上确实是在观察 rule-based / verifiable reasoning 能力的提升 。但从论文上下文看,图片本身不太像是在严格声明“这里只分析 rule-based RL 阶段”,可能有包括了 GenRL。
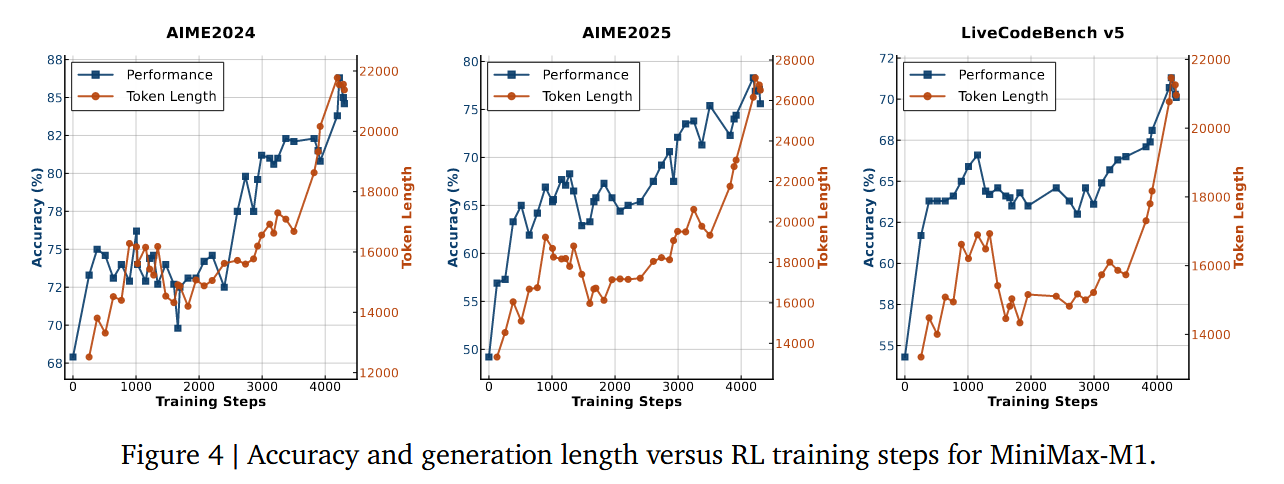
后续的 M2,M2.7 相关模型都针对 RL 部分进行了更多的处理,让 Minimax 模型在 agent coding 任务上表现更佳。
Trading Inference-Time Compute for Adversarial Robustness
待续