信息抽取小述|实体抽取、关系抽取
信息抽取即从非结构化文本信息中提取出结构化信息。本文对实体抽取、关系抽取、事件抽取等任务,整理其处理方案、论文、难点分析等。
实体抽取常采用序列标注、Span 标注、指针矩阵标注等方法。其主要的难点有实体嵌套、实体非连续、NER 数据样本少、实体类型混淆等。对于实体嵌套问题,序列标注、Span 标注可采用多标签分类的方式解决,或使用 MRC-QA 进行多轮预测。相对于前两者,指针矩阵标注在嵌套实体任务上的表现更优。
实体抽取与关系抽取通常采用联合抽取的方案一起解决。在联合抽取中,有先抽取所有实体后配对;先抽取头实体而后为其配尾实体;一步到位全部一起抽取等操作。基于 Span 标注的联合抽取方案似乎是目前信息抽取的主流。
实体抽取
标注框架
序列标注
数据格式:
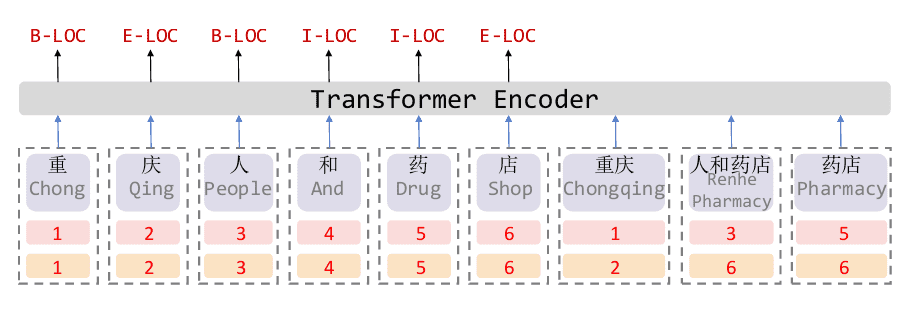
传统的实体抽取标注方案,通常采用 BIO、BIOLOU 等标注方案。可以将原始数据处理成平行的 token 以辅助训练集的生成,也可以直接通过 pickle 缓存处理好的平行数据。
泉 州 的 天 气
B-loc I-loc O O O
若有 n 个实体类别,采用 BIO 标注的话,模型实际是做 3n + 1 分类;如果常用 MRC-QA,则需要做 n 次 3 分类任务。
其他参考
Neural Architectures for Nested NER through Linearization
采用 LSTM-CRF 框架进行序列标注任务;提出采用多标签解决实体嵌套;如在 BILOU 框架下进行多标签标注:
in O
the B-ORG
US I-ORG|U-GPE
Federal I-ORG
District I-ORG|U-GPE
...
Hierarchically-Refined Label Attention Network for Sequence Labeling
CRF 加速解码方案
指针标注(Span 抽取)
数据格式:
指针标注(Span 抽取),即用两次二分类任务来标注所有实体的 开头 与 结尾 位置(似乎是目前的主流方案)。构造 的方式有很多,若原始数据中没有目标的索引信息,则可以使用单词匹配方法进行匹配,该构造方案需注意句子中是否有相同单词对应不同实体类别的情况。如:“我在苹果手机店吃苹果”。
对于基础指针标注方案,如果有 n 个实体类别,需要做 2 次 n 分类任务;对于 MRC-QA 需要做 n 次 2 元二分类任务,以分别判断每个位置是否是实体开头或结尾。
在解码时,需要根据所有预测的 beg 与 end 标签来推出实体,大部分 Github 上的指针抽取解码方案采用就近原则,贪婪地为所有 beg 标签匹配其之后距离最近的 end 标签,而后截取这个片段作为实体。当存在嵌套实体时,一般会将 beg,end 对应的隐状态输入额外的模块,以此对所有头尾对进行评分筛选。
其他参考
A Unified MRC Framework for Named Entity Recognition
MRC-QA 构造问题的方式比较容易理解,其通过不同的 query 语句实现不同的实体类别抽取。此外配对开头与结尾时,该文中 额外使用了一个线性层来匹配开头结尾 ,以此处理一些较为复杂的实体抽取任务。
矩阵标注(指针网络抽取)
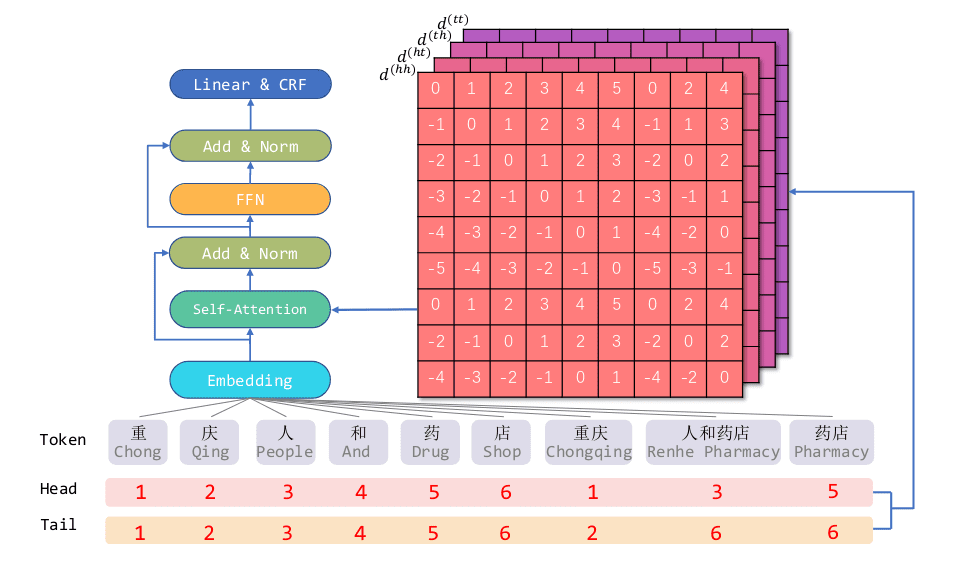
该标注方案可以理解为,多层的、多分类的指针网络(非指针标注)。如 Span{呼}{枢}=1 表示从呼到枢的字符串属于实体类别 1。该标注方案 实体嵌套问题 上的表现优于序列标注和 Span 抽取。
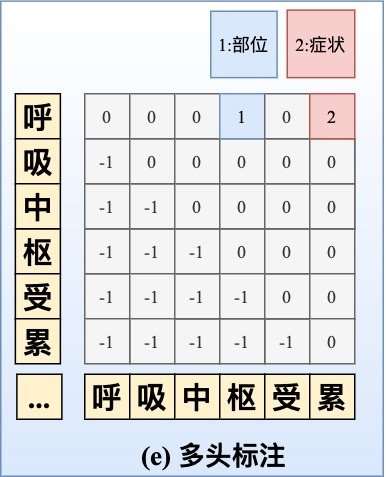
(图:来源与刷爆 3 路榜单,信息抽取冠军方案分享:嵌套 NER+关系抽取+实体标准化)
其他参考
Named Entity Recognition as Dependency Parsing; code 该论文提出,在对句子进行编码后,采用 Biaffine 机制构造 span 矩阵。 Biaffine 的本质是注意力机制 ,对隐状态进行 MLP 转换后,通过两种不同的注意力权重叠加得出实体评分,实体评分方式为:
其中 分别为不同位置的 token 隐状态。
HIT: Nested Named Entity Recognition via Head-Tail Pair and Token Interaction
EMNLP20 的 HIT 通过 Biaffine 机制专门捕获边界信息,并采取传统的序列标注任务强化嵌套结构的内部信息交互,同时采取 focal loss 来解决 0-1 标签不平衡问题。
NER 相关问题
NER 难点描述
- 嵌套实体: 如:呼吸中枢受累 为症状,呼吸中枢为部位。
- 非连续实体: 如:尿道、膀胱痛。包括尿道痛、膀胱痛。
- 类型混淆 :一词多类问题,如医学上的实体 左肺上叶 属于部位实体,但部位实体有可能属于二级分类中的病理或影像。
- 不完全标注 NER: 标注量少,漏标情况严重
对于嵌套实体,目前可以采用多轮抽取、多标签抽取、多片段抽取、矩阵抽取等解决。深度学习能够很好的解决词性敏感问题(一次多义), 对于某些具有固定实体集的行业,考虑使用规则抽取效果可能更好 。对于 MRC-QA 一类多轮抽取模型,深度学习架构本身对算力需求就高,加之重复对句子编码,使得算法复杂度过大,难以在工业中很好的应用。
思考点
进行模型预测、指标计算时,考虑储存预测与目标的 [entity type, (beg_id, end_id)] 数据,完全匹配才算预测正确,不同实体类别分开统计;训练过程中,也可以计算其他的预测准确率,如针对序列标注任务,分别计算不同 BIO 的指标,以此来判断模型问题所在。
对于样本不平衡,考虑 focal loss,个人在 SemEval 数据及上进行实验,发现 最为稳定。
NER 中的 Transformer
之前在 TRANSFORMER 位置编码小述 中讨论过绝对位置编码的问题,在 NER 任务中,单词的先后顺序会对预测结果产生较大的影响。因此 TENER、FLAT 等模型也都采用了相对位置编码代替绝对位置编码。
NER 中的词汇增强
尽管目前预训练微调的方式有点强大,但各种词汇增强技术配合 LSTM-CRF 的表现也能超过微调 RoBerta wwm。 因此了解词汇增强技术还是很有必要的。
Word Segmentation for Chinese Novels
参考了 n-gram 的思想,传统的 LSTM 仅针对单个字符进行编码。论文提出在编码时,为每个位置添加 biChar embedding,来传递长度为 2 的词组信息:
其中 为单字符 embedding, 为双字符 embedding。bi-char 预训练的方案与单字符相似。15 年提出的方法,现在看到有些信息抽取比赛的冠军方案还在用(估计有什么小 Trick)。
Chinese NER Using Lattice LSTM
Lexicon augment 首先针对 LSTM 模型提出,复杂度高,其模型的每个位置隐状态由以该位置结尾的不同单词以及该位置的字符决定。如 长江大桥由 [桥,大桥,长江大桥] 共同决定。但这种方案也会产生信息冲突,如 广州市长隆 中 市长 就会被添加到 长的信息中。
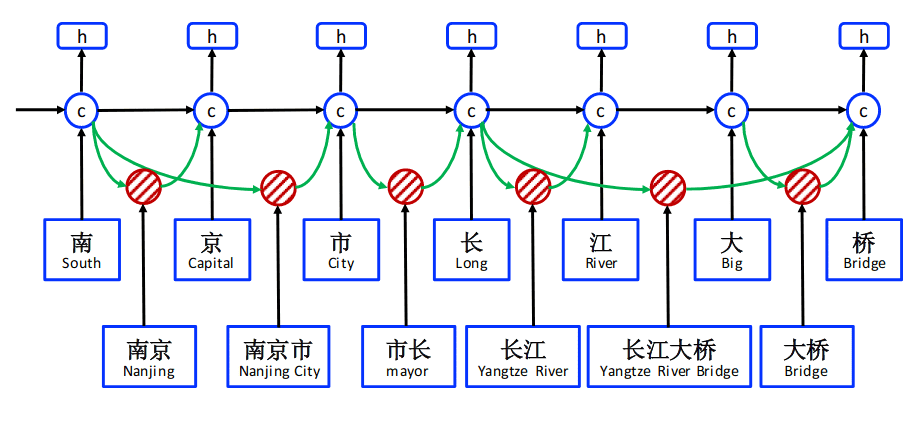
Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network
论文提出了 CGN(Collaborative Graph Network),主要思想是通过中文分词工具,根据句子构造出图,通过 GAT 对各个位置进行编码,文中提到了 GCN 但最后没有采用,估计是由于 GCN 依赖于固定的拉普拉斯算子,无法适应论文中提出的不同图结构。
图有两种构造方式,使用中文分词及各个字符作为节点后,一是在句子上位置相邻的两个词/字符之间建立边。二是在单词和其包含的各个字符之间建立边,字字之间无连接。三是在每个相邻的字符间,及单词和其头尾字符间建立边。
原输入为字符与其包含的中文分词的拼接;词级别的节点使用预训练表征作为初始向量,而字符级别节点使用 Bi-LSTM 进行编码;使用 GAT 分别对上面提到的三种图结构编码,保留字符位置编码 ;将所有 拼接,经过一层 Dense + CRF 得到解码。
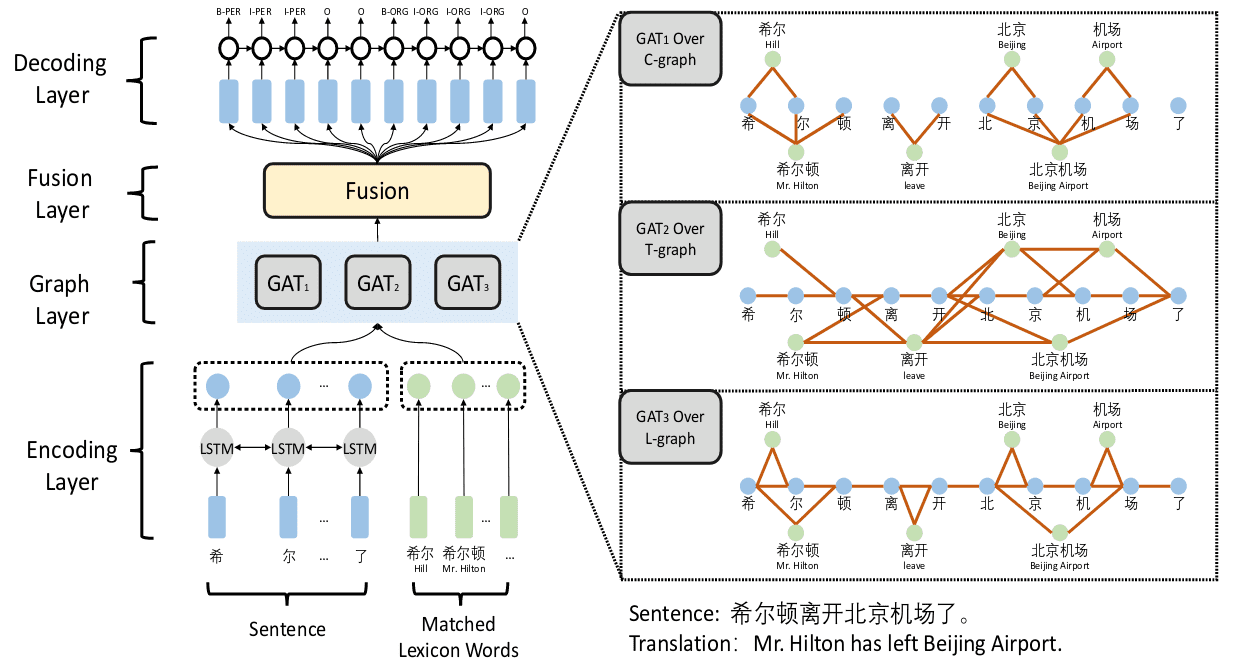
FLAT: Chinese NER Using Flat-Lattice Transformer
FLAT 采用的相对位置编码较 TENER 来说更为复杂,TENER 采用了序列标注的方式进行 NER 任务,仅仅考虑了编码与编码之间的相对位置,而 flat 则考虑了单词与单词、字符与单词、字符与字符三种位置编码的相对关系。FLAT 同样采用序列标注,但在建模上参考了 Chinese NER Using Lattice LSTM 的思想,在模型中融入词信息,分词词表采用了 Lattice LSTM 的词表。不同与 Lattice LSTM,FLAT 使用了 flat-lattice 方案,即对每个位置,添加下图中红色、黄色两种编码来表示词或字所在的开头和结尾索引,加入了字符与词、词与词之间的交互。
FLAT 提出了基于 span 级别的相对位置编码方式,用 span 可以表示任意连续不间断的词 。对于词 他们之间的距离由四个数表示:
通过词距离可以计算相对位置关系 ,FLAT 结合了三角式位置关系和可学习位置关系:
最后,注意力权重与 Transformer-XL 相同,表示为四项,其中 为可学习参数:
(图:FLAT 总体架构)
关系抽取
关系分类
监督学习进行关系分类的考虑点:
- 对于预训练模型,如何解码?使用那个位置的 pooling 效果好?
- 如何构造输入?可以采用
句子,实体 1,实体 2的方式,也可以采用特殊编码标注实体位置,如 ERNIE 使用两个特殊编码标注头/尾实体
其他参考
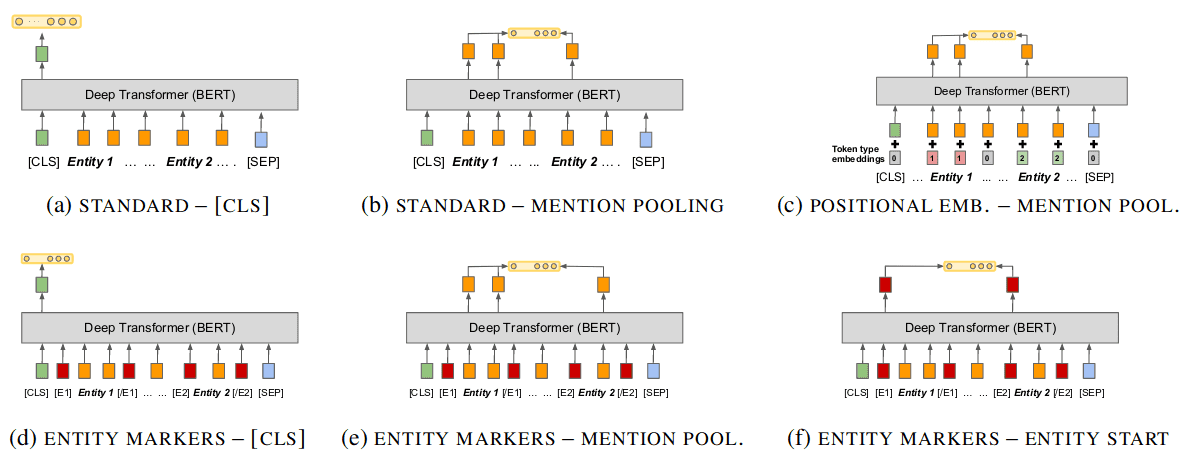
Matching the Blanks: Distributional Similarity for Relation Learning:pooling
已知实体对位置,如何更好的预测他们之间的关系?在对句子进行编码之后,使用什么位置的隐状态来预测实体之间关系呢?论文中分别对 [CLS] 位置编码,实体位置对应隐状态、添加额外的位置编码提示实体位置、添加额外的 [E1], [E2]token 进行实体提示(类似 ERINE-1.0)等 6 中方案进行实验,结果发现添加额外的 token 后,使用该 token 的隐状态预测实体关系效果最好。不过文中没有对构造 Query/Prompt 的方式进行实验测试。
联合抽取
对头实体、尾实体、实体间关系类别进行联合抽取,常见的方案是共享模型参数、统一标注方案等。
其他资源
End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures;
2016 经典文章;序列标注 BILOU,采用 LSTM - Softmax 先提取所有实体; 对各实体对,建立实体对之间的最小依存句法树,通过 N-ary TreeLSTM 生成向量表示后进行关系分类。
Joint extraction of entities and relations based on a novel tagging scheme
提出统一 序列标注 体系,即B/I/O - 关系类型 - 头/尾位置 。匹配实体间关系时采用就近原则贪婪匹配。如 B-CP-1他后面最近的 E-CP-1。这种方案一步到位,但是不能处理复杂的实体/关系抽取。

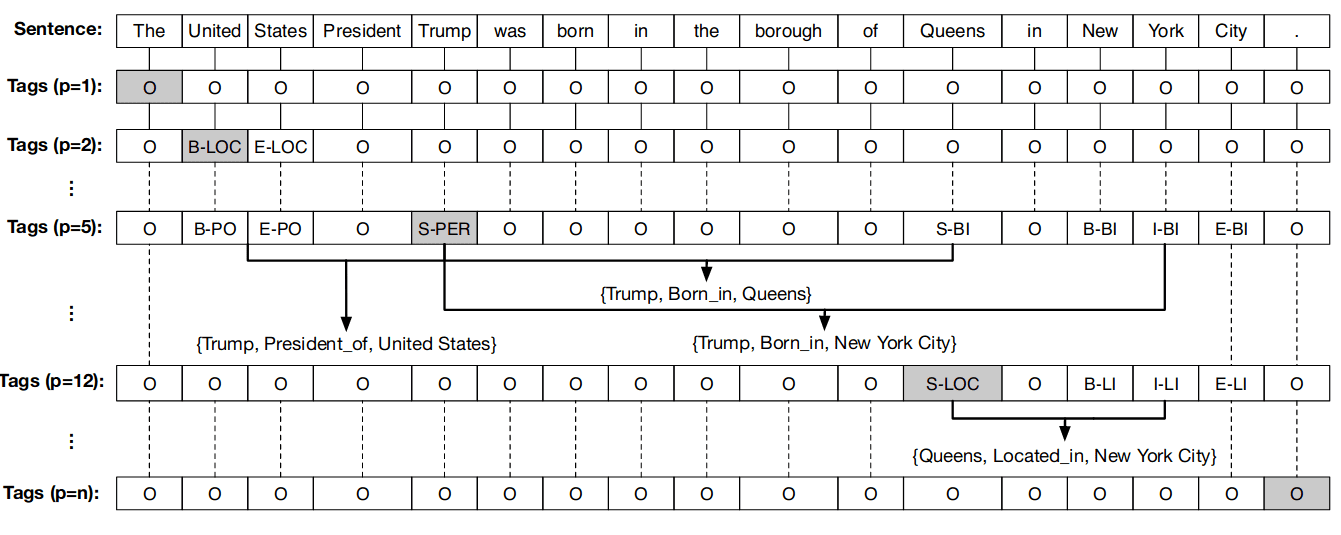
Joint Extraction of Entities and Overlapping Relations Using Position-Attentive Sequence Labeling;
提出 多层序列标注 。n 为句子长度,对于 i=1 到 n,建立 n 个标注序列,复杂度极高。在第 i 个标注序列中,如果第 i 个词是实体则标注为 B-实体类别,并且标注该实体其余的位置为 I-实体类别, 如果该词为头实体 ,则标注对应的尾实体为 B/I/O - 关系类型。
Joint Extraction of Entity Mentions and Relations without Dependency Trees;
使用 序列标注 先抽取实体 ;而后通过加性注意力和指针网络 匹配头实体和尾实体 ;进行 R 分类以判断不同关系类别 。对于每个实体,仅向前查询进行匹配,存在遗漏尾部实体的问题:
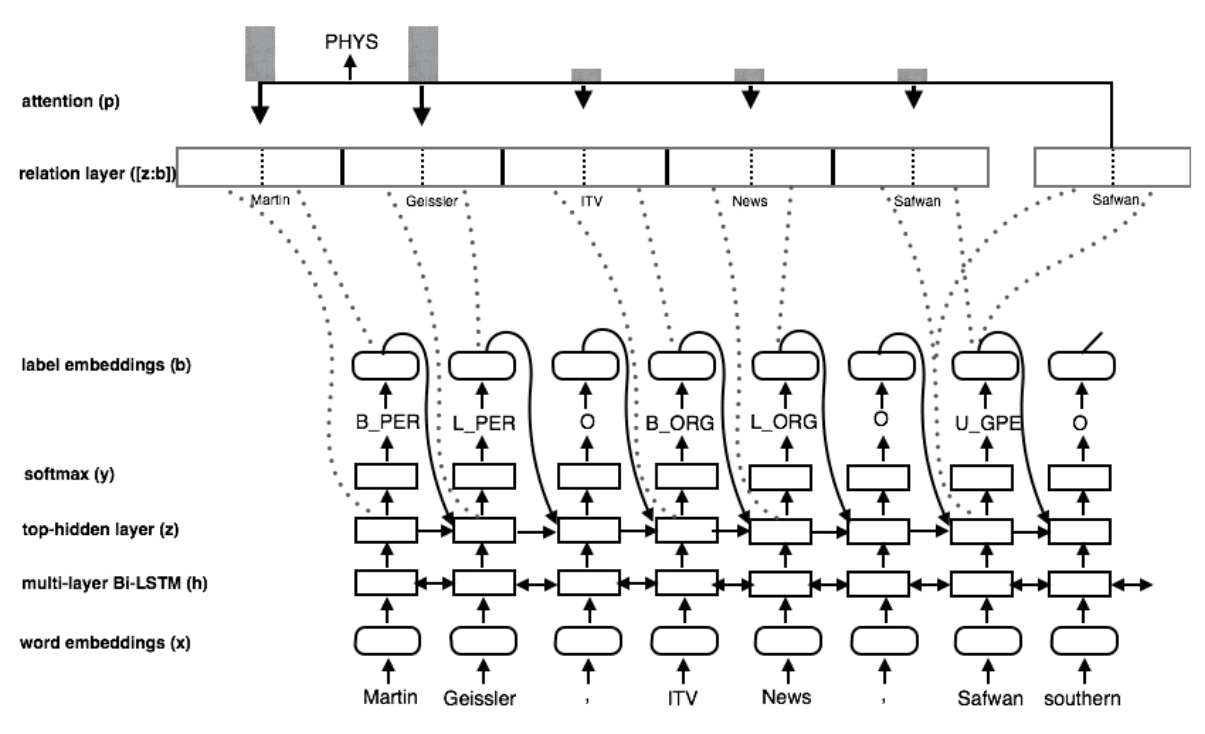
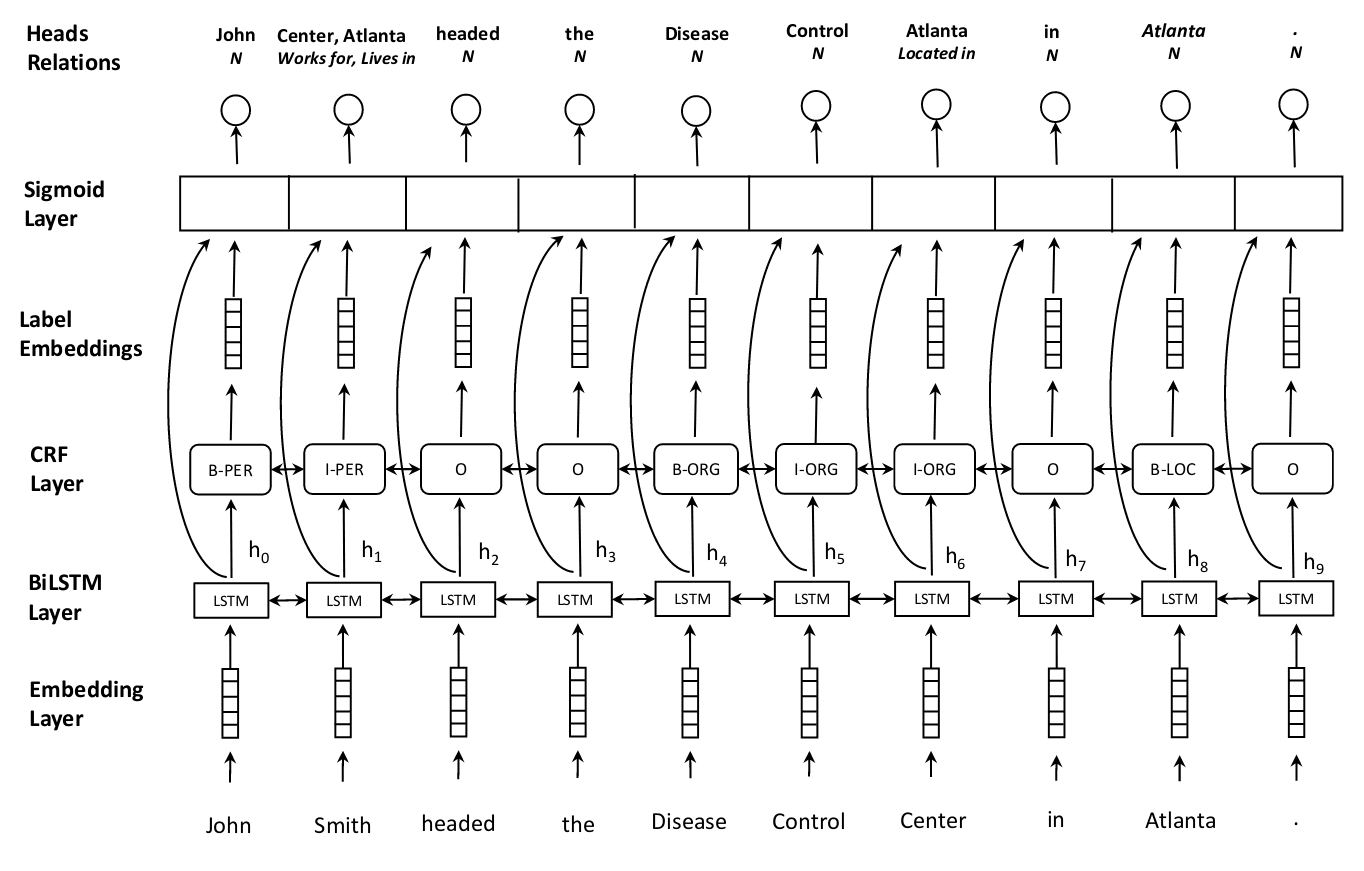
Joint entity recognition and relation extraction as a multi-head selection problem;
该方案可看做前一篇论文的完善版本, 应用较广 ;首先采用 序列标注 + BiLSTM-CRF 抽取实体;而后将每个位置的 hidden_state 与其对应的label_embedding(每个实体类别对应的 embedding,可学习)拼接得到 。最后计算两两 token 之间的加性注意力来判断关系类别。即对于单词 ,他们之间就关系 的评分为 , sigmoid(s)>threshold表示量实体之间存在关系 :
在 DeepIE 方案中采用了拼接的方法求注意力,而非选择论文中的加性注意力,并且训练时全程使用 teacher force。多头选择的解码方案(也可以看做多次指针网络抽取):采用 b, s, p, o = torch.nonzero(sigmoid(s)*attention_mask) ,即从最终的解码矩阵中,抽取出非 0 的元素所在位置。其中 b 为 batch_idx,spo 即实体三元组对应的索引。 采用实体最后一个 token 来代表实体。
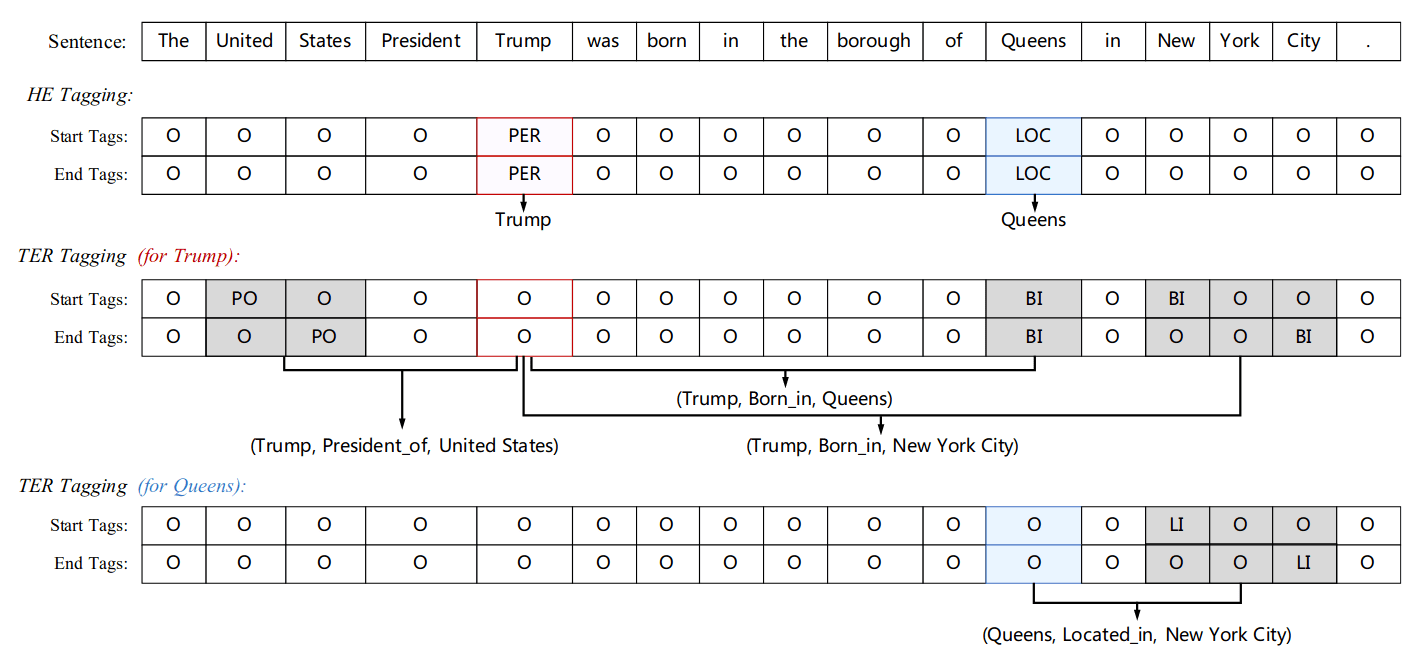
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy(ETL-SPAN);
ETL-SPAN 的方案相对优雅,并且在 DeepIE 的实验中有着不错的成绩。其先用 m 分类指针网络抽取实体(HE),m 为实体类别数量;对每个实体,用 r 分类指针网络抽取尾实体和关系(THR),r 为关系数量;
注意: 由于训练时 HE 与 THR 构造出来的数据集数量不一致,因此训练时采用 1. 对所有实体进行 1 次 2 元 m 分类预测计算损失。2. 随机抽取一个实体 ,及其对应的尾实体信息,进行一次 2*r 分类预测,计算损失;3. 前两者损失加和,计算总损失。由于第二部的随机抽取训练数据集,导致他 需要长 EPOCH 训练 。
THR 时,原论文将 HE 预测的 头实体与句子拼接 ,以此传达头实体的先验信息。 然而在 DeepIE 代码中,头实体信息通过一个条件 LayerNorm 来传递。 (这样也行???个人认为采用 MRC 的方式,将头实体构造成 query 可能效果更好,毕竟作为额外的编码,可以通过 MHA 对输入不同的位置产生不同的影响。)
Entity-Relation Extraction as Multi-Turn Question Answering.
采用 MRC-QA 方式提取头实体;通过多轮询问的方式,获得所有头实体相关信息,包括尾实体/关系/关系附属信息等。模版构造示例:
Q1: Person: who is mentioned in the text? A: e1 Q2: Company: which companies did e1 work for? A: e2 Q3: Position: what was e1’s position in e2? A: e3 Q4: Time: During which period did e1 work for e2 as e3 A: e4
此外该论文采用了强化学习方法。
关系抽取相关问题
关系抽取难点描述
- 关系重叠: 如一个实体对应多个关系(鲁迅的《朝花夕拾》《呐喊》)、两个实体之间有多重关系、实体与关系嵌套(《叶圣陶散文选集》包含关系:叶圣陶-作品-叶圣陶散文选集)。
- 关系交叉 :如鲁迅、叶圣陶分别写过《呐喊》《脚步集》。
思考点
- 可以采用 Conditional Layernorm 来传递头实体信息/实体分类信息
一般的 layer norm 会有超参来控制归一化程度:
torch 中的 nn.layernorm 超参是固定的,conditional layernorm 的思想是令 。即归一化程度受 影响,且该影响的映射可学习。
subject = torch.cat([sub_start_encoder, sub_end_encoder], 1)
context_encoder = self.LayerNorm(bert_encoder, subject)
- 根据情况,尝试无视头尾实体类别,直接进行 spo 三元组抽取
对于指针标注(Span 抽取) DeepIE 在实践中发现,n 个 2 元 Sigmoid 分类的指针网络,会导致样本 Tag 空间稀疏,同时收敛速度会较慢,特别是对于实体 span 长度较长的情况。 因此刚可以无视头实体类别,直接采用一个 2 元 sigmoid 进行分类。 匹配头尾时采用就近原则。根据 DuIE2.0 数据集的三元组 schema 可发现,每种关系分别对应唯一的 spo schema,因此无视头尾实体类别进行抽取后,可直接根据给定的 schema 来判断头尾实体类别。
但是依然存在更复杂的关系情况,如 ACE04/05 和 CoNLL04 数据集。
- 训练考虑点
对于开头与结束位置预测通常使用 sigmoid(h)>threshold,threshold 可以设置 0.4-0.6; 对于分阶段的联合抽取,可以考虑调整 teacher force learning 的使用频率。 模型进行预测评分时,考虑(s,p,o) 元组完全相等的时候为预测正确;训练时可分别计算 头实体抽取效果 与 spo 三元组抽取效果
参考
DeepIE: Deep Learning for Information Extraction
如何解决 Transformer 在 NER 任务中效果不佳的问题?
中文学术数据集 - DuIE2.0 关系抽取、DuEE1.0 事件抽取、DuEE-fin 金融领域篇章级事件抽取
刷爆 3 路榜单,信息抽取冠军方案分享:嵌套 NER+关系抽取+实体标准化
论文清单
[1] HIT: Nested Named Entity Recognition via Head-Tail Pair and Token Interaction [2] Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network [3] Word Segmentation for Chinese Novels [4] Chinese NER Using Lattice LSTM [5] TENER: Adapting Transformer Encoder for Named Entity Recognition [6] Named Entity Recognition as Dependency Parsing [7] Joint entity recognition and relation extraction as a multi-head selection problem [8] Going out on a limb: Joint Extraction of Entity Mentions and Relations without Dependency Trees [9] Joint Extraction of Entities and Overlapping Relations Using Position-Attentive Sequence Labeling [10] Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme [11] Simplify the Usage of Lexicon in Chinese NER [12] FLAT: Chinese NER Using Flat-Lattice Transformer [13] Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy [14] Entity-Relation Extraction as Multi-Turn Question Answering [15] Neural Architectures for Nested NER through Linearization [16] A Unified MRC Framework for Named Entity Recognition [17] End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures [18] Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers [19] Matching the Blanks: Distributional Similarity for Relation Learning [20] Maximal Clique Based Non-Autoregressive Open Information Extraction [21] Semi-Open Information Extraction