信息抽取论文小述(二)|实体抽取、关系抽取
本文对 PURE, TPLINKER, GPLINKER, UIE 四篇文章做部分论文笔记与整理。
信息抽取论文小述|实体抽取、关系抽取
PURE
A Frustratingly Easy Approach for Joint Entity and Relation Extraction 论文链接
陈丹琦组提出的 pipeline 方案,在当时击败了其余的 joint 模型,该方案的特点在于:
- 文章同样尝试了共享编码器,与不共享编码器的区别。发现 NER 与关系抽取分别采用两个不同的编码器效果会好一点点。
- 实验说明了在关系抽取阶段,加入实体的类别信息很重要。
- 跨句信息能提高成绩。
- Mitigating Error (信息抽取中的误差传播问题)理论上还是存在,但是文中提出的一些办法都没能很好的解决。
PURE 模块一:Span-level NER
在 NER 阶段,使用了传统的 span-level NER,使用以下公式代表一个 span 的 logits:
其中 X 为 span 开头结尾对应的 logits, 为一个长度编码器。及输入一个长度数字,返回一个 embedding。
这种方法需要遍历所有的 中头尾排列组合。因此文中提出了我们要限制 span 的长度,来减少计算复杂度。
限制 span 的方法也很简单,代码中直接对实体进行了截取。即超过一定长度的实体,头的位置不变,尾 span 的位置调整。
PURE 模块二:关系抽取
文中的关系抽取,提出了两种方案:
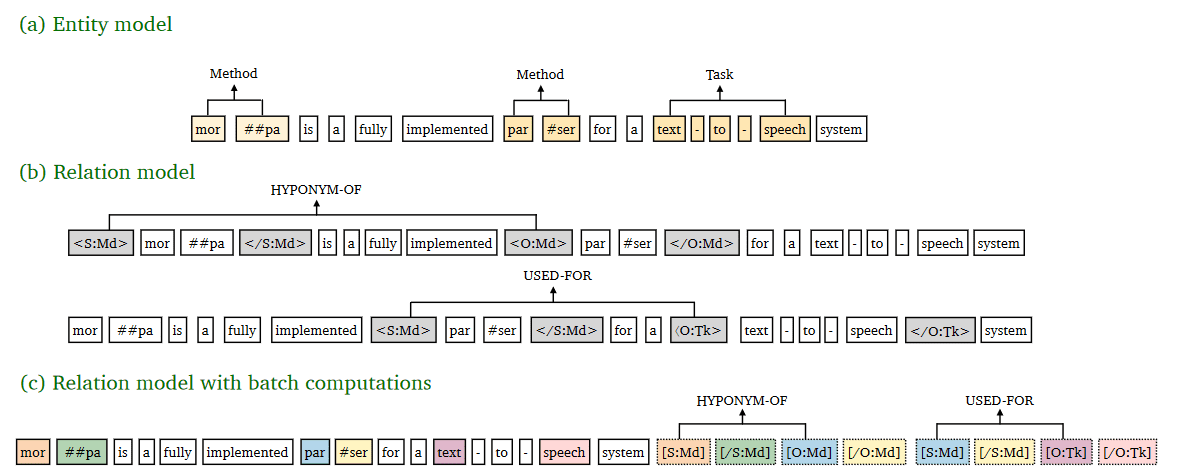
方案一: 首先将实体抽取阶段的结果加入到输入句子中。方式是在实体首尾加入 <S:Md> 或者 <O:Md> 标识符。S 表示 subject,Md 表示实体类别。 文中指出,实体类别能够很大地提高关系抽取的结果。 预测时使用标识符位置对应的 logits 进行预测。
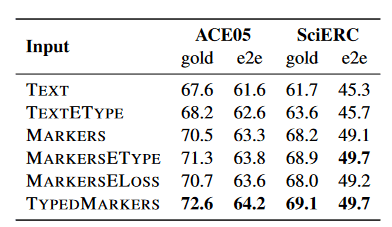
中文版引用于 JayJay 知乎,论文对表格也有详细的解释。
- TEXT :直接提取原始文本中,实体 span 所对应的编码表示。
- TEXTETYPE :在 TEXT 的基础上,concatenate 实体类别向量。
- MARKERS :将标识符 S、/S、O、/O 插入到原始文本中,但是标识符没有实体类别信息。
- MARKERSETYPE :在 MARKERS 的基础上,concatenate 实体类别向量,这是一种隐式的融入实体类别的方法。
- MARKERSELOSS :在关系模型中,构建判别实体类别的辅助 loss。
- TYPEDMARKERS :就是本文所采取的方法,实体类别“显式”地插入到文本 input 中,如<S:Md> 和</S:Md>、<O:Md>和</O:Md>。
从图中可以看出,显示的添加实体的类别(TYPEDMARKERS) 比其他操作效果更好。
这种方案的一次只能预测一个实体对之间的关系。因此文章提出了一种 加速方案 :
方案二:加速方案
将所有实体标识符放在句子最后(参考上文中的图),标识符于其代表的实体共享位置向量,上图中的颜色就表示位置向量。
此外,文中的内容 token 只去 attend 文本 token,而标识符可以 attend 所有原文 token。在预测时使用 subject 和 object 头 span 的标识符位置对应的 logits 预测。这种方案加速效果明显,指标仅仅下降了不到 1%。
TPLinker
《TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》文章链接 代码链接
TPlinker 解决了暴露偏差问题,同时也能针对实体重叠,关系重叠的情况。
编码方案
TPlinker 数据标注形式如下
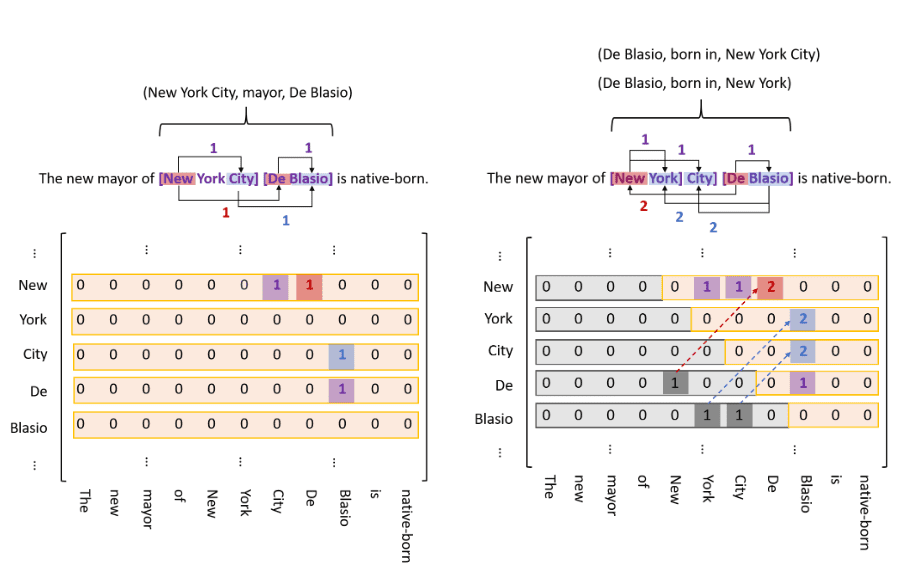
文中采用三种 0/1 矩阵矩阵来实现了标注,
- Entity Head to Entity Tail(紫色)
- Subject Head to Object head;用于判断关系,每种类型的关系使用一个矩阵实现。(红色)
- subject tail to object tail;用于判断关系,每种类型的关系使用一个矩阵实现。(蓝色)
因此,标注数据一共是 2*R + 1 个矩阵。同时,为了缓解稀疏矩阵计算,对于标注矩阵左下三角的数据,会被转置到右上部分,并且对应的 1 改为 2。
解码方案
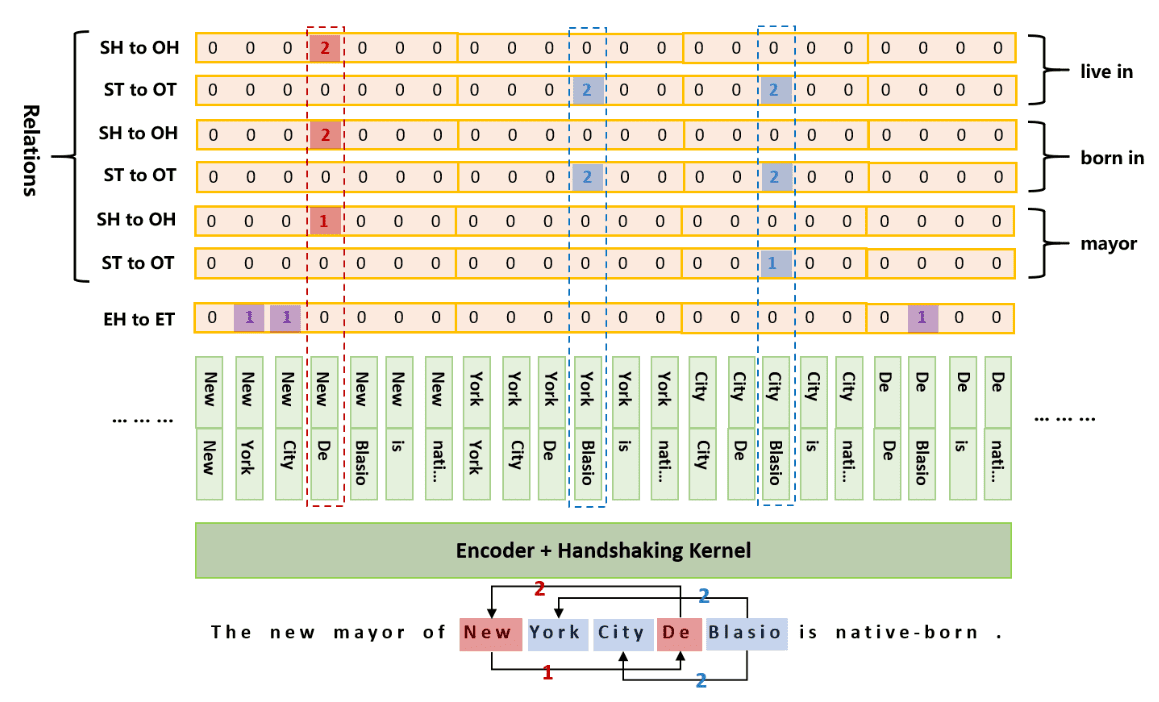
首先能够通过 EH to ET 的到所有实体,而后遍历每种关系类型的 SH to OH 和 ST to OT 得到三元组结果。如 mayor 关系:对应的三元组结果就是 (New York City, mayor, De Blasio)
其他
假设 len_seq=5在经过 transformer encoder 编码成 [batch_size, 5, hidden_size] 后,采用一个 HandshakingKernel 对所有 token pair 的排列组合进行编码 ,hidden states 形状变成 [batch_size, 5+4+3+2+1, hidden_size],最后经过一层 fc,得到如上图(解码方案部分)所示的结果,可以注意到解码方案中,New 占据 7 个格子,而 York 占据 6 个格子,这就是 HandshakingKernel 处理出来的格式。
GPLINKER
参考自:
GlobalPointer:用统一的方式处理嵌套和非嵌套 NER
GPLinker:基于 GlobalPointer 的实体关系联合抽取
GlobalPointer 大致流程为:
def forward(self, inputs):
qw, kw = self.dense_q(inputs), self.dense_k(inputs)
# RoPE 相对位置编码
qw, kw = self.add_RoPE(qw), self.add_RoPE(kw)
# 计算注意力权重
logits = paddle.einsum("bmd,bnd->bmn", qw, kw) / self.head_size**0.5
# 计算每一种实体类别对应 q, k 的 bias
bias = paddle.transpose(self.dense2(inputs), [0, 2, 1]) / 2
logits = logits[:, None] + bias[:, ::2, None] + bias[:, 1::2, :, None]
# ... (去除 padding 以及下三角部分的数值)
return logits
因此 GlobalPointer 可以看做一个加上了 RoPE 相对位置信息的多头注意力机制。笔记特别的是,该论文作者提出采用多标签分类损失函数(参考: 《将“softmax+交叉熵”推广到多标签分类问题》 ),代替 次二分类,这样解码在并行的情况下能够达到 的时间复杂度。并且 GlobalPointer 计算 F1 指标时候,会相对容易很多。
GPLinker
与 TPLinker 的一个较大结构区别是, GPLinker 采用乘性注意力,而 TPLinker 采用加性注意力。 与 TPLinker 相同的,我们可以采用一个 GlobalPointer 来负责实体的预测(但 GPLinker 将头实体与尾实体分开预测),一个负责 SH to OH 的计算,另一个负责 ST to OT 的计算。
在训练阶段使用 GlobalPointer 中提出的多标签分类交叉熵,这也不同于 TPLinker 采用的 次分类交叉熵。
UIE
提出了 text-to-structure 生成任务,将各种信息抽取任务统一进行编码、学习与训练。
统一输出 SEL
采用结构化的方式来构建并且区分不同关系抽取中的任务,如:

统一输入 SSI
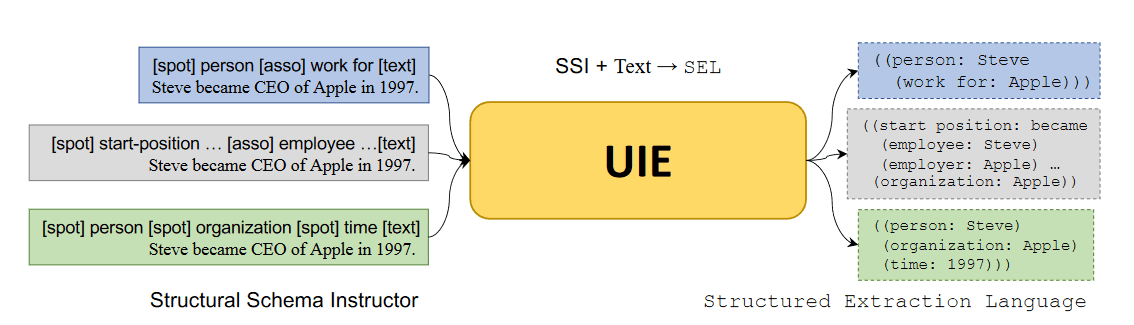
输入统一构建成以下格式:
[spot] person [spot] company [asso] work for [text] content
其中 [spot] + Entity_type 用来表示想收取的实体类型,[asso] + relation_type 表示想抽取的关系名称。
不同任务的输入构建方式:
- 关系抽取:
[spot] person [spot] company [asso] work for [text] content - 事件抽取:
[spot] 事件类别 [asso] 论元类别 [text]观点抽取:[spot] 评价维度 [asso] 观点类别 [text]
对于预训练时候 UIE 采用了什么 prompt 进行输入构建,可以参考论文附件。
进一步的预训练
UIE 英文版基于 T5 进行了进一步的预训练。
预训练的优化目标包括:
- :通过 Wikipedia 构建统一的结构化输出 SEL 与输入 SSI。采用生成任务进行预测与训练。训练过程中在 SSI prompt 部分加入无关的实体类别,作为负例噪声训练
- :用来学习信息抽取统一输出的结构。采用生成任务对输出结构 SEL 进行预测与训练。
- :Span corruption based MLM.
微调方式
- 微调过程中,在 prompt 处加入部分不存在的实体类型,作为噪声进行训练。
关于 UIE 代码
PaddleNLP 中的 UIE 采用的是 ErnieModel ,为 Encoder 架构,使用 Span 标注,通过 MRC 方式统一解决实体抽取,关系抽取,情感分析等任务。此外,在 taskflow/information-extraction 找到了 uie-data-distill-gp 模型,其中采用的是 GPLINKER 架构。
以下为部分 paddlenlp/taskflow(ErnieModel
) 使用笔记:
对于实体抽取,用户 query 格式为列表:[实体类别,实体类别,...],采用 [cls] + prompt + [sep] + text 的方法构建输入;
schema = ["姓名", "省份", "城市", "县区"]
ie = Taskflow("information_extraction", schema=schema)
"""
中间过程变量
short inputs [{'text': '北京市海淀区上地十街 10 号 18888888888 张三', 'prompt': '姓名'}]
result_list [[{'text': '张三', 'start': 24, 'end': 26, 'probability': 0.9659837822589807}]]
"""
对于实体抽取,用户 query 格式为字典:{头实体:[尾实体 1, 尾实体 2,...]}。刚方案默认一个头实体与一个尾实体仅存在一种关系。
schema = {'歌曲名称': ['歌手', '所属专辑']}
ie.set_schema(schema)
ie('《告别了》是孙耀威在专辑爱的故事里面的歌曲')
"""
过程变量
short inputs [{'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '歌曲名称'}]
result_list [[{'text': '告别了', 'start': 1, 'end': 4, 'probability': 0.6296134126625006}, {'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.28168733127927226}]]
# 这里识别错了爱的故事,因此下面就会出现由于 pipeline 流程导致的
short inputs [{'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '告别了的歌手'}, {'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '爱的故事的歌手'}]
result_list [[{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9988381005599081}], [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9951415104192272}]]
examples: [{'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '告别了的所属专辑'}, {'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '爱的故事的所属专辑'}]
short inputs [{'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '告别了的所属专辑'}, {'text': '《告别了》是孙耀威在专辑爱的故事里面的歌曲', 'prompt': '爱的故事的所属专辑'}]
...
"""
该方式与训练描述的输入输出格式不同。但 paddlenlp 中模型支持中文,在 T5 没有中文权重的情况下,使用 ERNIE 中文权重应该会更合适。
论文官方的源码为: universal-ie/UIE。输入输出处理方式与论文相同。