DIFFUSION 系列笔记 | IP-Adapter
本文介绍 IP-Adapter,结合笔者的使用体验,在垫图方面,IP-Adapter 效果比 Controlnet reference only 及 SD 原生的 img2img 效果要好很多。并且可以配合 controlnet 的其他风格(如 canny 或者 depth)来实现多维度的图片生成控制。
LDM 回顾
回顾 LDM 中的 img-to-img 部分,LDM 中图像与文字交互的方式为单纯的 cross-attention:
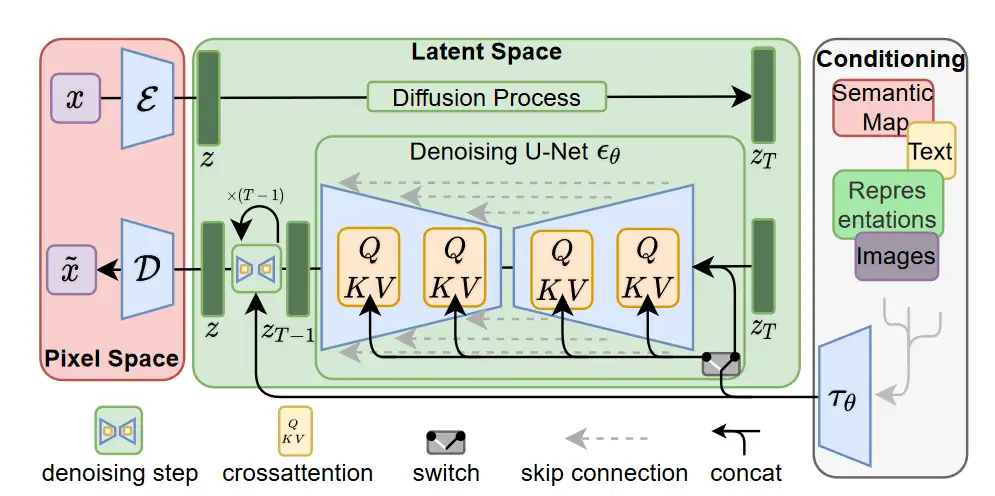
文本先是被编码后, padding 到了固定的 77 长度,以此来保证文字的 hidden state 格式为 [batch_size, 77, 1280]。
而后再 UNET 的 Transformer2DModel 当中。每个 Transformer2DModel 先对输入的图像数据进行预处理,将图片格式从如 (batch_size, channel, width, height) 或 (batch_size, num_image_vectors) 转换为 (batch_size, len_seq, hidden_size),而后将 hidden_states 传入 1 层传统 Transformer layer(非 bert 或 GPT 类型),先对图像 hidden_states 进行 self-attention,而后结合文本编码 encoder_hidden_states 进行 cross attention 处理:
# LDM 传统的 CrossAttnDownBlock2D(参考 huggingface diffusers 实现)
def forward(self, hidden_states, temb, encoder_hidden_states=None)
output_states = ()
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
).sample
output_states += (hidden_states,)
# downsampler = Conv2D
hidden_states = downsampler(hidden_states)
output_states += (hidden_states,)
return hidden_states, output_states
由于每层 UNET 的维度不同,因此,在进行 cross attention 时候,图像的 hidden state (latent)大小分别被映射到了 [4096, 320],[2014, 640],[256, 1280] (以 SD 1.5 为例),而后与文字的 hidden state [77, 768] 进行 cross attention 计算。(以上张量维度省略了 batch size)
IP-Adapter 思路
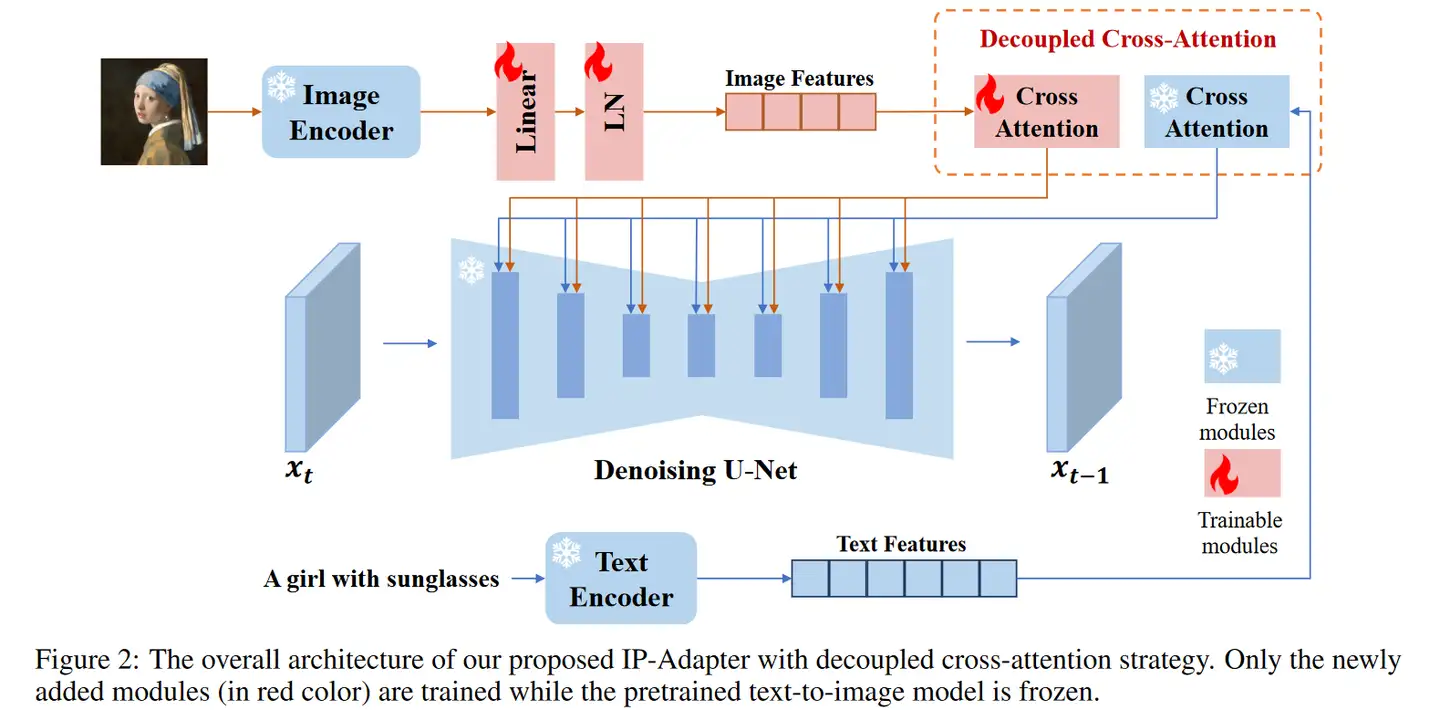
上图为 IP-Adapter 的架构图,IP-Adapter 论文中描述道,image prompt adapter 效果不好的一个主要因素是,图片的特征不能被很好的利用,大部分的 adapter 采用简单的 concatenated 的方式来注入图片特征信息。于是 IP-Adapter 提出了 decoupled cross-attention。
传统的 LDM cross attention 可以表示为:
其中 , 为文本特征, 为与图像相关的 hidden_state。
IP-Adapter 进行注意力解耦后,分别单独计算了文字和 的交叉注意力,以及参考图和 的交叉注意力,而后对两个注意力矩阵进行加和,计算方式为:
其中, 为使用 CLIP 对 IP-Adapter 对应参考图形进行编码,并处理后得到的 hidden_state。 因此,原先的 SD img2img 是将图片作为 latent (initial latent)传入 SD,但 IP-Adapter 中传入的 latent 与 txt2img 一样是随机的。
参考 IP-Adapter 官方的核心代码:
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
else:
# get encoder_hidden_states, ip_hidden_states
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
encoder_hidden_states, ip_hidden_states = (
encoder_hidden_states[:, :end_pos, :],
encoder_hidden_states[:, end_pos:, :],
)
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
# for ip-adapter
ip_key = self.to_k_ip(ip_hidden_states)
ip_value = self.to_v_ip(ip_hidden_states)
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
ip_hidden_states = F.scaled_dot_product_attention(
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
)
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
ip_hidden_states = ip_hidden_states.to(query.dtype)
hidden_states = hidden_states + self.scale * ip_hidden_states
在训练期间,只对 IP-Adapter 相关的参数进行训练,使用 image-text 数据进行训练,训练优化对象与原先的 SD 一致。
在 IP-Adapter 的实验中,论文对 SD 模型中的所有 cross-attention 都加入了 IP-Adapter 相关参数进行调整,整个 IP-Adapter 一共约 22M 可训练参数。文中采用 8 卡 V100 训练了 1M 个 steps,每张卡 batch size 为 8(用 DeepSpeed Zero-2)。根据官方给出的参考图片看来,IP-Adapter 的效果挺不错。

IP-Adapter 中,图片编码器采用了 OpenCLIP-ViT-H-14 ,其作者表示,这个编码器效果和 OpenCLIP-ViT-bigG-14 差不多,但是参数量小了很多。
此外,由于每一层 cross attention 都有额外的 IP-Adapter 权重,因此可以调整要在什么阶段加入 IP-Adapter 额外注意力,这有利于控制。
官方示例
换脸:除了 Lora 微调,face fusion 等技术外,IP-Adapter 也可以实现克隆人脸,参考官方提供的 ip_adapter-full-face 效果还不错。
T2I Adapter
与 control net 相似的,用于控制图片生成的模型,大概思路为:
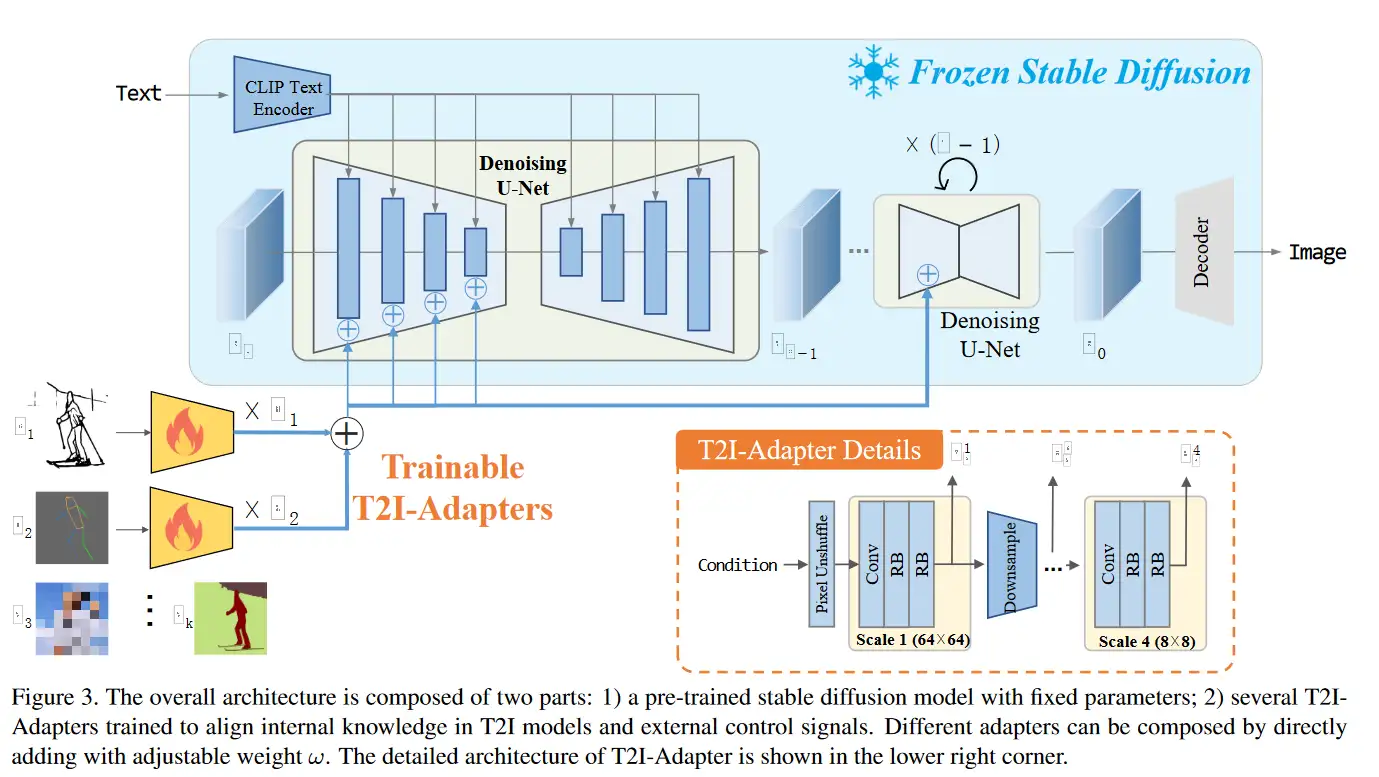
参考以上官方给的图片,我们可以看出 T2I Adapter 和 controlnet 的相似与不同。
相同点:
- 每张条件图片都会别额外编码,编码信息会被加入到图像生成中。
- 可以通过 opse,depth,canny 等进行控制。
- 可以使用多张图片,进行多维度的控制。
- 训练时候,冻结了原先的 unet,只对 Adapter 部分进行微调。
主要不同点:
- controlnet 的 encoder 架构普遍比 T2I 大很多,毕竟 controlnet 是直接复制 encoder 部分,但 T2I 并非复制的 encoder 部分。
- T2I 将图片编码之后,加在了 U-NET 的 encoder 部分。controlnet 是再 decoder 部分进行相加处理的。
参考
代码:https://github.com/tencent-ailab/IP-Adapter
论文:IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
https://ip-adapter.github.io/