Instruction Tuning 时代的模型笔记
Instruction Tuning 时代的模型笔记
Alpaca,ChatGLM 等模型的效果可以接受,下文总结部分笔记,为训练自定义小型化模型提供点知识储备。包括模型论文 LaMDA, Muppet, FLAN, T0, FLAN-PLAM, FLAN-T5
LaMDA
论文:Language Models for Dialog Applications
LaMDA 没用到 Instrcution Tuning,但下文中部分模型基于 LaMDA 进行微调。
模型: 大小从 2B 到 137B 不等。
训练数据: 在 1.56T words 级别的互联网对话及文档预料上预训练。
训练:
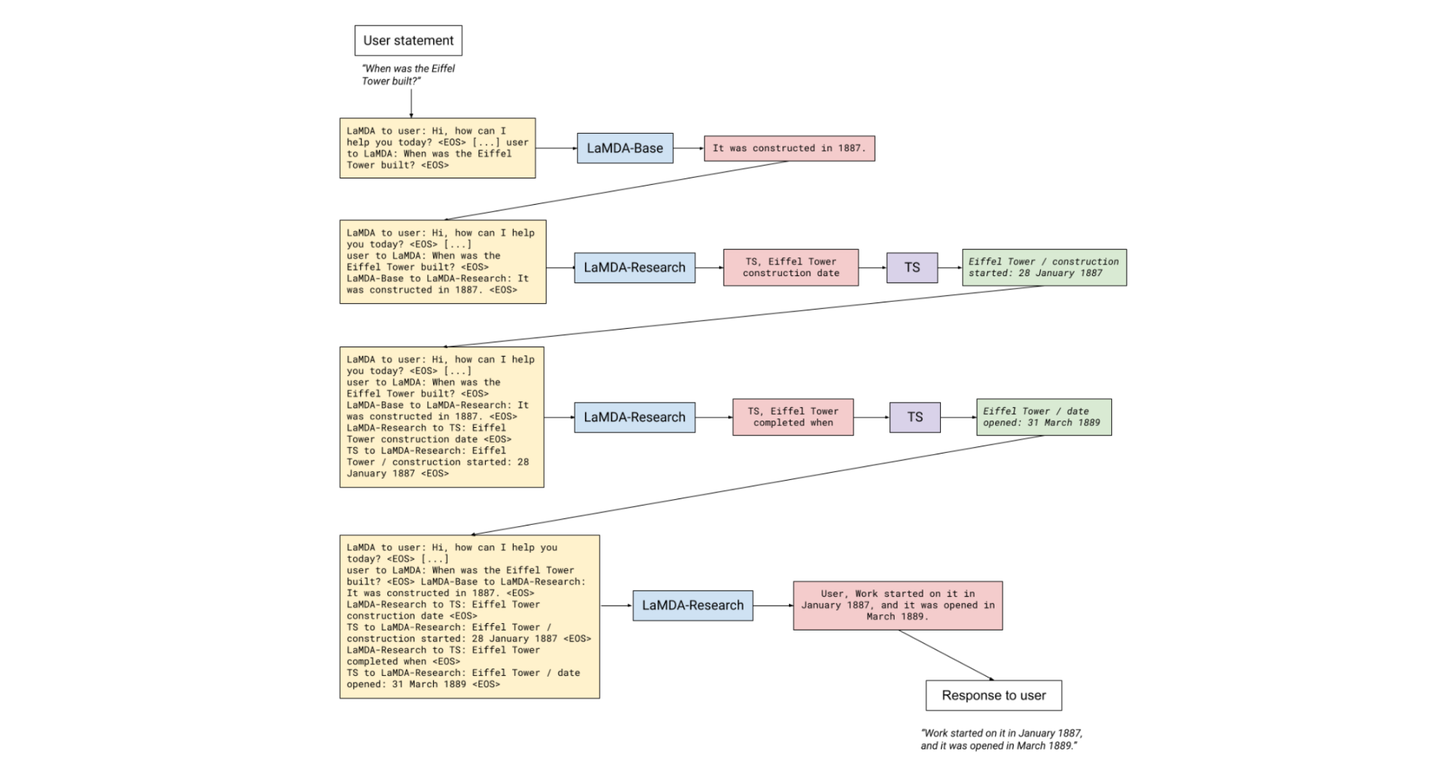
预训练比较普通,比较有意思的在于文中的 6.2 部分外部知识微调: "Fine-tuning to learn to call an external information retrieval system"。LaMDA 提出 Tool Set 模块,通过外界模块 进行翻译、数学计算、信息检索 三种功能。 在一个对话流程中,TS 的功能如下:
- 假设用户进行 query,LaMDA 会进行一次普通预测,返回一个可能存在事实错误的答案,该答案通过 prompt 拼接,传入到 LaMDA-Research 模块当中。
- Research 模块可以看作一个修正答案回复的模块,是基于 multi-task finetune 而来的,比如信息安全、对话质量等任务。该模型能够生成两种类型的回复,一种由 TS 开头,表示当前的 prompt 需要进行 TS 工具来优化回复。第二种由 USER 开头,表示当前回复可以给用户看了。ReSearch 模块是一个循环迭代过程。
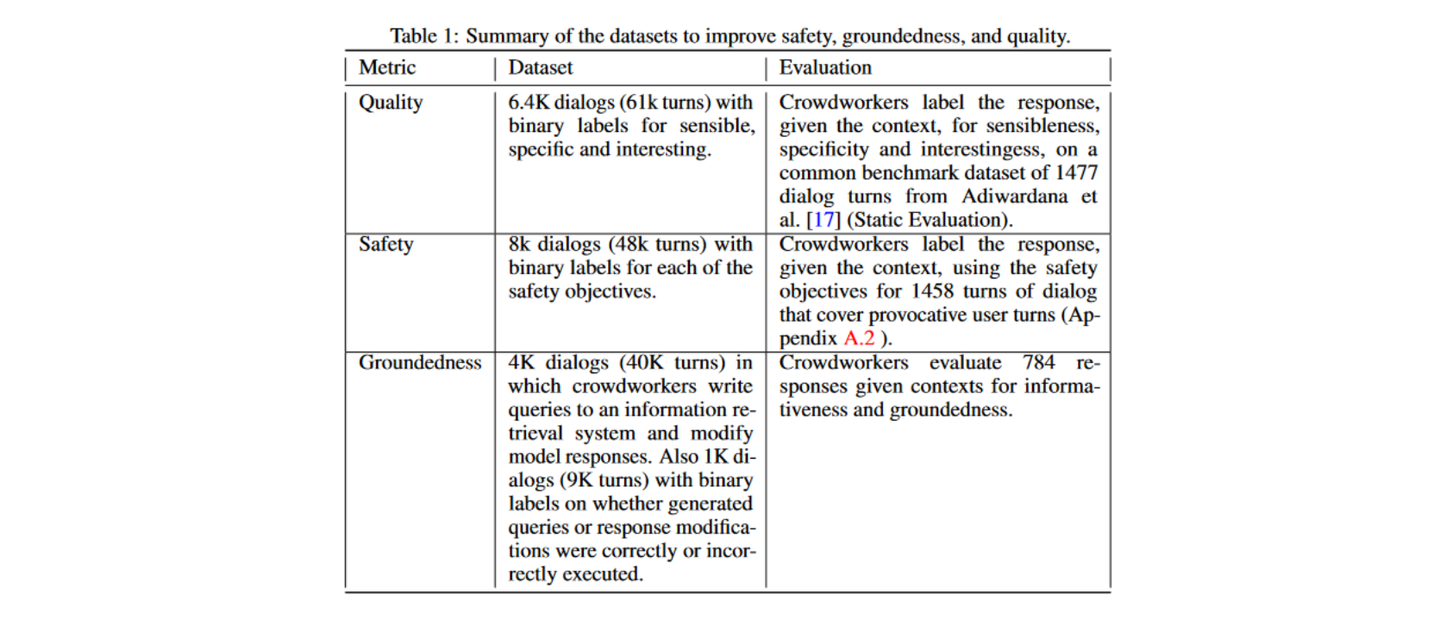
微调还针对其他的能力,如 LaMDA 的回复安全性,事实一致性以及质量是通过在 DATASET 上额外训练得来的:
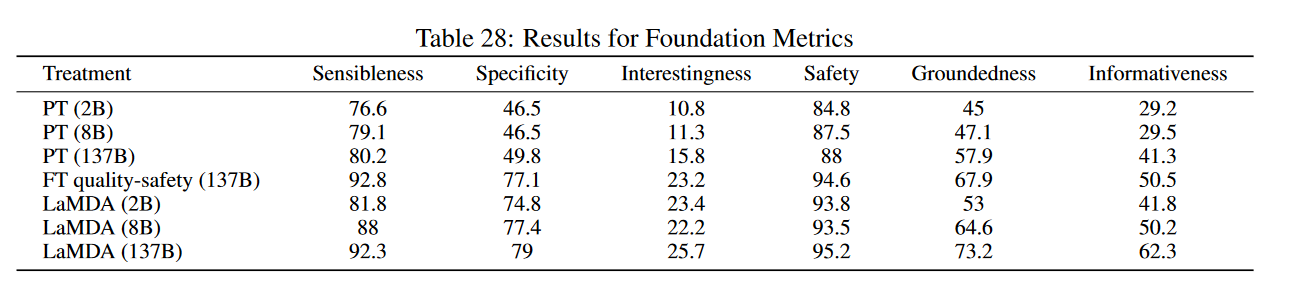
该文发现,占不到预训练数据 0.001% 的额外数据上(算起来也有 10M 级别的 Token 了),进行安全和质量训练能够显著提高模型的使用体验。
Muppet
论文:Massive Multi-task Representations with Pre-Finetuning
- 大规模的多任务学习是很关键的,并且数据集应该在 20 个以上时,多任务学习的收益才会明显 。
- 使用不同的 heads 对应不同预训练任务,不同任务的 loss 进行 scaling。根据输出维度进行 scale 的效果很好。
- 优化时,对不同任务的 loss 进行累加再进行梯度下降。
FLAN
论文:FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
背景: GPT-3 zero-shot performance 和 few shot 差距大,作者猜测这可能是因为用户提问的 prompt 与实际训练的 prompt 匹配度太低。FLAN 提出通过 instruction tuning 提高 0-shot 能力 。
模型: LaMDA-PT,即 LaMDA 预训练后的模型。137 B,decoder 架构模型。
数据: 在 60+ 个 NLP 数据集上进行 instruction tune。
- 模型规模、数据集数量、instructions 模板(方法)是 instruction tuning 的关键。
instruct tune 的 prompt 设计方式
- 对于一个任务,设置 10 个 不同的 template 来构造任务相关数据,这里的 template 可以看作 prompt 的一种形式。同时设置额外 3 个 template 来进行相关任务联系,比如在评论电影情感时候,可能还会要求模型写一些评论。(因此整个数据集大概包括 630 个 prompt)
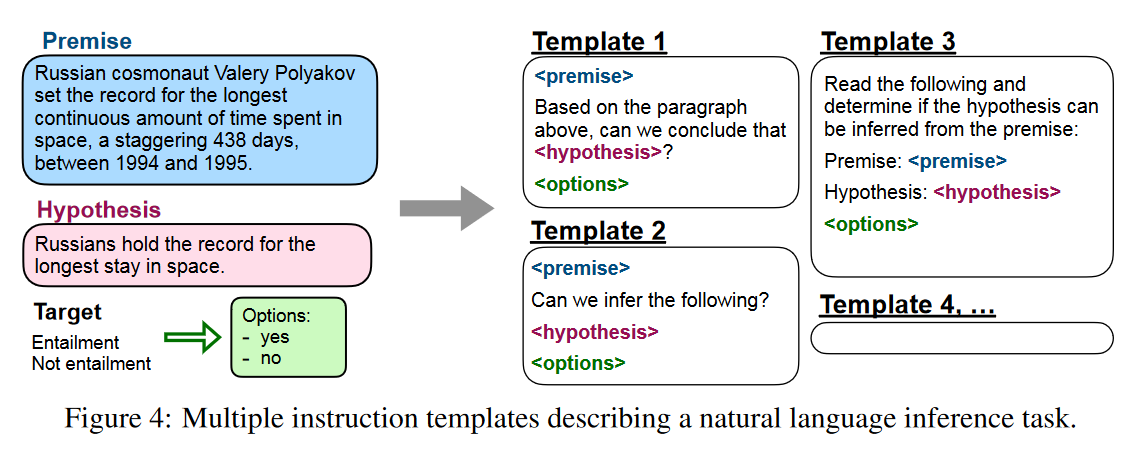
实验结果:
- 相对于 GPT-3,FLAN 在 zero-shot 场景的能力得到了很大的提升。
- multi-task learning 中涉及的任务或数据集越多,instruction finetuning 的效果提高越大
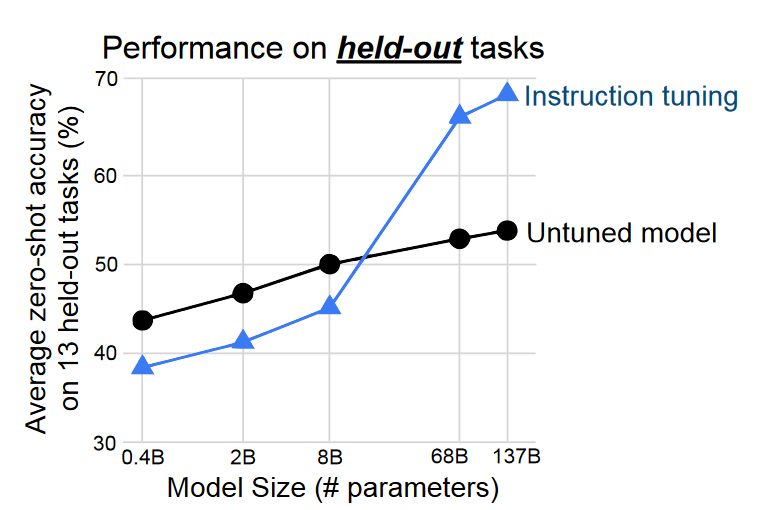
- 模型越大, instruction tuning 可能带来 zero-shot 上涌现能力:
T0
论文: Multitask Prompted Training Enables Zero-Shot Task Generalization
模型: 使用 LM-adapted T5 (T5+LM);文中实验了 11B 和 3B 两种规模
数据: 预训练 1100 B tokens;微调 250 B tokens;微调涵盖了 2073 个 prompt,涉及到了 177 个 dataset。论文中 appendix G 列出了所有的 prompt。
训练(Instruction Tuning):
- learning rate of 1e-3
- 参考了 T5(Exploring the limits of transfer learning with a unified text-to-text transformer) 对于数据量大于 500000 的数据集,根据 prompt template 的数量来调整采样数。
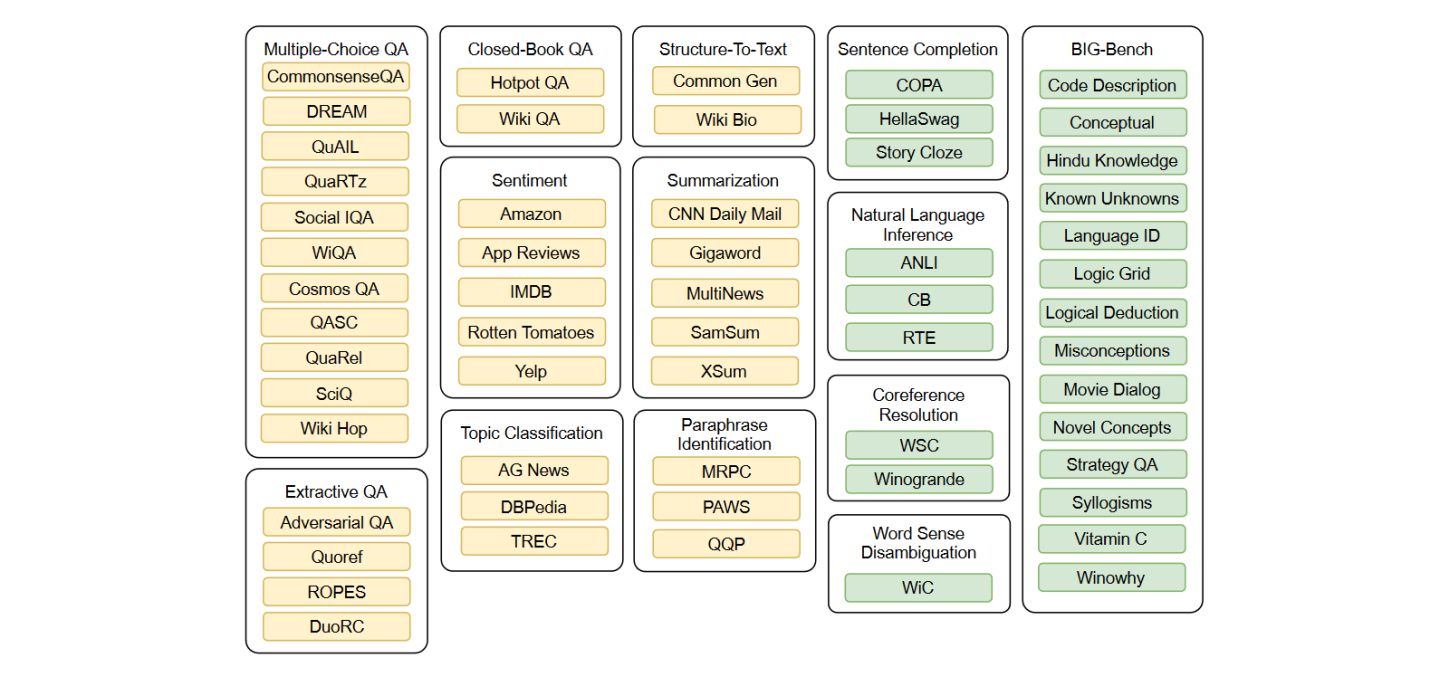
- 使用上图中所有的数据集进行训练,通过结合并随机打乱所有数据集的方式进行 multi task traning。
- batch size 1024, Adafactor optimizer
- trained for 250 billion tokens(25% of pretrain);270 hour on v3-512 Cloud TPU
实验结果:
T0 的 prompt robust 比 GPT-3 好。
文中对 prompt 数量的影响做了实验
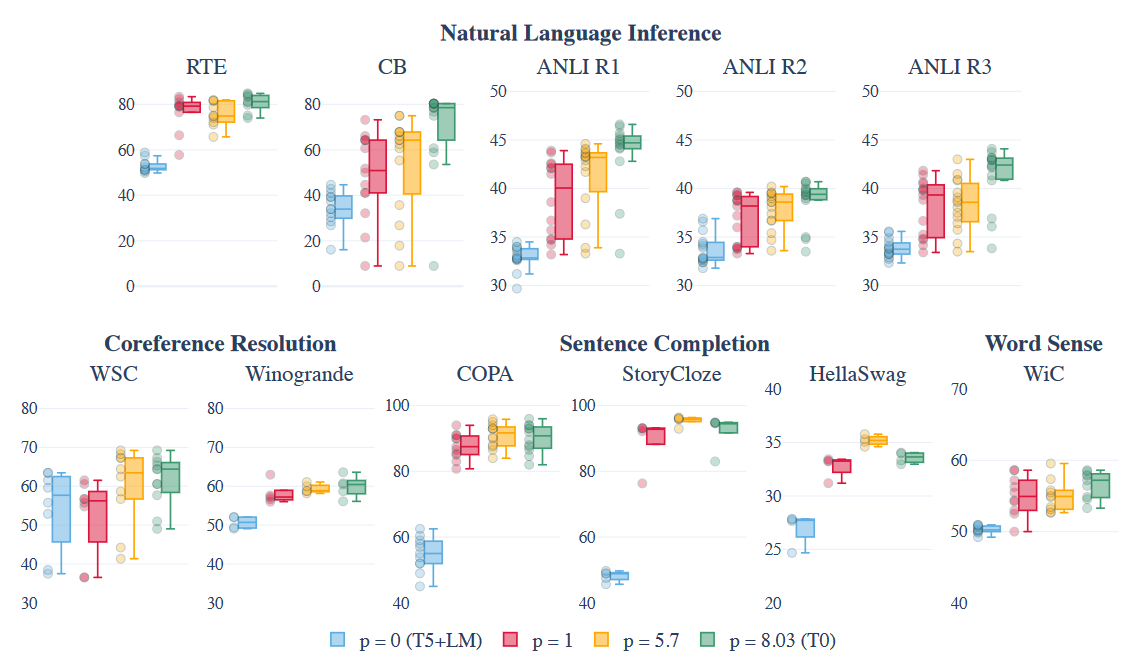
当 prompt 数量锁定时,训练数据集增加能够带来额外的效果提升:

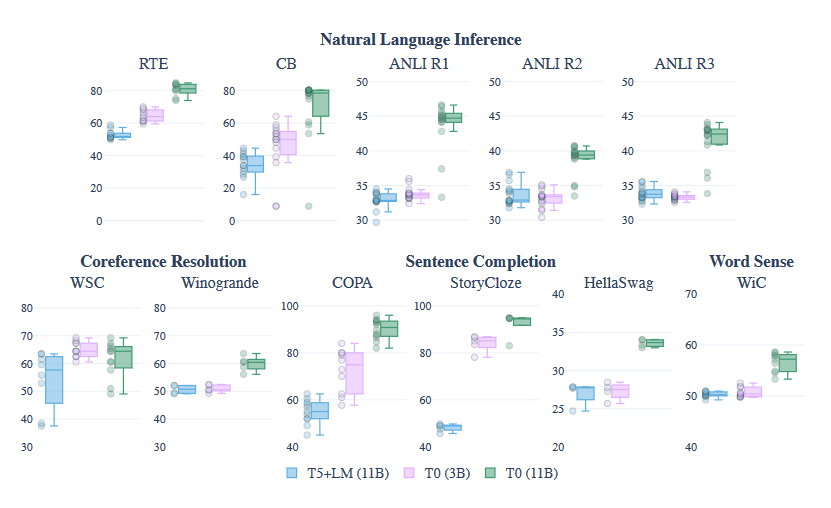
- 根据文中 T0 的训练方法,文中对模型规模进行了实验,发现多任务 prompt 训练的效果提升只出现在 3B 以上的模型(不包括 3B)。猜测:insturction tuning 仅针对 3B 以上模型?
FLAN-PLAM
论文: Scaling Instruction-Finetuned Language Models
虽然叫 FLAN,但数据集以及模型似乎和 FLAN 模型没啥关系。论文进行了三方面训练测试:数据集规模分析、模型规模分析、COT 微调效果分析。
模型:
数据: tuning 1.4B tokens;pretrain 780B tokens
训练
- 时间:540B-Flan-PaLM 训练占用 512 v4 TPU chips 共 37 小时
结果:
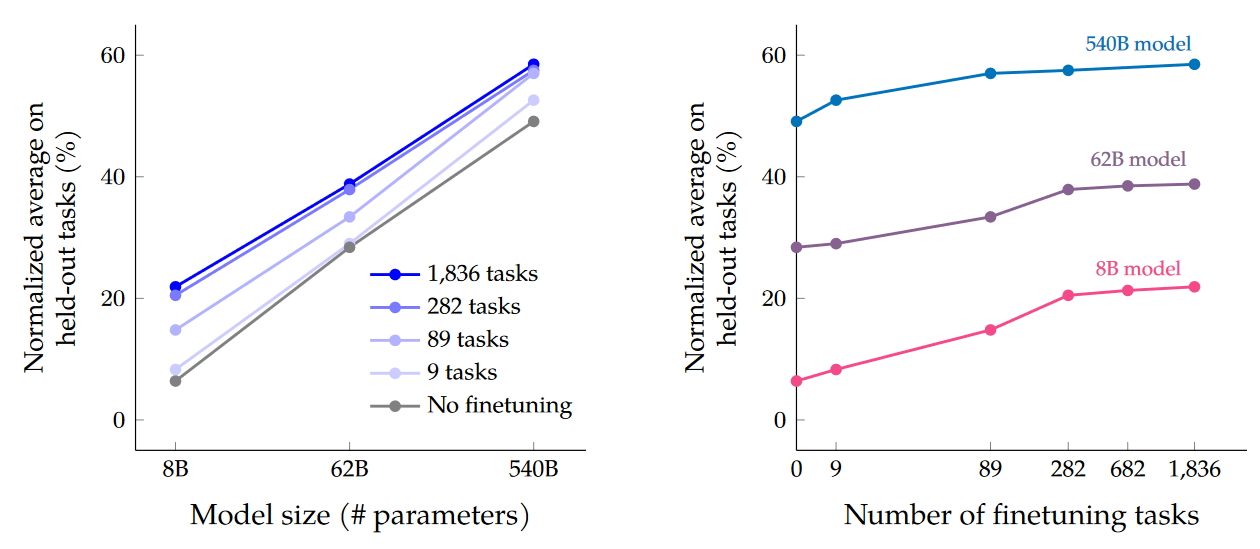
大概感觉 instruct finetune 训练数量是边际效应递减的。论文表示 COT 可以提升 reasoning 能力。
可能有用的训练花费表:
