妙鸭=SD + Lora? 对 SD+LoRA 的一些探索与验证
妙鸭的热度过了一阵子了,网上对妙鸭背后的实现逻辑有这种各样的猜测,不少网友认为妙鸭只是简单的采用 SD + Lora。本文主要对 SD + Lora 方案进行探索,分析妙鸭采用 SD + Lora 方案的可能性。
环境准备
推荐使用现有的 GUI AUTO1111/stable-diffusion-webui 。安装指南可以参考官方仓库下的安装方案,或者其他网友笔记,比如 AUTOMATIC1111/stable-diffusion-webui 安装教程_咔!哈!的博客-CSDN 博客 。
数据准备
收集图片
大约 16 张图片。图中人物的风格尽量不同,图像的长宽大小没有要求,尽量像素高一点。
图像人物裁剪
在训练 lora 的过程中,我们希望尽可能减少背景带来的影响。可以通过目标检测等技术对图像进行裁剪:

当图中有多个人物时,使用目标检测自动裁剪会有点小复杂。因此我们尽量似使用单人照片进行处理。当然,如果只是想要训练个人 LORA 的话,手动对 16 张照片进行裁剪一下就行。
图像质量提升
对于 lora 训练,图像像素最好在 (512,512)以上。对于像素低的照片,可以使用一些算法来对图像进行优化(细节优化,分辨率提升等),如 ESRGAN,LDSR,R-ESRGAN 4x+等。我们采用 R-ESRGAN 4x+ 对图像进行优化。可以使用 AUTO1111 中 EXTRA 一栏下的 scale 工具,一键对图像进行处理:
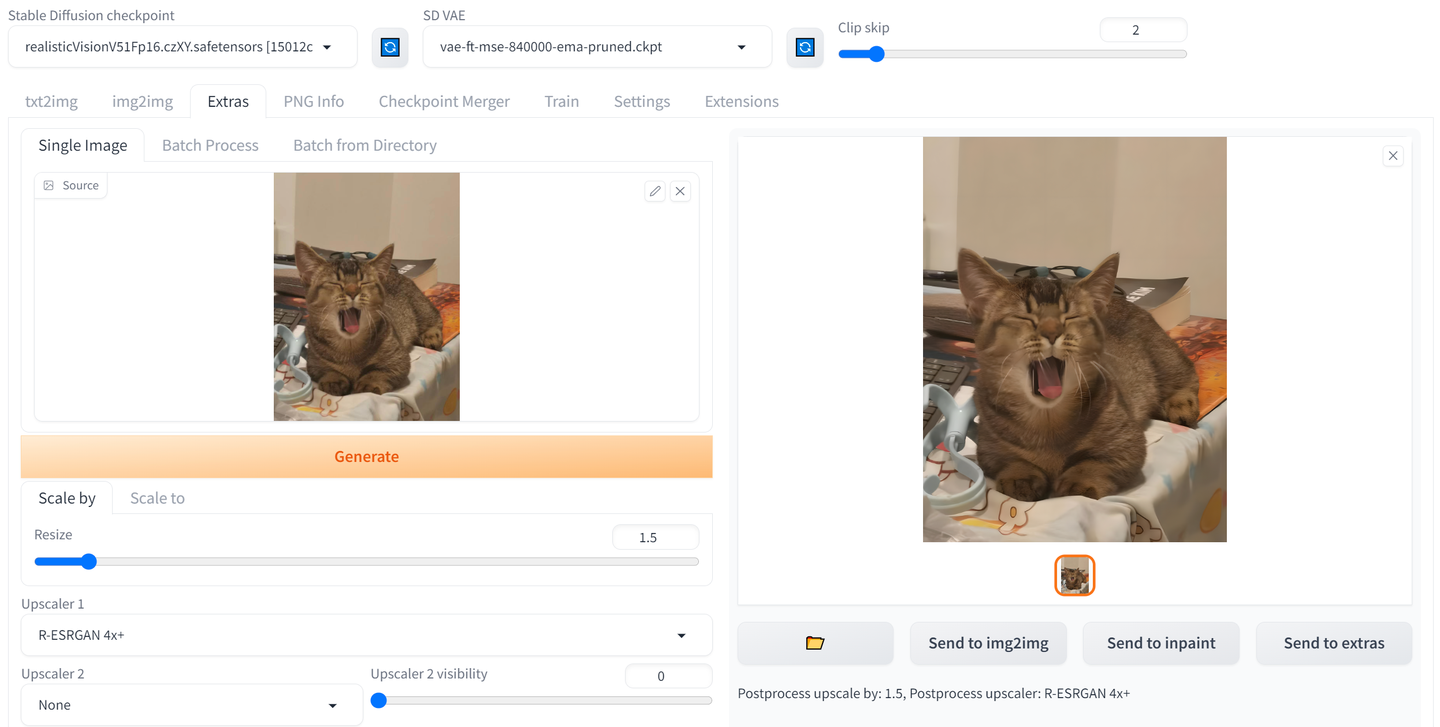
scale 前后效果对比(左图为优化后的结果):

也可以采用 stable-diffusion 中 img2img 等功能,生成提升图片的质量。
Caption
我们需要为每张图片写一句 prompt,用于 Lora 的训练。 Caption 过程中的一些小贴士:
- 假设你要训练某男子的 Lora,那么所有的 prompt 中添加上相同的人物触发词,比如姓名或者拼音。触发词应该尽量独特,比如你要训练的人物名叫 coffee,那么训练时应尽量避免使用 coffee 这个容易混淆的词汇。
- 来自网友的意见:prompt 当中,应该避免提及到自定义人物的特点。比如自定义人物是某男子,那么就不要再 prompt 当中提到 man,black hair 等词。于此相反的,不属于该男子的特征应该尽量被提及(比如衣服的颜色,造型等等)。比如该男子平时穿衣风格丰富,但你提供的照片中,他总是穿着一件蓝色的 T shirt,那么 prompt 当中应该提及 blue T shirt。
该过程可以人工写,当然也可以使用 CLIP 工具进行实现。比如 AUTO1111 里 img2img 一栏,提供了 Interrogate CLIP,可以针对每个图片进行 caption。
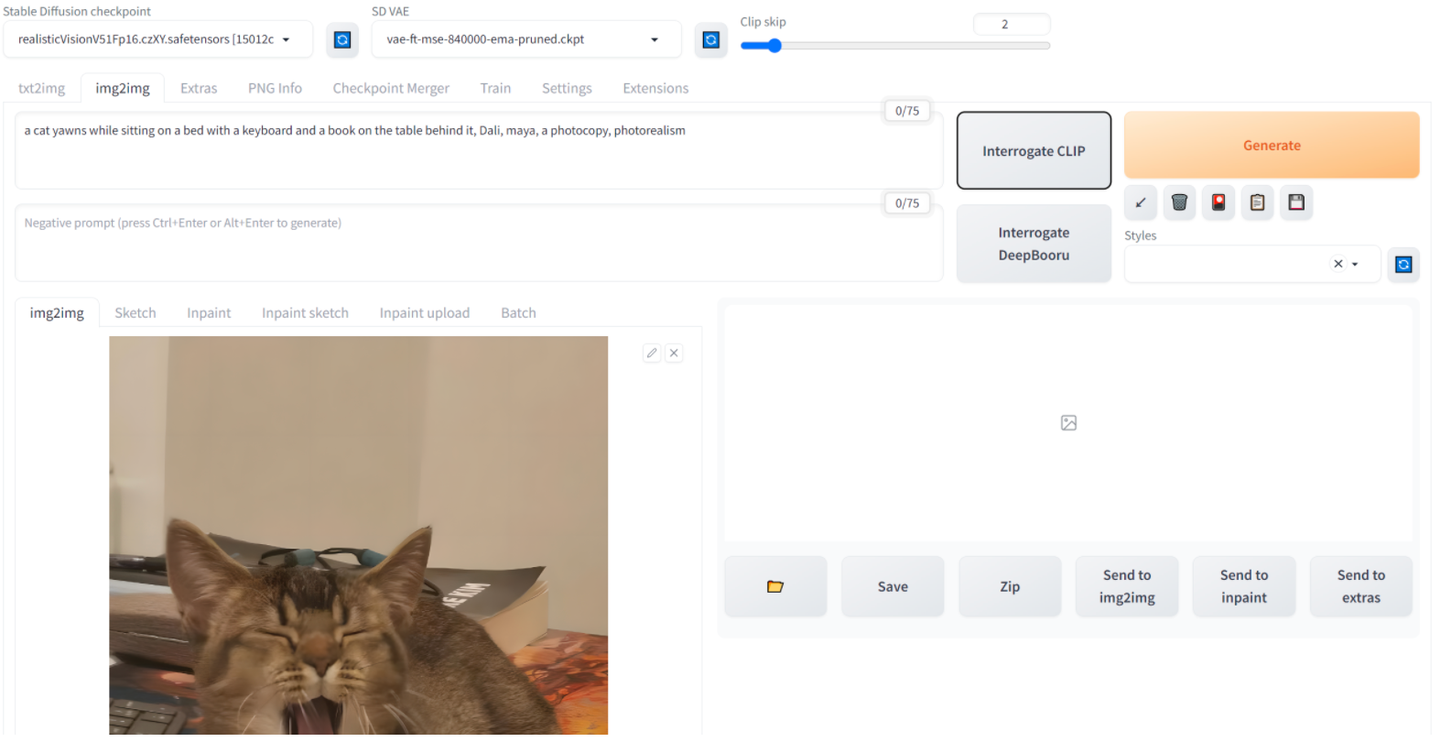
此外,可以采用如 kohya UI - utils 中的 BLIP Captioning。通常会将图像 img_1234.jpg 对应的 prompt 储存在 img_1234.txt 文件中。
Lora 训练
以下使用 kohya_ss 脚本进行训练(安装参考)。 kohya_ss 提供了训练代码,但使用代码前,需要先将图像储存在对应文件夹内:
训练文件夹准备
└── abcboy
└── 100_abcboy # 文件夹命名为 {repeat}_{folder_name}
├── image_01.png # 文件夹下放置图片
├── image_01.txt # 还有图片对应的 prompt
└── ....
参考以上文件夹结构,其中我们需要将图片和储存 prompt 的 .txt 文件放在名为 {repeat}_{folder_name} 的文件夹下,其中 repeat 为每张图片重复的次数,比如设置 repeat 为 100 时,假设文件夹下一共有 16 张图片,那么训练过程中每个 epoch 会训练 16 * 100 张图片。
开始训练
经过几次调参后,以下参数效果相对理想。其中:
- pretrained_model_name_or_path:建议选择 runwayml/stable-diffusion-v1-5。有个 trick,个人尝试,如果使用 realisticVision checkpoint 进行图片生成,在 realisticVision checkpoint 上微调的 lora,效果不如在 SD-1.5 上微调的,不确定是什么原因。
- train_data_dir:选 abcboy 而不是 100_abcboy ,参考上文提到的训练文件夹准备。
- network_alpha 和 network_dim:个人测试 alpha=128, dim=128 与 alpha=8, dim=8 VRAM 占用及训练时长差不多,但 128 效果好很多。
- learning_rate 及 lr_scheduler:学习率参考了 How to Create a LoRA Part 2: Training the Model
- clip_skip:个人测试,clip_skip=2 相对 clip_skip=1 效果好一点。
- batch_size:batch size =2 算是一种权衡。由于我们数据集较小,batch size 过大会导致梯度更新速度太慢。
accelerate launch --num_cpu_threads_per_process=2 "/workspace/kohya_ss/train_network.py" \
--enable_bucket --min_bucket_reso=256 --max_bucket_reso=2048 \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--train_data_dir="/workspace/abcboy" --resolution="512,512" \
--output_dir="/workspace/stable-diffusion-webui/models/Lora" \
--logging_dir="/workspace/logs" --network_alpha="128" \
--save_model_as=safetensors --network_module=networks.lora --text_encoder_lr=5e-05 \
--unet_lr=0.0001 --network_dim=128 --output_name="abcboy_v1.0" \
--lr_scheduler_num_cycles="1" --no_half_vae --learning_rate="0.0001" \
--lr_scheduler="constant" --train_batch_size="2" \
--max_train_steps="800" --save_every_n_epochs="1" --mixed_precision="bf16" \
--save_precision="bf16" --seed="1234" --caption_extension=".txt" --cache_latents \
--optimizer_type="AdamW8bit" --max_data_loader_n_workers="1" --clip_skip=2 \
--bucket_reso_steps=64 --xformers --bucket_no_upscale --noise_offset=0.0
个人在本地 4090 运行,整个训练过程大约耗时 90 秒,VRAM 占用 7GB。
效果测试
我们将训练好的 lora 权重保存在 AUTO1111 的 lora 权重位置: stable-diffusion-webui/models/Lora 下,而后通过 AUTO1111 webui 来进行简单的生成测试。
以下是个人使用生成图片的配置:
- checkpoint 使用 realisticVision checkpoint 的效果,会比使用 SD1.5 效果好很多(尽管我们的 lora 是在 SD1.5 上训练的)
- SD VAE 采用 vae-ft-mse-840000-ema-pruned.ckpt
- sampling method 采用 DPM++ SDE Karras
- Clip Skip=2,width=512, height=768
- prompt 中,可以通过改动 prompt 来修改图片风格,建议添加上 realisticVision checkpoint 推荐的 prompt:
- prompt: RAW photo, subject, 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
- negative prompt: (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime), text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, UnrealisticDream
个人在本地测试,使用 16 张图片训练的 lora,能够生成与训练集人物相似的形象照:

生成照片还有一些瑕疵(比如手,头发等),可以考虑使用一些其他 lora 或者 embedding 来完善。
妙鸭的一些想法
如果使用 SD + Lora 训练方案,搭建一个类似妙鸭的服务,那么根据实验的信息: 在单卡 4090 上用 16 张图片训练 LORA,只需要 90 秒不到,并且生成效果不错。
而其他的图像处理流程,如图像生成,超分,人脸匹配,目标检测等,加起来也不到 90 秒。 因此我们可以判断,用一台 4090,单独服务一个客户只需要 3 分钟即可,大致一小时可以服务 20 个客户。
参考网友贴出的秒鸭排队情况:
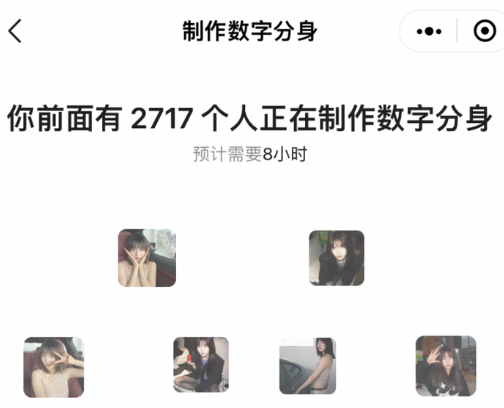
如果秒鸭采用了 LORA 训练的方案实现的话,部署 16 台 4090 ,8 小时可以服务约 2560 人。每个用户的训练和推理成本约为 0.15 元(参考 GPU 市场租赁价格,如 AUTODL 或恒源云,一小时 4090 价格约 3 元)。由于训练 LORA 以及推理过程中,实际只需要 7GB 的显存,因此每台 4090 可以部署多个实例。
资源
可以考虑叠加其他风格的 lora 生成不同类型的艺术照:
当使用 realisticVision 效果不佳时,可以考虑换一下 checkpoint 比如 majicMIX 或 Beautiful Realistic Asians
参考
How to Create a LoRA Part 1: Dataset Preparation
How to Create a LoRA Part 2: Training the Model
Generate Studio Quality Realistic Photos By Kohya LoRA Stable Diffusion Training:
First Ever SDXL Training With Kohya LoRA - Stable Diffusion XL Training Will Replace Older Models: