混合精度训练
混合精度训练,短短的几行代码,在节省显存占用 40%+,训练速度翻倍的前提下,能够做到模型准确率几乎不减少!强烈推荐阅读这篇只有 9 页的文章:MIXED PRECISION TRAINING 。
快速开始
在 AMP (自动混合精度训练)提出的一开始,大家使用的都是 NVIDIA 的 apex 库实现。后来各大深度学习平台纷纷添加了自带的 AMP API,如 tf,torch,paddle 等。
在 apex 中:
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
在 torch 中::
with torch.cuda.amp.autocast():
output = net(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
在 paddle 中:
from paddle.amp import GradScaler, auto_cast
if self.fp16:
scaler = GradScaler(init_loss_scaling=self.scale_loss)
with auto_cast(enable=self.fp16,
custom_white_list=["softmax", "gelu"]):
# 此处可以选择混合精度模式 O1,O2 等,默认仅对部分线性层进行 FP16 转换,可以添加白名单来支持其他层的 FP16
loss = model(**inputs)
loss = loss / self.gradient_accumulation_steps
losses += loss.detach() # losses for logging only
if self.fp16:
scaled = scaler.scale(loss)
scaled.backward()
else:
loss.backward()
if step % self.gradient_accumulation_steps == 0:
global_step += 1
if self.fp16:
scaler.step(optimizer)
scaler.update()
else:
optimizer.step()
optimizer.clear_grad()
lr_scheduler.step()
三个要点
混合精度意在提高计算密集型任务的效率,因此模型训练的 IO 瓶颈是无法通过该方案解决的。混合精度训练能够极大的提高模型训练速度,同时保留几乎 99%的训练精度。
精度在哪丢失
计算方式
关于 FP16 的储存格式等,可以参考 wiki 百科。
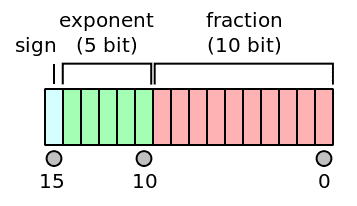
FP16 的计算方式如下:
| Exponent | Significand = zero | Significand ≠ zero | Equation |
|---|---|---|---|
| zero, −0 | subnormal numbers | ||
| normalized value | (−1)signbit × 2exponent−15 × 1.significantbits2 | ||
| ±infinity | NaN (quiet, signalling) |
通过几个例子说明:
| Binary | Hex | Value | Notes |
|---|---|---|---|
| 0 00000 0000000000 | 0000 | 0 | |
| 0 00000 0000000001 | 0001 | smallest positive subnormal number | |
| 0 00000 1111111111 | 03ff | largest subnormal number | |
| 0 00001 0000000000 | 0400 | smallest positive normal number | |
| 0 01101 0101010101 | 3555 | nearest value to 1/3 | |
| 0 01110 1111111111 | 3bff | largest number less than one | |
| 0 01111 0000000000 | 3c00 | one | |
| 0 01111 0000000001 | 3c01 | smallest number larger than one | |
| 0 11110 1111111111 | 7bff | largest normal number | |
| 0 11111 0000000000 | 7c00 | ∞ | infinity |
| 1 00000 0000000000 | 8000 | −0 | |
| 1 10000 0000000000 | c000 | -2 | |
| 1 11111 0000000000 | fc00 | −∞ | negative infinity |
从上表不难发现, FP16 的计算存在几个默认规则:
- exponent 或 fraction 为 0 时 存在特定计算方式。
- 当 exponent 不为 0 时,默认 fraction 部分有一个 1。这是后 fraction 部分的总精度将是 11 个 bit 而非图上给的 10 bit。
舍入误差
由于浮点数的特性,FP16 在两个相邻的,能够被 FP16 表达的数值之间存在一定的间隔,当计算数值存在于间隔之中时,运算将会出现舍入误差。
如 FP16 中 ,而 ,由于 的最小间隔为 ,因此 将在这次相加中丢失。
精度溢出
FP16 取值范围是 5.96× 10−8 ~ 65504,而 FP32 则是 1.4×10-45 ~ 3.4×1038。由 FP32 转到 FP16 存在下溢出与上溢出。对于下溢出,数值将被置为 0;对于上溢出,可能出现 NAN 或者无穷数。
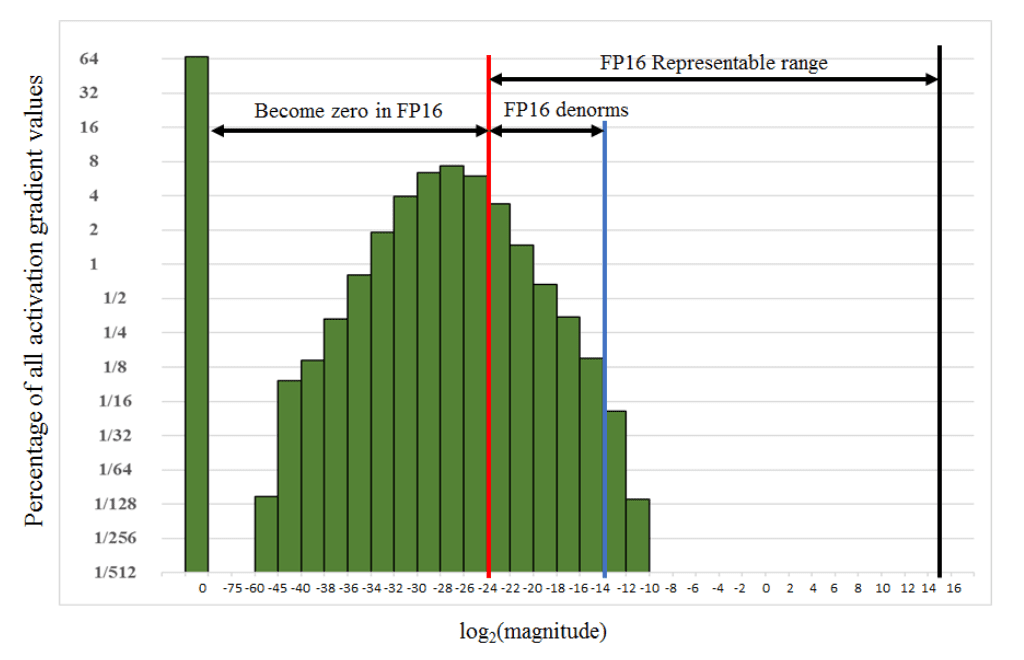
上图为 SSD 训练过程中激活函数数值分布图。可以发现大部分的计算数值在 FP16 中会被置 0。
如果直接将 FP32 的模型全部采用 FP16 保存,那么模型的训练效果将大打折扣。因此,混合精度训练的要点在于,如何最小地避免精度丢失:
保存模型的 FP32 主权重副本
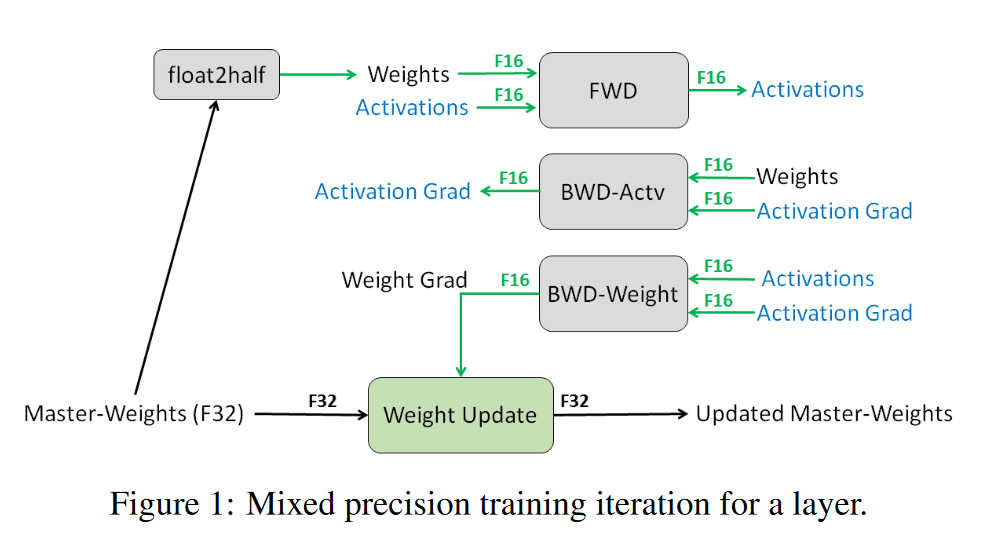
如上图所示,在传导过程中使用 FP16,然后使用 FP32 接受更新的梯度以及保存模型,因此我们需要同时保存模型 fp32 以及 fp16 的版本。
尽管保存着两种权重样本,这理论上会增加 50%的显存占用。但实际上,我们训练起来后会发现显存占用大大减少,因为训练中大部分的显存占用存在于激活函数的计算中。
由于混合精度训练 O1 模式下通常可以指定白名单,因此笔者在训练某 NLP Transformer Encoder 架构模型时,对激活函数进行了混合精度训练测试,下面为测试结果。
当我们将 softmax 以及 gelu 等激活函数采用 FP16 计算时,显存才开始大大降低。当仅对线性层等采用 fp16 计算后,虽然显存没有明显的降低,但计算速度也得到了很大的提高。
| 是否混合精度训练 | 白名单(额外应用 fp16 的层) | time/batch | 显存占用/batch |
|---|---|---|---|
| 否 | - | 1.875s | 1.68GB |
| 是 | - | 0.9375s | 1.625GB |
| 是 | softmax | 0.565s | 1.3GB |
| 是 | softmax + gelu | 0.55s | 1.1GB |
loss-scaling
再看看精度溢出中的激活函数数值分布图。如果我们在反向传播之前,将 FP32 的 loss 乘以 scaler_factor,那么我们能够保证反向传播时,大部分的数值保持在 FP16 的范围内,也就是红线右边。通常这个 scaler_factor 在 8-32K 之间,或者更大。较大的 scaler_factor 是没问题的,只要不出现 FP16 的 overflowing 问题即可。
改进算数方法
计算可以分为 reduction, point-wise operations, vector dot-production 三种,前两种操作主要受内存带宽限制,因此采用 FP16 或者 FP32 影响不是很大。对于后者,部分的模型需要采用 来保留精度。原文描述是这样的:
To maintain model accuracy, we found that some networks require that FP16 vector dot-product accumulates the partial products into an FP32 value, which is converted to FP16 before writing to memory. Without this accumulation in FP32, some FP16 models did not match the accuracy of the baseline models.
训练要点
训练模式
混合精度训练通常有 O0,O1, O2, O3 模式。O0 为全 FP32 训练,O3 为全 FP16 训练,常用的是 O1, O2。
NVIDIA AMP 的默认策略就是 O2:除了 batch norm 和输入采用 FP32,其余均为 FP16。因此需要额外一个 FP32 权重来实现梯度更新。
O1 模式笔者认为更方便,其提供了黑白名单,能让设计者根据自己模型的特点来选择需要进行 FP16 的部分,如 softmax,layernorm 等。通常 O1 模式会有默认的白名单,如最常用的线性层就在白名单中。白名单中添加的模型层将强制采用 FP16 计算,黑名单中强制使用 FP32,对于剩下的层,将根据对应的输入进行判断,若输入有一个 FP32 则使用 FP32。
O1 伪代码
对于混合精度训练的细节,可以参考 NVIDAI APEX 源码。以下对整体流程最总结,内容参考与 由浅入深的混合精度训练教程
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
以上代码的运行逻辑大致为:
amp.initialize():根据黑白名单对 PyTorch 内置的函数进行包装 [4]。白名单函数强制 FP16,黑名单函数强制 FP32。其余函数则根据参数类型自动判断,如果参数都是 FP16,则以 FP16 运行,如果有一个参数为 FP32,则以 FP32 运行。
对于每次迭代(调用 scaled_loss.backward()):
- 前向传播:模型权重是 FP32,按照黑白名单自动选择算子精度。
- 将 loss 乘以
loss_scale - 反向传播,因为模型权重是 FP32,所以即使函数以 FP16 运行,也会得到 FP32 的梯度。
- 将梯度 unscale,即除以 loss_scale
- 如果检测到 inf 或 nan
loss_scale /= 2,而后跳过此次更新。 optimizer.step(),执行此次更新- 如果连续 2000 次迭代都没有出现 inf 或 nan,则
loss_scale *= 2
O2 与 O1 主要差别在于初始化方式,以及 O2 维护了额外的模型副本进行梯度更新。