Qwen 1.5/2、Llama 3 记录
Qwen 1.5 系列
发布时间:24 年 2 月。
模型大小:包括 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense 模型,以及 MoE-A2.7B 模型。
架构:32B 以上的模型用了 GQA,其他架构大致相同。
训练:
- RLHF:直接策略优化(DPO)和近端策略优化(PPO)等技术。
- 长序列:全系列支持 32K+ tokens 的上下文
数据:
- 挑选了来自欧洲、东亚和东南亚的 12 种不同语言
官方给出的评分:
| Model | MMLU | C-Eval | GSM8K | MATH | HumanEval | MBPP | BBH | CMMLU |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 86.4 | 69.9 | 92.0 | 45.8 | 67.0 | 61.8 | 86.7 | 71.0 |
| Llama2-7B | 46.8 | 32.5 | 16.7 | 3.3 | 12.8 | 20.8 | 38.2 | 31.8 |
| Llama2-13B | 55.0 | 41.4 | 29.6 | 5.0 | 18.9 | 30.3 | 45.6 | 38.4 |
| Llama2-34B | 62.6 | - | 42.2 | 6.2 | 22.6 | 33.0 | 44.1 | - |
| Llama2-70B | 69.8 | 50.1 | 54.4 | 10.6 | 23.7 | 37.7 | 58.4 | 53.6 |
| Mistral-7B | 64.1 | 47.4 | 47.5 | 11.3 | 27.4 | 38.6 | 56.7 | 44.7 |
| Mixtral-8x7B | 70.6 | - | 74.4 | 28.4 | 40.2 | 60.7 | - | - |
| Qwen1.5-7B | 61.0 | 74.1 | 62.5 | 20.3 | 36.0 | 37.4 | 40.2 | 73.1 |
| Qwen1.5-14B | 67.6 | 78.7 | 70.1 | 29.2 | 37.8 | 44.0 | 53.7 | 77.6 |
| Qwen1.5-32B | 73.4 | 83.5 | 77.4 | 36.1 | 37.2 | 49.4 | 66.8 | 82.3 |
| Qwen1.5-72B | 77.5 | 84.1 | 79.5 | 34.1 | 41.5 | 53.4 | 65.5 | 83.5 |
Qwen1.5 MOE,模型总共有 14.3 的参数,实际推理过程中,只是用到了 2.7B。
Qwen 1.5 MOE 对 Mixtral MOE 的架构进行了优化,包括 Finegrained experts,初始化,新的 routing 机制等。更多欢迎参考 https://qwenlm.github.io/zh/blog/qwen-moe/
Qwen 2 系列
架构: Dense 模型及 MOE 模型与 Qwen 1.5 对应版本的架构一样。
模型大小: 有 0.5B,1.5B,7B 和 72B 四种 dense 模型;同时还有一个 57B-A14B 的 MOE。
预训练: 训练数据 一共有 7T,包含了 30 种语言,数据中收集了更多高质量的代码、数学和多语种数据。
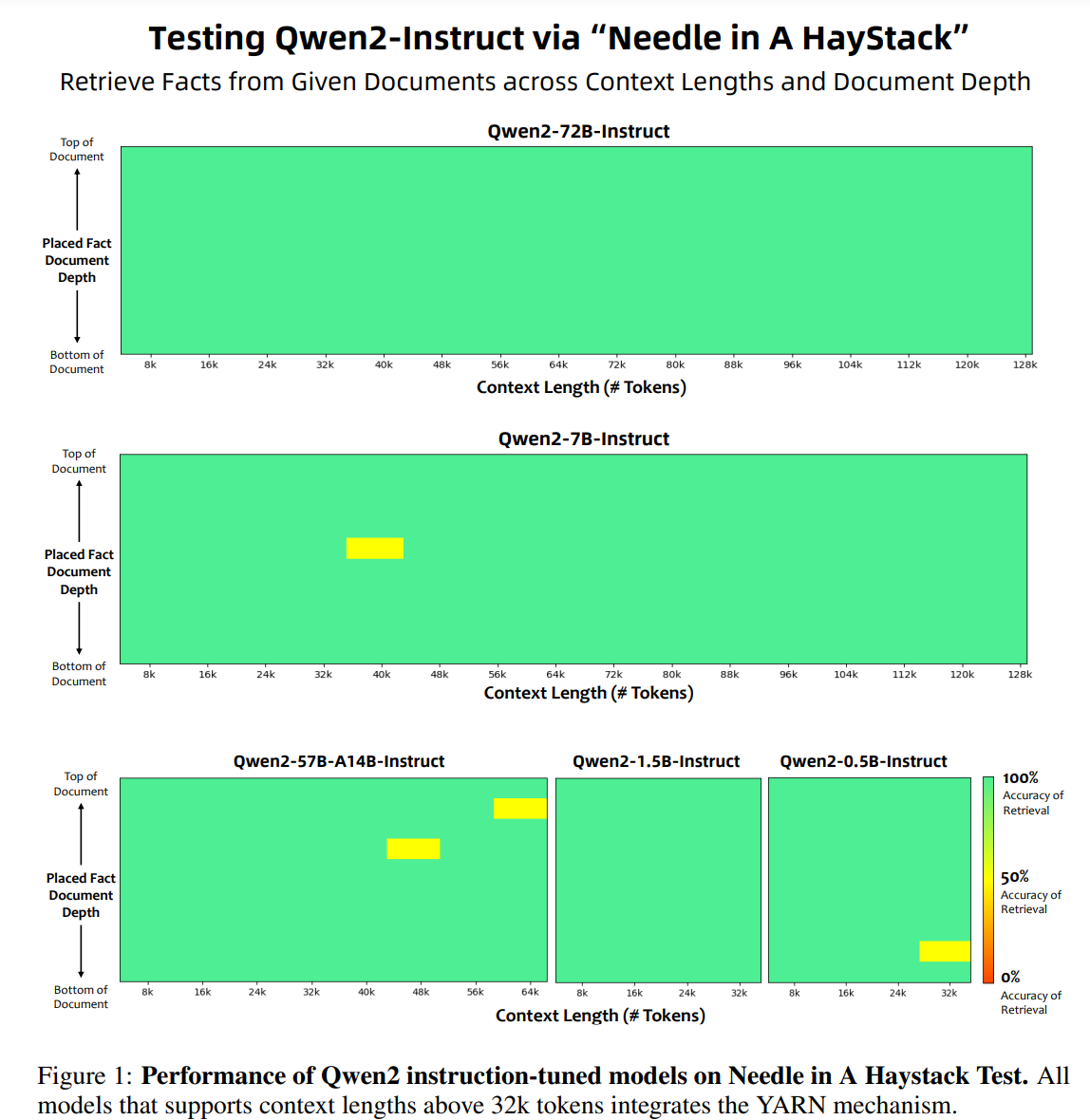
超长上下文: 先用 4096 的长度训练,而后再训练结束前,换成 32K。采用了 YARN 和 Dual Chunk Attention。以下为大海捞针评测:
SFT: 用了超过 500K 的实例进行训练,数据集中包含指令遵循,代码,数学,逻辑推理,角色扮演,安全等数据。finetune 了 2 个 epoch,训练文本长度限制再了 32K。
RLHF:
- 离线训练: 用 DPO 再标注好的偏好数据集上训练。
- 在线训练: 同样采用 DPO,同时采用 Online Merging Optimizer 来缓解对齐税。
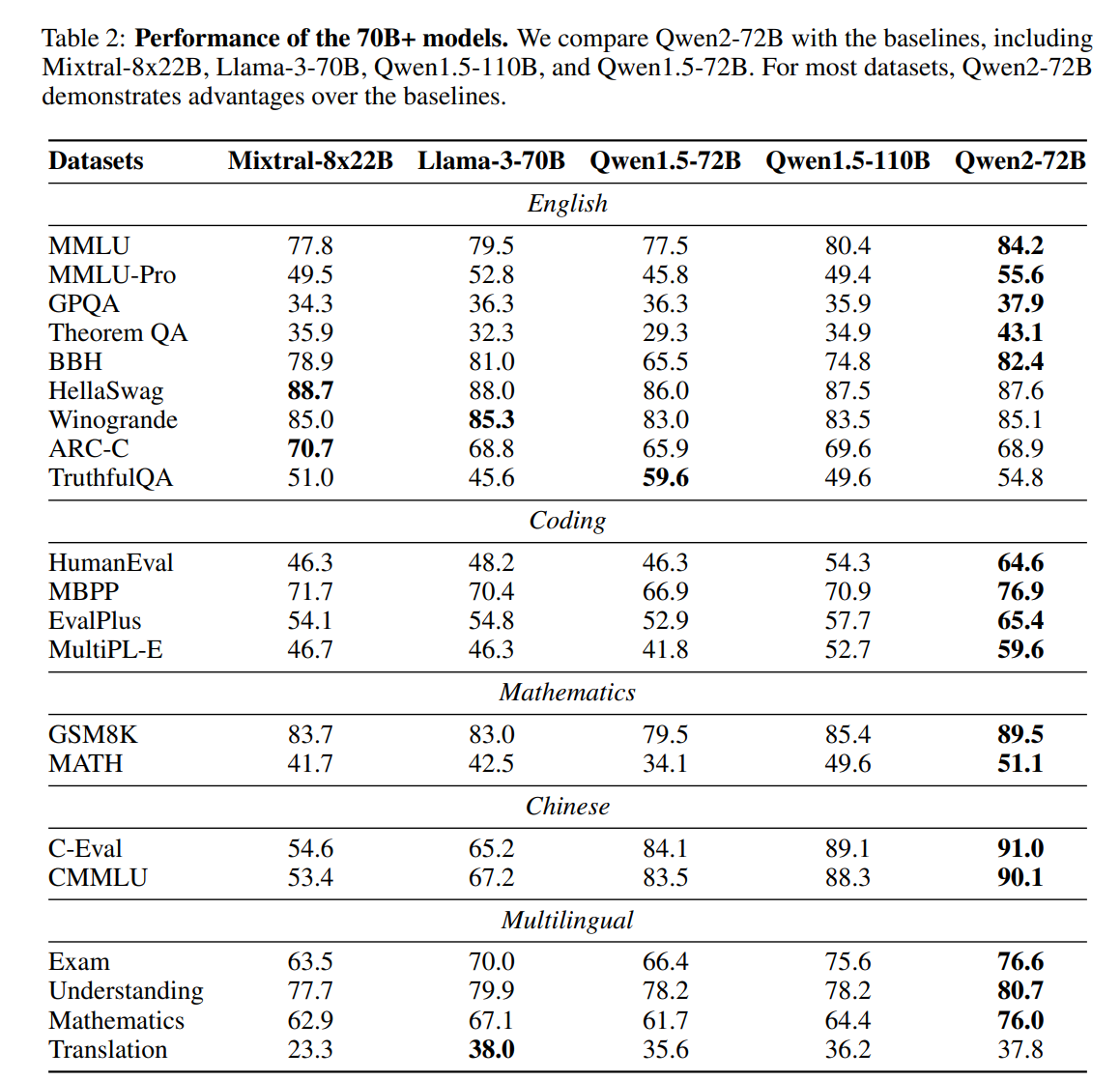
模型效果:
Qwen2 72B 效果:
Qwen2 7B 效果:
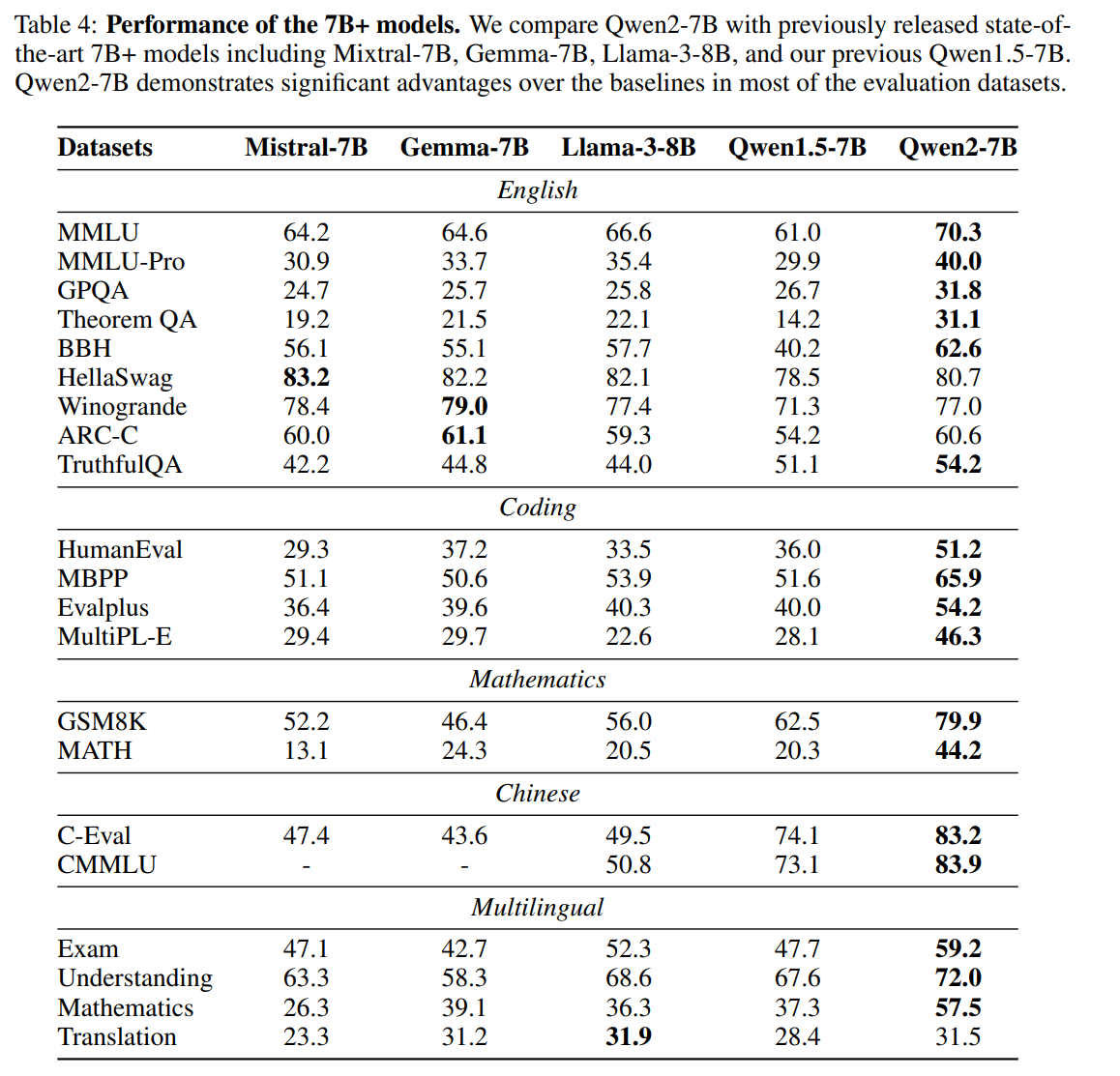
更多模型效果可以查看:Qwen2 官网
Agent 框架:
github:https://github.com/QwenLM/Qwen-Agent
参考博客:https://qwenlm.github.io/zh/blog/qwen-agent-2405/
Qwen Agent 的主要思想是:利用 agent 架构来弥补大模型上下文窗口的不足,使得 8k 上下文的模型也能够处理 1M 的上下文。
Agent 分为 3 个 Level。
Level 1 操作为:
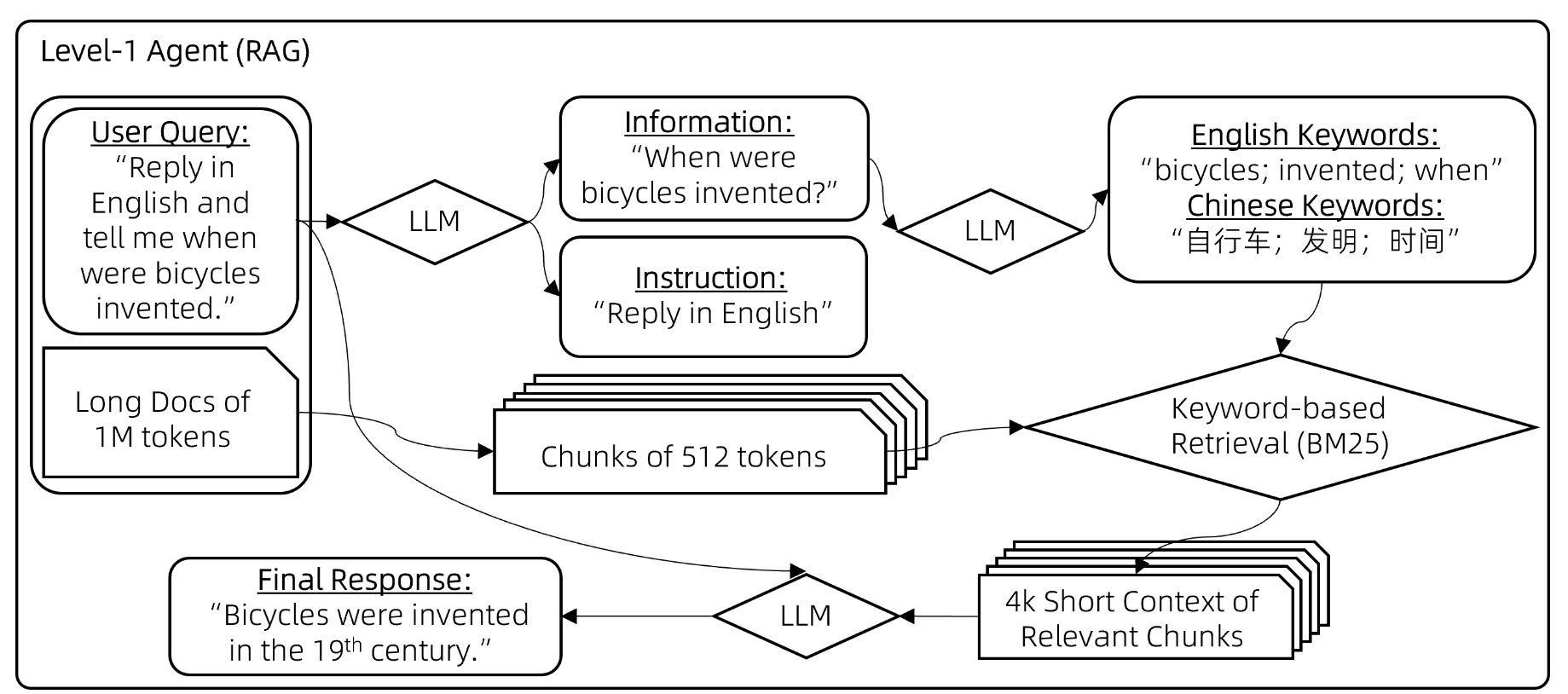
- 使用 LLM 解析用户问题,区分用户问题中的信息元素和指令;根据信息元素整合成几个关键词。
- 用 BM25 过滤出有关 chunk,而后放到 8k 的 LLM 中进行回答。
Level 2 操作为:
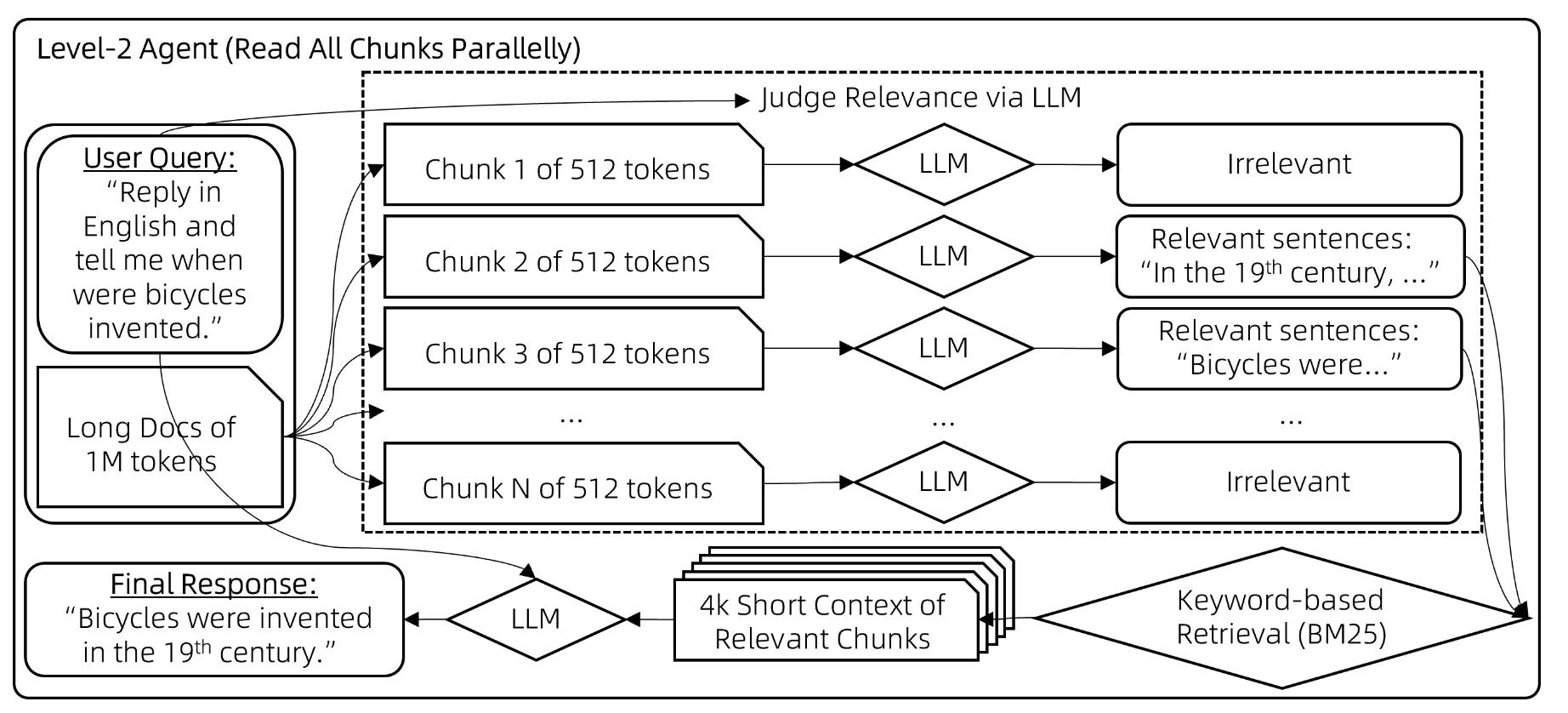
- 使用 LLM,判断用户的问题与每一个 chunk 是否相关(要进行很多次 LLM 推理)。而后保留下相关的 chunk。
- 通过 BM25,从剩下的 chunk 中进一步筛选。最后将结果放到 LLM 做进行回答。
Level 3 操作为:
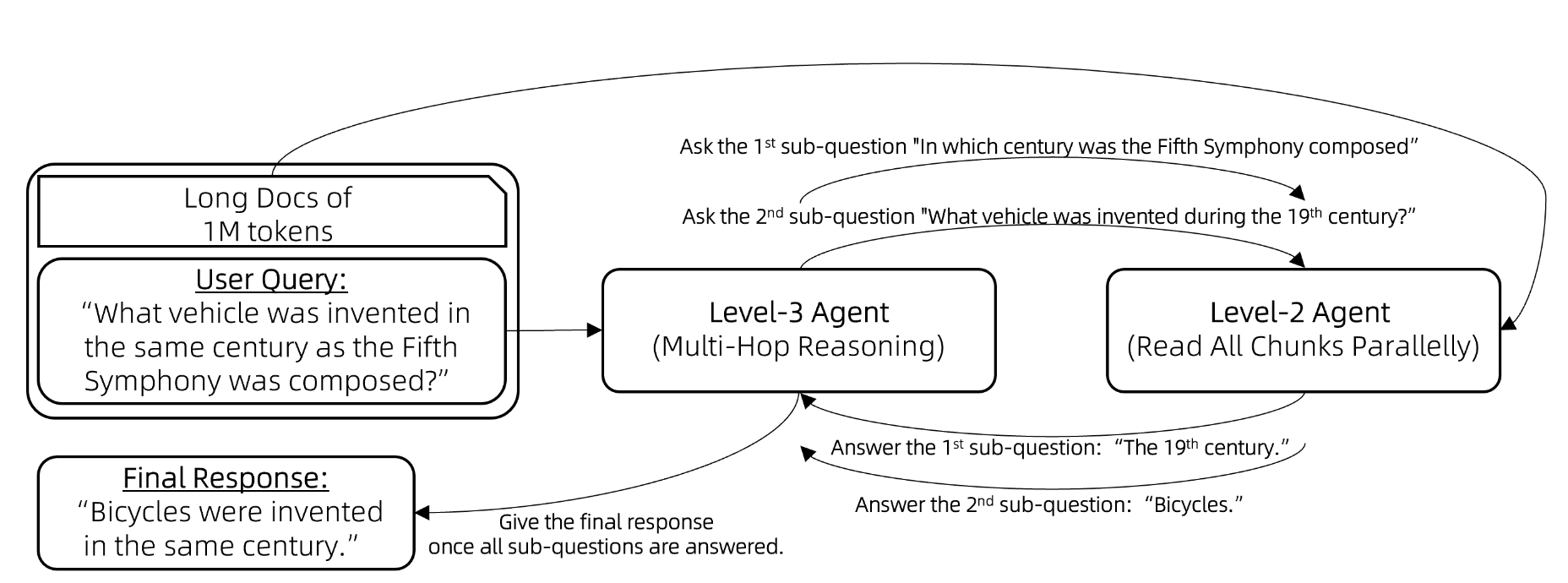
将 Level 2 智能体封装成一个工具,由 Level 3 智能体调用。
Level 3 智能体进行多跳推理的流程如下:
向 Lv3-智能体提出一个问题。
while (Lv3-智能体无法根据其记忆回答问题) {
Lv3-智能体提出一个新的子问题待解答。
Lv3-智能体向 Lv2-智能体提问这个子问题。
将 Lv2-智能体的回应添加到 Lv3-智能体的记忆中。
}
Lv3-智能体提供原始问题的最终答案。
agent 效果:
- 32k Model: 不采用策略,直接基于 RoPE 外推(无额外训练)。
- 4k RAG 采用 Level 1 策略
- 4k Agent 采用 Level 3 策略
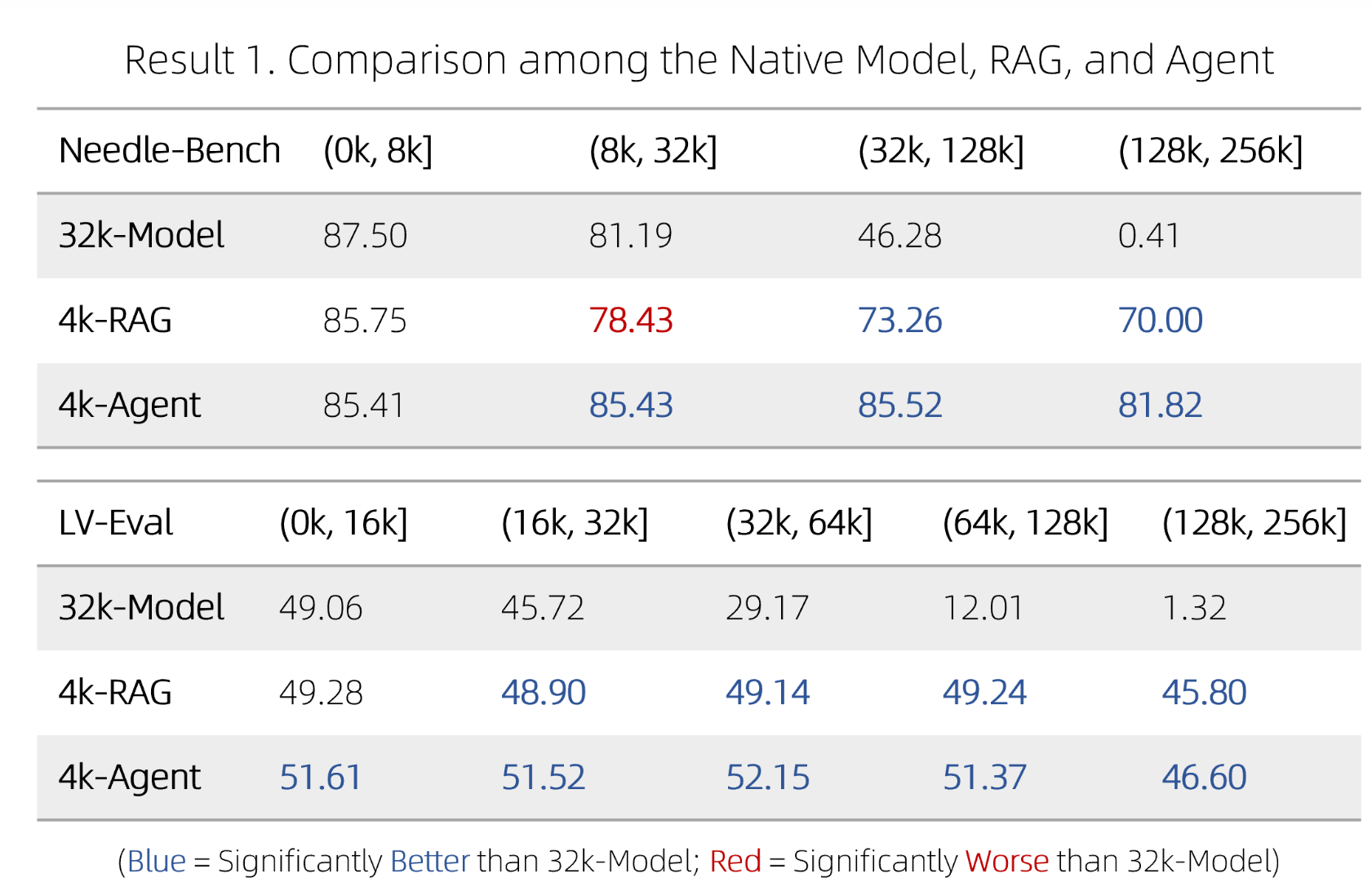
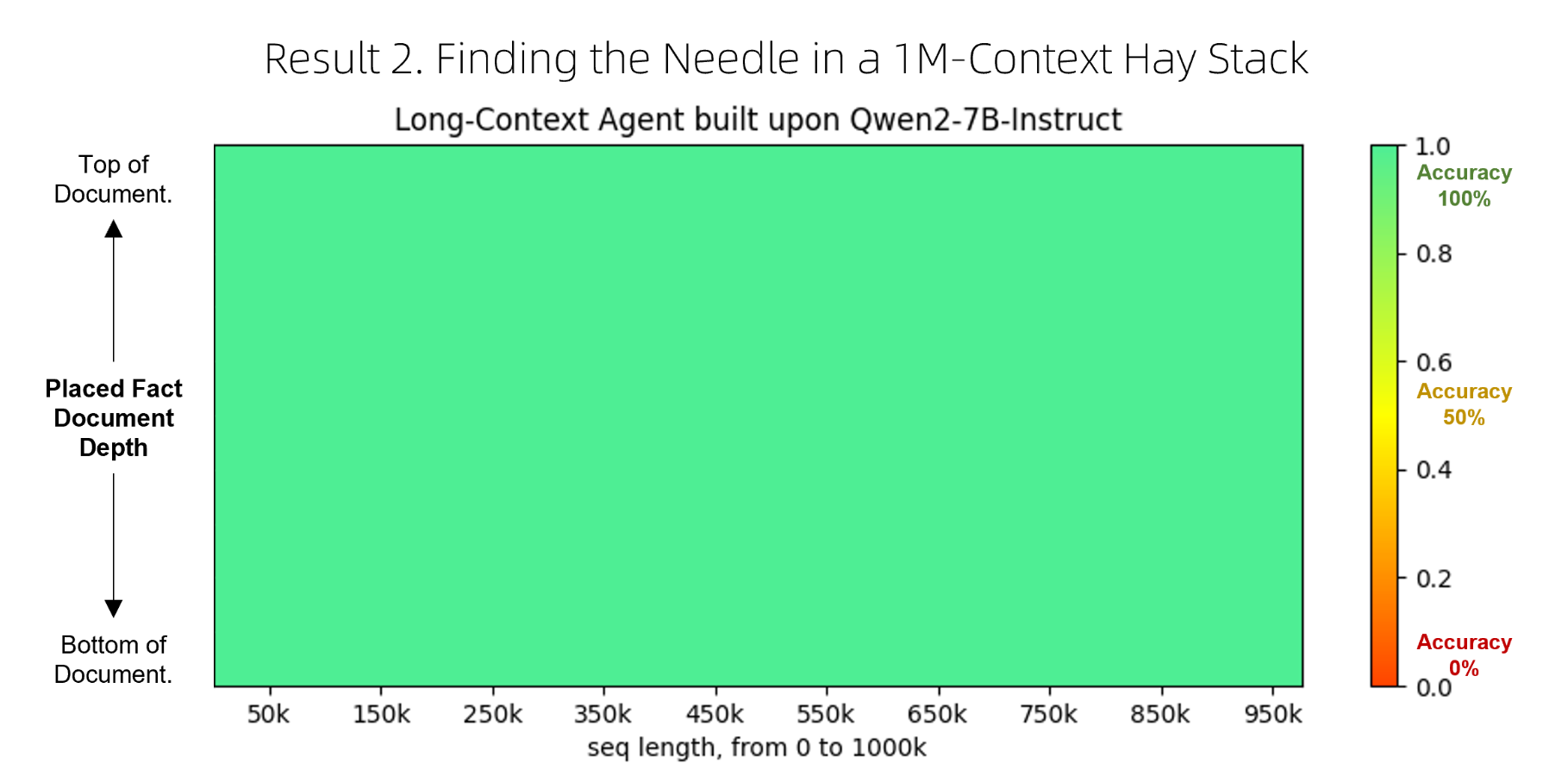
使用 Qwen2-7B-Instruct 进行 1M 的上下文大海捞针测试:
llama3 系列
官方 llama 3 博客,github,llama 2 系列回顾,huggingface llama 3 模型权重
模型大小:有 8B 和 70B 2 个大小。
预训练:在 15T+ 预料上,用 8k context window 训练。预料中包含了 30 个不同语言的高质量数据,并对 NSFW 数据进行了筛选。同时 Llama 也对各类训练数据的占比进行了研究。
以下部分为 GPT 参考翻译官方 llama 3 博客:为了有效利用我们在 Llama 3 模型中的预训练数据,我们投入了大量精力来扩大预训练规模。具体来说,我们开发了一系列详细的缩放法则用于下游基准评估。这些缩放法则使我们能够选择最佳的数据组合,并做出明智的决策,以便最佳利用我们的训练计算资源。重要的是,缩放法则使我们能够在实际训练模型之前预测我们最大模型在关键任务(例如,在 HumanEval 基准上评估的代码生成)上的表现。这有助于确保我们最终模型在各种用例和功能上的出色表现。
在开发 Llama 3 期间,我们对缩放行为进行了几项新的观察。例如,虽然 Chinchilla 最优的 8B 参数模型训练计算量对应约 200B tokens,但我们发现,即使模型在两个数量级更多的数据上训练,模型性能仍然在继续提高。 我们的 8B 和 70B 参数模型在训练到 15T tokens 时仍然呈现对数线性提升。更大的模型可以用更少的训练计算量达到这些较小模型的性能,但较小的模型通常更受欢迎,因为它们在推理过程中更高效。
为了训练我们最大的 Llama 3 模型,我们结合了三种类型的并行化:数据并行化、模型并行化和流水线并行化。我们最有效的实现方案在同时使用 16K GPUs 训练时 , 每个 GPU 的计算利用率超过 400 TFLOPS。我们在两个定制的 24K GPU 集群上进行了训练。 为了最大化 GPU 的正常运行时间,我们开发了一个先进的新训练堆栈,自动化错误检测、处理和维护。我们还大大提高了硬件可靠性和无声数据损坏的检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销。这些改进使整体有效训练时间超过 95%。综合来看,这些改进使 Llama 3 的训练效率相比 Llama 2 提高了约三倍。
post training:
- Llama 3 同时用了 SFT, rejection sampling, PPO 和 DPO。并且他们发现,PPO 和 DPO 对逻辑推理以及代码的任务效果提升很大。
- Llama 3 在模型质量方面的一些最大改进来自于精心策划这些数据,并对人类标注员提供的注释进行了多轮质量保证。
模型架构:与 llama2 相似,8B 模型也用上了 GQA,但上下文长度等架构参数不太一样,可以参考这个 config。
模型效果:Llama 3 7B 比 7B 热门模型 Mistral 要好上不少。

预训练版本的 Llama 3 70B 比 Mixtral 8*22B 好:

Llama 3.1
官方博客,相关论文,huggingface 模型仓库。推荐可以看李沐的论文精读。
模型大小:8B,70B,405B
模型架构:与 llama3 相似,上下文窗口 128k,部分参数不同。
预训练:
用 8K 上下文,在 15.6T 上数据。
用了多种方法,来对大量的数据进行高质量的筛选。用了自定义的解析器来解析 HTML ,从而更好的处理代码,数学等。论文中提到 markdown 对模型的表现有害,因此他们移除了所有的 markdown marker。
数据去重方法: Heuristic filtering.
Model-based quality filtering.
Code and reasoning data.
Multilingual data.
数据混合:50%通用知识,25% 数学和推理,17% 代码,8% 多语言模型。
将小部分得质量很好的数据拿出来,在 annealing 阶段单独训练的话,可以提升模型在对应领域的能力。
Post Training:用了 SFT + rejection sampling 和 DPO。
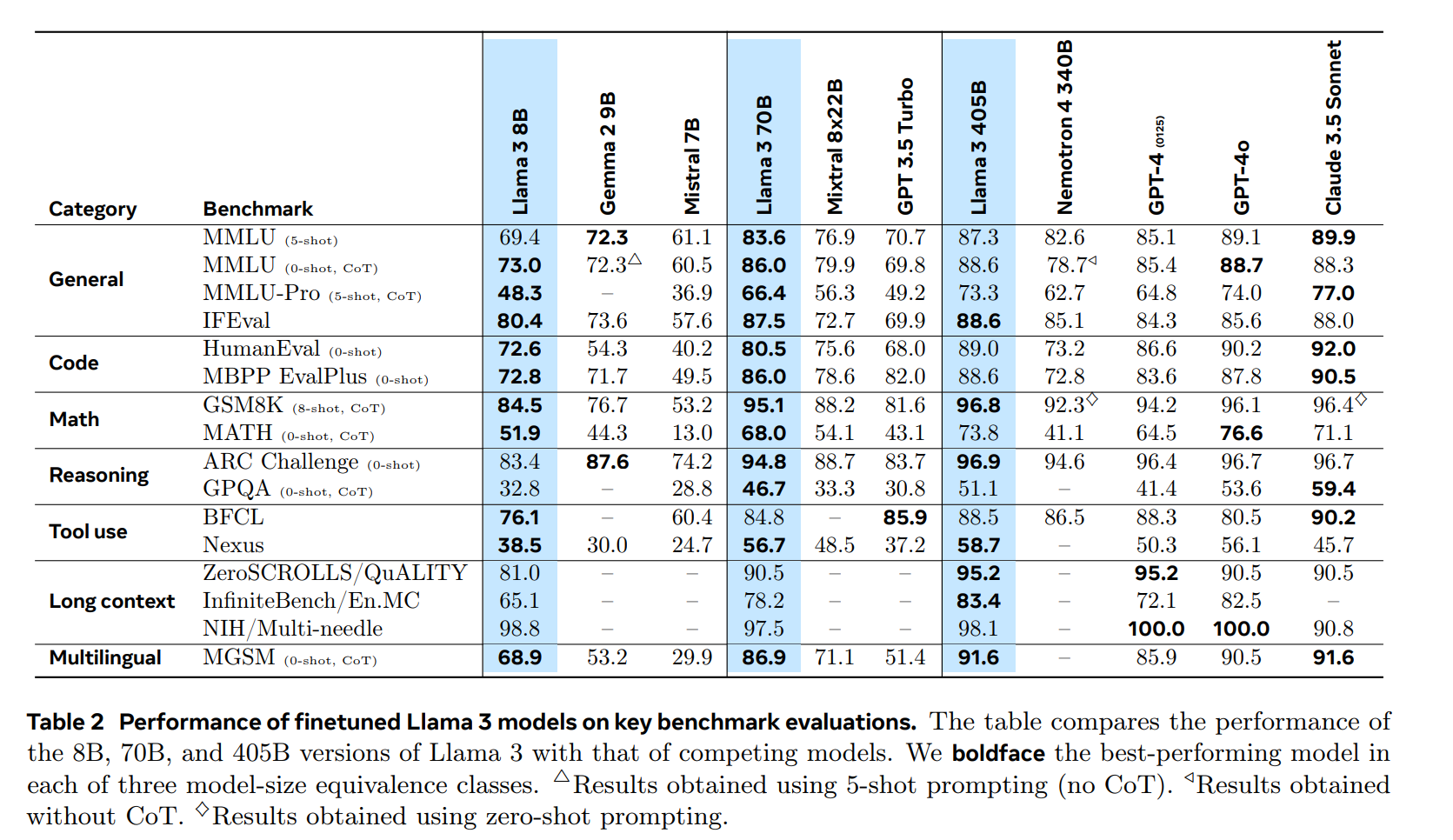
模型效果:
可以重点查看模型 scale up 后的分数提升程度。