NLP 预训练小综述
预训练模型的前世今生
看完了 Pre-Trained Models: Past, Present and Future。对目前主流 NLP 预训练模型、预训练方式做个小结与梳理。
自从 ELMO,GPT,BERT 问世,基于大规模预料的预训练模型便开始流行起来。学者们的注意力渐渐从模型架构转移到了预训练上。预训练+微调的方式也创造了不少下游任务 SOTA。
深度神经网络
深度神经网络早期主要面临数据少,模型规模受硬件限制等问题。回顾大部分 3 到 4 年前发布的 NLP 文章,大多研究关注与如何让模型更有效从数据集中获取知识。如发掘更优质的人工标注 数据集 、更好的 模型架构 或更完善的 特征工程 。
过去两年,NLP 的目光转移到了 预训练+微调 。类似 CV 领域的迁移学习 (Transfer Learning),预训练可提升在小规模训练集上的训练效果。早期基于词向量的预训练方案(如 Word2Vec、Glove )有所效果,但无法解决一词多意等问题;在 BERT/GPT 等模型出现后,各式各样的预训练方案被提出,模型学习的质量得以提高。
预训练模型的发展
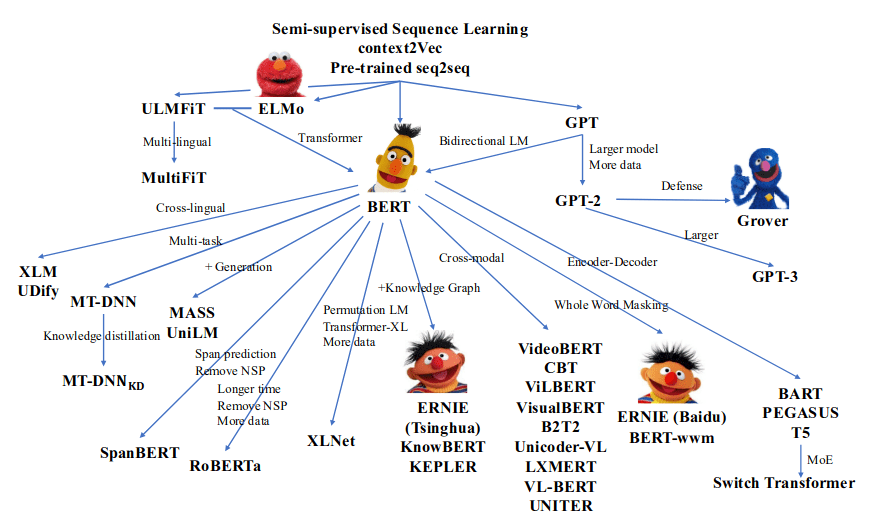
(图:预训练模型概述。来源:Pre-Trained Models: Past, Present and Future 截图)
文字语言由无数的字符组成,从字符、单词、句子、段落到一篇文章、一个书、一个论坛、一个网站等。每个层面都藏有深奥的语义知识。对预训练模型做一个小总结的话,可以感受到预训练任务正在从学习最基础的字符之间的关系拓展到句子、段落、话题等。
从 BERT 的 MLM 开始
拓展 - 分词:为了解决词汇问题,大规模预训练模型通常采用 subword(深入理解 NLP Subword 算法:BPE、WordPiece、ULM)创建词表。常见的 subword 方式有 BPE(OpenAI GPT-2 与 Facebook RoBERTa), WordPiece(BERT),Unigram Language Model 等。
采用 Transformer Encoder 架构的 BERT 在预训练时,随机对部分分词(subword)进行了掩码(如 dog, ##ing 变 [MASK] )。对于中文,上述对分词随机掩码的方式存在分割单词、破坏语义的情况,因此 BERT-WWM (Pre-Training with Whole Word Masking for Chinese BERT )提出了 whole word mask 。针对整个 中文单词 进行掩码。
BERT 采用的是 Static Mask 的方式,即在训练前准备好 mask 了的预料。因此每轮 epoch 中,相同预料的 [MASK] 位置是一样的。 RoBERTa 提出 Dynamic Mask ,即在数据输入模型之前进行随机的 [MASK]。实验证明 Dynamic 在部分任务上略优于 BERT 初始方案。
BERT MLM 缺点之一是他是自编码结构,虽然有了位置编码,但是学习语言结构信息上还是没有自回归结构强。 XLNET 提出了 PLM ,增强了对单词结构顺序的学习。PLM 任务首先将单个输入语句的单词打乱重排,而后遮掩掉句子末尾的 N 个词(理论上是这样,但实际训练时只需要对 Attention Mask 进行处理就行,不需要真的排序)。此时使用自回归的方式来预测遮掩的词,就能够学习到不同位置的信息了。
更好的学习字符知识
MLM 并非完美,过去两年,多种基于字符级别的预训练任务被提出。
对于提升对语言架构的更高效学习:
以加强段落中不同位置单词之间的联系, SpanBERT 添加了 SBO( Span Boundary Objective )。给定语句:今天一起去踢足球吧,进行掩码后变为 今天一起 XXXX 吧 。假设语句中的 足 词被遮掩且对应位置为 。MLM 通过 对应的信息推测 足 ,目标函数为:;而 SBO 则是通过 Span 掩码两端的信息预测单词,目标函数为: 其中 为 span 两端的 hidden state, 为 足 的相对位置编码。
同时,为提高模型对与输入的鲁棒性, BART 提出 Token Deletion , 删除某些字符,让模型预测删除字符的位置。
BERT MLM 存在的一个问题(直观上的,并无证明)是,由于语料中单词的分布是不均匀的,使得训练出来的表征分布在空间分布上不均匀。 ELECTR 提出了 RTD ( Replace Token Detection ),类似对比学习,一定程度上改善上述问题。训练时 RTD 需要配合 MLM,类似 GAN,构造生成器(BERT)与判别器(ELECTRA),生成器输入带有 [MASKED] 的语句,输出生成语句,判别器判断语句中哪个词生成错了;训练采用 Two-stage traning:先训练生成器,冻结后在训练判别器,依此循环。
对于学习更多单词本身的信息:
ERINE (清华)提出了针对 命名体 Entity Phrase 进行 Mask,在完成原先 MLM 任务的基础上,额外完成对命名体类别的分类 ( Entity Typing ),在这个任务中,预训练模型也融入了知识图谱相关的知识。
单词本身的特性也值得提取, ERINE-2.0 提出了 Capitalization Prediction ,大写的词比如 Apple 相比于其他词通常在句子当中有特定的含义,所以在 Erine 2.0 加入一个任务来判断一个词是否大写。此外,还提出了 Token-Document Relation 任务,预测段落中的某一单词,是否会在同一文章的其他段落出现 ,该任务可用于主题词预测,关键词抓取等。
字符之上
从语言结构角度看,字符更上一层便是短语、句子。过去两年也有许多预训练任务为它们而生。
短语级别来看:
SpanBERT 提出了对连续的片段 span 进行掩码。在实验中,基于 Span/N-gram (SpanBERT)掩码达到很好的效果(比 BERT 原始方案和其他几种掩码策略好)。做法是:从一个分布中随机选取 Span 的长度,而后算计选取 span 开始的位置,此位置必须是一个单词的开始,span 掩码包含的总是完整的单词。预训练的目标是预测被掩码的全部内容。
同样是对连续片段掩码,不同与 SpanBERT 的双向模型结构, MASS 采用了 encoder-decoder 架构,并使用自回归的方式对掩码部分进行了预测。与 XLNet 对 BERT 的修改有异曲同工之处。
MASS 是一次对一片掩码进行预测。 ERNIE-GEN 提出了 span-by-span generation ,遮掩随机的几个片段,在 decoder 部分统一对它们进行预测预测(ERNIE-GEN 模型为 ENCODER 结构,预测时参考了 UNILM 对 Attention Mask 进行修改)。
句子级别来看:
BERT 提出了二分类任务 NSP ,根据 CLS 位置的输出,预测 AB 两个输入语句是否是上下文关系。50%时候,B 是 A 的下一句,标注为 isNEXT。其他时间,B 是文本中的随机一个句子,标注为 NotNEXT。但 RoBERTa、SpanBERT、ALBERT 等提出该任务会拉底模型效果,并在预训练中去除了 NSP。
为了提升句子级别的预训练, ALBERT 提出了 SOP( sentence order prediction ),同样为二分类任务,正样本与 NSP 相同,但负样本则将句子的位置调换,提高了训练难度。
相比于判断上下文关系,对几个句子进行重排难度更大。 ERNIE2.0 提出 Sentence Reordering 在训练当中,将段落随机分成 1 到 k 段并打乱它们的顺序,预训练模型的目标是判断这些句子的顺序(为每个句子预测一个顺序值,k 分类任务)。
ERNIE-2.0 中还有其他针对句子提出的预训练任务,如判断句子距离的三分类任务 Sentence Distance ,针对两个句子 AB,输出:0 表示 AB 为文章中相邻句子;1 表示 AB 为同文章中不相邻句子;2 表示 AB 属于不同文章。还有 IR Relevance ,判断一个句子和一个标题的相关性(强关系/弱关系/无关系)。以及 Discourse Relation ,判断句对之间的修辞关系(semantic or rhetorical relation)。最后两个任务都为监督任务,需要在标注数据集上训练。
ERINE 1.0 采用 DLM( Dialogue Language Model )建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,通过该方法建模进一步提升模型语义表示能力。
预训练模型目前情况
模型解释性主要探索的方向有:
Representation Probing:冻结 PTM 权重,链接额外的线性层。在不同的任务上进行测试与观察 Representation Analysis:对隐状态进行统计学的分析,如相似度,距离等等。 Attention analysis:对注意力矩阵进行分析。 Generation Analysis:直接评测生成不同句子和单词的概率、分布
目前来说,模型的鲁棒性似乎还是不好,主要采用对抗训练来提高模型鲁棒性。
高效训练模型方面,通常采用精度调整(如双精度训练);分布式训练;探索更高效的模型架构来取代 Transformers;参数共享;模型剪枝、蒸馏等。
未来的预训练模型
如何让模型更智慧?对于各种问题,主要的解决方向为优化模型架构,采用更多更好的数据,采用多样化的训练方案。
而目前,训练方式似乎成为了主流研究方向(个人感受)?包括更好的融入多模态、使用多重下游任务来提升预训练模型效果、融入知识图谱知识等。不确定 NLP 预训练模型是否会有大一统。
模型在应用层面的优化防线也有很多:
- 提高基于少量资源微调的效果;
- 为领域预训练提供更好的数据集;
- 更高效的模型压缩;更好的硬件支持
- 提高鲁棒性、更正模型逻辑能力。(GPT-3 面对 "How many eyes does my foot have?" 问题,会回复 “Your foot has two eyes” )
似乎 Pretrain + Prompt 的方式可以更好的为模型融入更多下游任务的知识,提供模型质量,期待 NLP 技术在未来的发展。 后 Prompt 时代|NLP 大一统建模范式:预训练+大规模多任务学习
预训练模型关键点总结
ELMO
- feature base;采用双向的 Bi-LSTM
OpenAI - GPT
- parameter base;自回归模型,使用 transformer 模块(一个 Casual Masked 的 MHA 加上 FFN 层);使用预训练 + 微调结构,微调通常使用全连接层处理最后一个位置的隐状态。
BERT
采用 transformer encoder 的双向结构
预训练任务:Masked LM:遮掩一部分的 token,并在输出层预测他们;NSP:二分类任务,判断两个句子是否为上下文关系(部分前后)。
升级版:
SpanBERT:
- 预训练任务:去除 NSP;采用 Span Mask 处理 MLM 任务;
- 目标函数添加 Span Boundary Objective
OpenAI - GPT2
- 自回归模型,结构与 GPT 相似,但使用 pre norm;Tokenizer 使用了特殊的 BPE;采用 query 来引导模型进行不同任务的训练(multi task learning);zero shot 有效的一种解释是:训练的对话集中,包含有任务所需要的知识,如论文中展示的英法翻译。
ALBERT
- 架构方面,基于 BERT 的架构对 embedding 层进行了因式分解,共享层与层之间的模型参数(cross-layer parameter sharing)实现表明共享全部(FNN、Attention)权重下,模型表现也不会差太多;
- 预训练方便:去除 NSP,采用 SOP(sentence order prediction)正样本与 NSP 相同,但负样本则将句子的位置调换。
UNILM
- BERT 与 GPT 主要是差了一个 Attention Mask。因此 UNILM 通过修改 Attention Mask 进行 NLU + NLG 的多任务学习,实现 BERT 处理 NLG 任务。
RoBERTa
- 预训练方便:去除了 NSP;使用了 Dynamic Mask 进行 MLM 任务;训练时间更长,batch size 更大。
- 结构方便:Tokenizer 参考 GPT2 使用了特殊的 BPE,句子长度加长
ERNIE(清华)
- 预训练方面:除了 MLM 外,添加新 entity typing 任务,对实体进行掩码以及类别预测,构造输入时, 使用 TransE 模型的实体预训练 embedding 作为额外信息 ,与原输入中标记的实体进行拼接;使用
[ENT],[HD]等 token 进行任务提示,如[ENT]用于标出实体位置,便于 entity typing 任务;采用 NSP。
ERNIE-2.0
- 预训练方面:尝试使用额外的预训练任务,学习处基础语法之外的信息,包括: Knowledge masking (ERNIE-1), Capitalization Prediction, Token-Document Relation Prediction, Sentence Reordering, Sentence Distance, Discourse Relation, IR Relevance;采用 Continual multi-task Learning 训练时逐步增加同时训练的任务数量,不同于 multi-task 和 continual learning。
MASS
- 4 层 transformer 结构。对句子中连续部分进行 mask,而后通过 decoder 进行自回归预测。decoder 只预测被 masked 的部分,未 masked 的部分使用
[M]作为输入。
XLNET
- 预训练方面:提出 PLM,对 token 进行排序后在 mask,使用自回归的方式完成预训练;采用了双流注意力机制。
MPNet
- 解决 XLNET 微调时位置信息与预训练不匹配问题,即预训练时候模型知道语句长度,而微调时候不知道。
ELECTRA
- 预训练方面:采用 MLM + RTD(Replace Token Detection),类似 GAN,构造生成器(BERT)与判别器(ELECTRA),生成器输入带有
[MASKED]的语句,输出生成语句,判别器判断语句中哪个词生成错了;训练采用 Two-stage traning:先训练生成器,冻结后在训练判别器,依次循环;采用 Adversarial Contrastive Estimation。
T5
- 论文很长(实验性研究):encoder-decoder 的模型似乎效果更好;所有任务使用生成任务完成(Text-to-Text); 预训练 MLM 时采用 Span Maksed。如原句
今天天气真的非常好,是吧。encoder 输入今天[x]真的[y]好,是吧。decoder 输出[x]天气[y]非常
BART
- encoder-decoder 结构; 预训练方面:采用字词级别预训练:Token masking, Token deletion; Text infilling(spanBERT) ;加强句子间预训练:Sentence permutation(多分类), document rotation
GPT-3
- 论文也很长,1700 亿参数,结构类似 GPT-2;zero-shot,无需微调,支持在输入中加入样例来实现 one-hot/few-shot;
NEZHA
- Functional Relative Positional Encoding 相对位置编码,解决 bert 末端位置编码更新少的问题;采用 Whole Word Masking,使用 jieba 分词;采用 Mixed Precision Training,权重使用 FP32 储存与梯度更新,前向后向传导使用 FP16;采用 LAMB Optimizer 自适应调整学习率
ERNIE-GEN
处理由 teacher force 带来的 训练与预测时输入不一致问题。
infilling generation :每个需要预测的 token 位置上,额外添加一个
[attn]token 来汇聚上文信息,模型输出的位置为[attn]对应的位置,降低输出对上一个词的依赖。(类似于 decoder 的输入改成[attn]序列)Noise-Aware generation :随机进行单词替换,提高模型容错率
span-by-span generation :遮掩随机的几个片段,在 decoder 部分统一预测(更改 attention mask)。不同于 UNILM(mask 并预测末端)和 MASS(mask 随机片段,在 decoder 预测)。
VILBERT
- 双流多模态模型;FASTER-RCNN 做图像编码;提出 co-attention :图像与文字各自经过编码后,使用不同的 transformer decoder 模块处理,图像/文字的输出作为文字/图像的 KV;预训练时预测部分遮掩的图片与文字,并判断图文是否匹配。
VisualBERT
- 单流多模态模型;图像 embedding 与文字 embedding 使用同一个 transformer 处理;同 VILBERT 采用图文 MLM 及二分类的图文匹配判断。
UNIMO
- 多模态对比学习 :文字样本通过重写实现:句子级别重写,使用 back-translation(翻译成别的语言再翻译回来) 生成正样本,使用 tf-idf 相似句子作为负样本。单词级别重写,随机替换其中部分单词;图片正样本使用其本身,负样本使用图像相似度高的;对比学习的样本对为图文对(图片,文字),并未考虑单独的图片或文字对形式。
- 预训练任务 :Span MASK(SpanBERT)双向预测掩码;span-by-span generation(同 ERNIE-GEN)单向预测掩码;图像遮掩后重建,损失为原图像表征与重建表征的欧式距离;
XLM
- 多语言模型;提出 TLM:使用多语言平行语料组成
[A 语言][SEP][B 语言]。的形式,同时对 A/B 中的单词做随机掩码。模型需要预测出掩码内容。A 、B 的位置掩码相同
XLM-R
- XLM-RoBERTa;预训练任务为多语言的 MLM
mBART
- 多语言版,相对于 BART,encoder/decoder 添加了
final_layernorm层 - 输入(encoder 结束与 decoder 开头)添加 特殊符号 ,标记目前使用语言;预训练仍然采用 A 语言输入 A 语言输出;微调时通过 特殊符号 进行多语言任务微调;
Unicoder
- 提出了三个需要平行语言输入的预训练任务: CLWR (Cross-lingual Word Recovery)使用 B 语言的句子尝试构造 A 语言,使用了传统的注意力机制,而非 MHA; CLPC (Cross-lingual Paraphrase Classification):二分类,判断中英句子对是否匹配; CLMLM (Cross-lingual Masked Language Model):采用中英夹杂的句子进行 MLM(从实验上开起来没效果)
论文
[1] Deep Biaffine Attention for Neural Dependency Parsing [2] On Layer Normalization in the Transformer Architecture [3] CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding [4] Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks [5] Unsupervised Cross-lingual Representation Learning at Scale [6] UNITER: UNiversal Image-TExt Representation Learning [7] VisualBERT: A Simple and Performant Baseline for Vision and Language [8] LXMERT: Learning Cross-Modality Encoder Representations from Transformers [9] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks [10] Language Models are Few-Shot Learners [11] NEZHA: Neural Contextualized Representation for Chinese Language Understanding [12] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS [13] MASS: Masked Sequence to Sequence Pre-training for Language Generation [14] MPNet: Masked and Permuted Pre-training for Language Understanding [15] ERNIE 2.0: A Continual Pre-training Framework for Language Understanding [16] RoBERTa: A Robustly Optimized BERT Pretraining Approach [17] SpanBERT: Improving Pre-training by Representing and Predicting Spans [18] ERNIE: Enhanced Language Representation with Informative Entities [19] Pre-Trained Models: Past, Present and Future [20] ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation [21] ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation [22] Deep contextualized word representations [23] Cross-lingual Language Model Pretraining [24] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations [25] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension [26] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [27] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [28] XLNet: Generalized Autoregressive Pretraining for Language Understanding [29] Improving Language Understanding by Generative Pre-Training [30] Language Models are Unsupervised Multitask Learners [31] Multilingual Denoising Pre-training for Neural Machine Translation [32] Unified Language Model Pre-training for Natural Language Understanding and Generation [33] UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning