LLM 高效训练方案整理
LLM 高效训练方案整理
本文基于 Huggingface PEFT,回顾整理常见的 LLM 高效训练方式,包括 prefix-tuning, p-tuning, lora, prompt tuning。对于 PEFT 中的模型,如 PeftModelForSequenceClassification。可以分为以下四种方式进行讨论:
Prefix-Tuning (P-Tuning v2)
论文:Prefix-tuning- Optimizing continuous prompts for generation
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
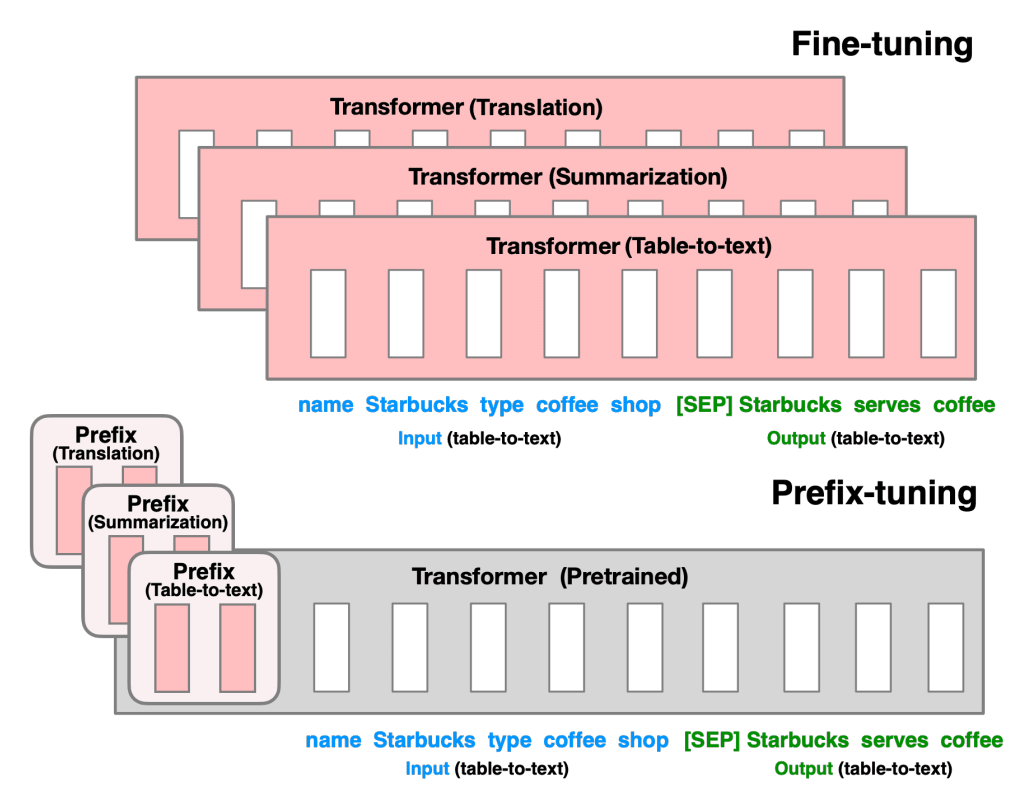
Prefix-tuning 的直觉
对于原先的 GPT2 模型,我们在不同任务上 finetune 的时候经常需要对所有的参数进行微调,然后保存不同模型的权重。因此,如上图,论文作者提出在模型前加入可学习的 prefix 参数来引导整个模型的注意力机制,在区分不同下游任务的同时提高模型的学习能力,尽可能多得保留原预训练模型的知识。

参考以上例图,原输入序列 添加 prefix id 后变成了 。不同于 LM 模型, 部分的隐状态使用单独的 prompt encoder 进行计算,因此对于添加 prefix 之后的模型,所有 hidden state 计算方式为:
其中 为对应 prefix 的 index。
作者发现若直接对 prefix 参数进行更新会出现学习不稳定,模型表现变差等问题。于是添加了一个临时的 MLP 层与更小的临时参数矩阵来计算 prefix 参数,即:
当训练完成后,只保留 。同时在训练过程中 其他模型参数将会被冻结 。从作者的实验结果看出,prefix-tuning 在数据量小的时候,能够用更少的参数实现更好的效果。
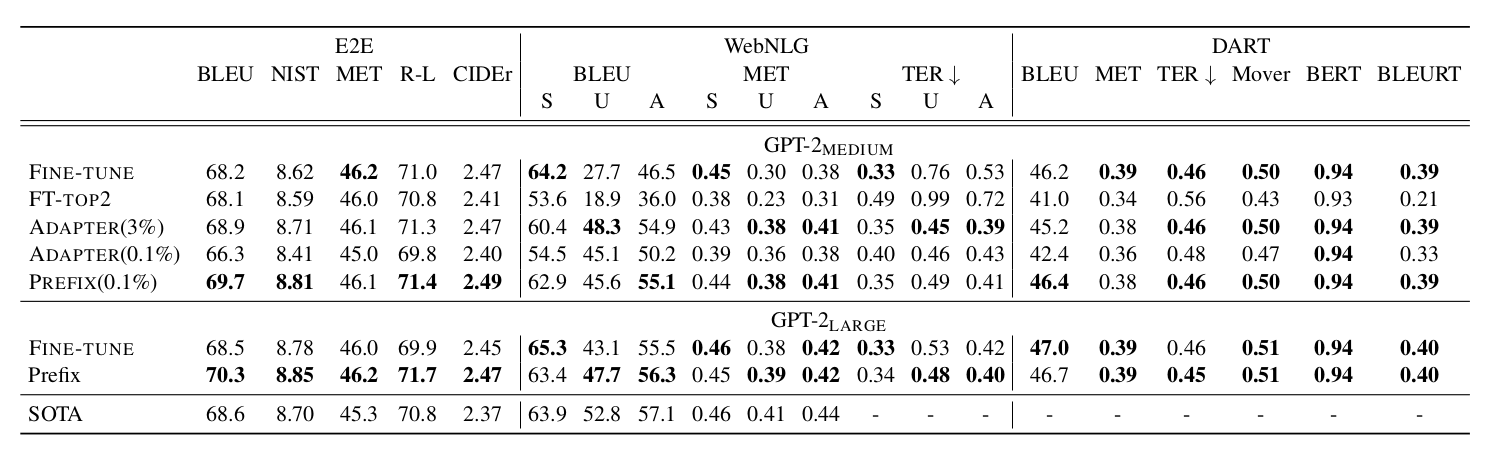
参考 PEFT 实现
PEFT 的 prefix tuning 在每层 transformer layer 处添加上 prompt embedding。在 PEFT 中,采用了 Transformer 中的 cache 机制巧妙地实现了这种方案。大致的流程可以通过以下伪代码实现:
prompt_encoder = PrefixEncoder # 在 peft.tuners.prefix_tuning.py 查看
prompt_tokens = torch.arange(config.num_virtual_tokens).long().unsqueeze(0).expand(batch_size, -1)
# 生成连续的 prompt, shape: [num_virtual_tokens, num_layers * 2 * token_dim]
past_key_values = prompt_encoder(prompt_tokens)
# 将 prompt 映射为 Transformer cache 时需要的格式
# 在 Huggingface 中,巧妙地采用了 past_key_values 来传导模型推理时的 cache 信息。
past_key_values = past_key_values.view(
batch_size,
peft_config.num_virtual_tokens, # `prompt_token` 的长度
peft_config.num_layers * 2,
peft_config.num_attention_heads,
peft_config.token_dim // peft_config.num_attention_heads,
)
output = self.base_model(input_ids=input_ids, past_key_values=past_key_values, **kwargs)
猜测 past_key_values,主要采用的方式是与新的 input_embedding 计算出来的 kv 进行拼接,而后进行 multi-head Attention 等计算。所以 prefix-tuning,实际上是提供了可以训练的 kv 参数??
PrefixEncoder
参考 prefix 原文,prompt 对应的 hidden state 计算方式就是索引,因此用 Embedding 即可,参考 prefix-tuning 作者的实验结果,也可以再 Embedding 之后加上一层 MLP 来提升训练稳定性。
class PrefixEncoder(torch.nn.Module):
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.transform(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
# past_key_values.shape: [num_virtual_tokens, num_layers * 2 * token_dim]
return past_key_values
Prompt tuning
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
Prompt Tuning 在笔者的这篇 文章 中有稍微介绍过。论文使用了 encoder-decoder 结构的 T5 模型对参数化的 prompt 训练进行了研究。
主要方式为在输入的 embedding 前面,添加上 prompt embedding。使用可学习的 prompt 参数作为输入前缀,与长度为 的原输入 embedding 拼接得到 ,其中 为 prompt 的长度(超参), 为 embedding 的维度大小。训练时针对 进行优化,冻结预训练模型权重,单独对 prompt 参数进行训练与更新。
参考 Huggingface PEFT,模型的整个前向推导流程可以看作:
inputs_embeds = self.word_embeddings(input_ids)
# Prompt Tunign 使用的 prompt_encoder 是单纯的 embedding
prompt_encoder = torch.nn.Embedding(
config.num_virtual_tokens * config.num_transformer_submodules, config.token_dim
)
# 此处的 num_transformer_submodules 对于 encoder-decoder 架构为 2,对于 decoder 为 1
prompt_token = torch.arange(config.num_virtual_tokens * config.num_transformer_submodules).long().unsqueeze(0).expand(batch_size, -1)
if labels is not None:
prefix_labels = torch.full((batch_size, peft_config.num_virtual_tokens), -100).to(self.device)
kwargs["labels"] = torch.cat((prefix_labels, labels), dim=1)
prompts = prompt_encoder(prompt_tokens).to(inputs_embeds.dtype)
# 在 input embedding 前面添加 prompt embedding 即可。
inputs_embeds = torch.cat((prompts, inputs_embeds), dim=1)
output = self.base_model(inputs_embeds=inputs_embeds, **kwargs)
由 prompt tuning 中的实验数据可看出,仅对 prompt 参数进行学习,在模型规模足够大时媲美对模型全参数进行 finetune。由于更新的参数熟练减小,训练难度降低,同时也不需要针对不同的任务各保存一份完整的 T5 模型,只需储存 prompt 参数部分即可。
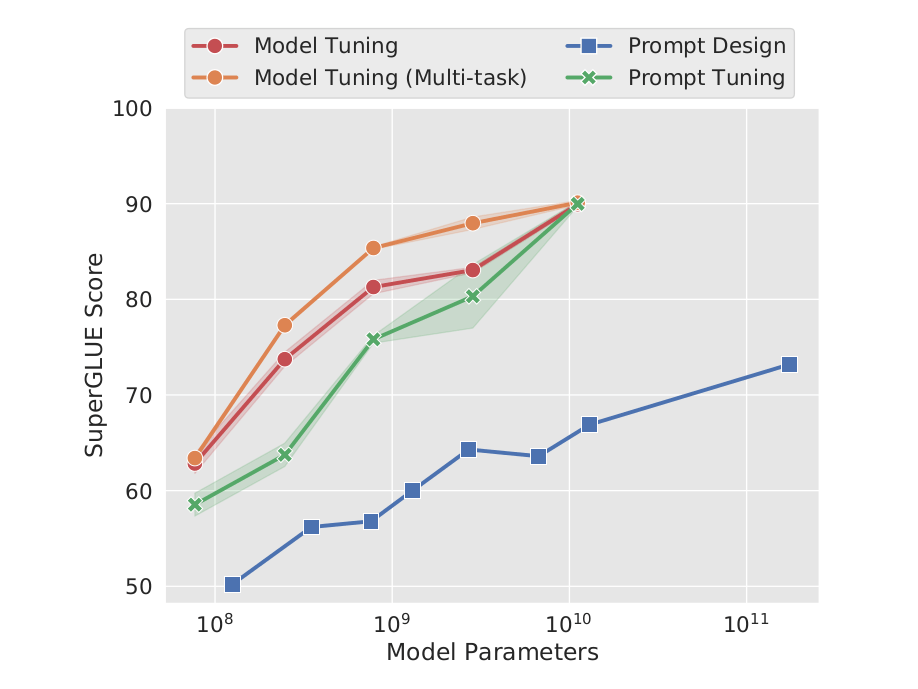
(图:T5 模型在不同训练方式下的结果)
P-Tuning
论文:P-tuning-GPT Understands, Too.
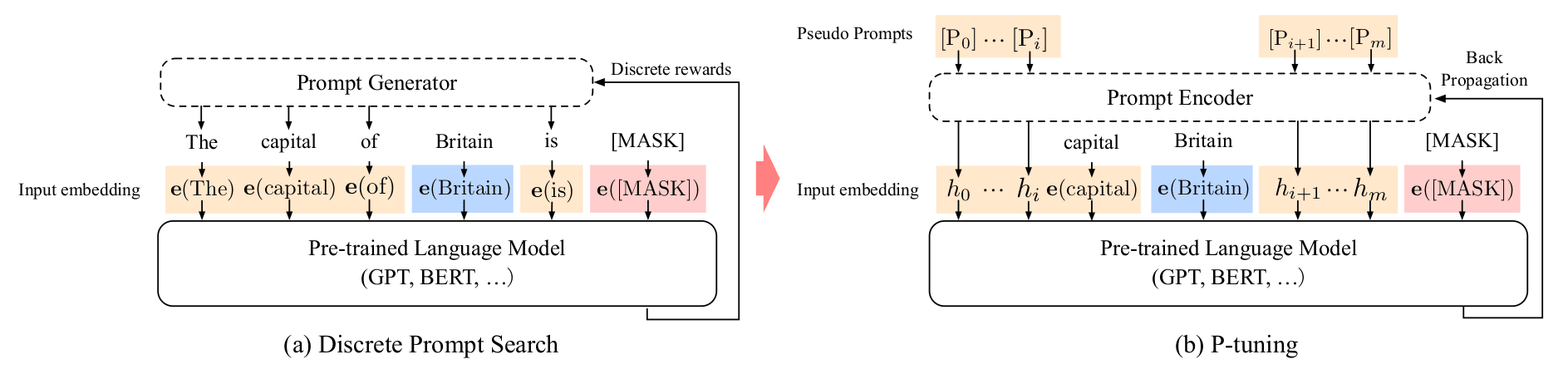
P-Tuning 与 Prompt Tuning 较为相似,参考 PEFT 的实现,两者的主要差别在于:
- Prompt Tuning 中的 prompt_encoder 简单地使用了 Embedding,而 P-Tuning 在 Embedding 基础上,另外添加了额外地 layer 进行处理。
- 除此外, P-Tuning 主要是针对 NLU 任务进行实验,因此 prompt 添加的位置并非全部置于前面。
def forward(self, indices):
input_embeds = self.embedding(indices)
if self.encoder_type == PromptEncoderReparameterizationType.LSTM:
output_embeds = self.mlp_head(self.lstm_head(input_embeds)[0])
elif self.encoder_type == PromptEncoderReparameterizationType.MLP:
output_embeds = self.mlp_head(input_embeds)
else:
raise ValueError("Prompt encoder type not recognized. Please use one of MLP (recommended) or LSTM.")
return output_embeds
为了使得 prompt 的编码之间存在相关性,并解决 embedding 分布离散 (Discreteness)的问题(PLM 中的 embedding 高度离散导致使用 SGD 会很容易陷入局部最优),作者使用 BiLSTM 计算 prompt 的 hidden state。
根据网友的咨询与解析 论文作者认为此处一种更自然的做法 对下游任务目标与其他任务(如 LM 或者 MLM)一起优化 ,类似 PET 的优化方案。
此外作者还发现加入一下小标志符号有助于 NLU,如“[PRE][prompt tokens][HYP]?[prompt tokens][MASK]”中的问号。
作者对比了以下四种训练方式:(MP 代表 Manual Prompt)
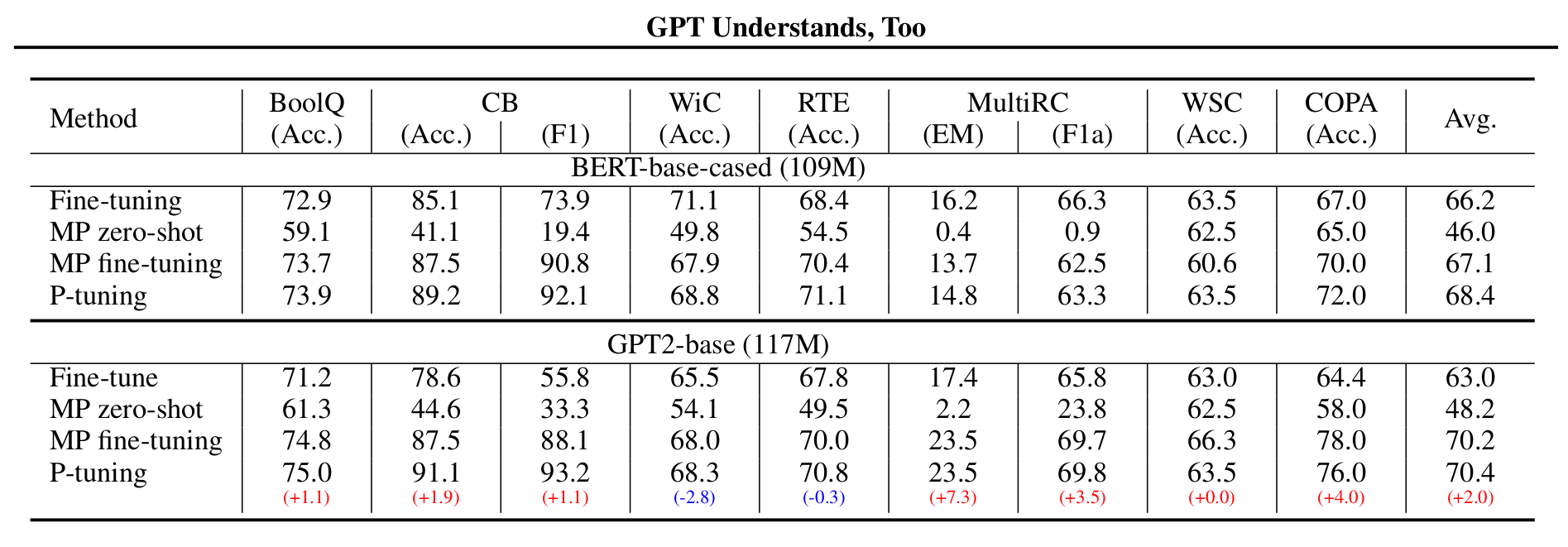
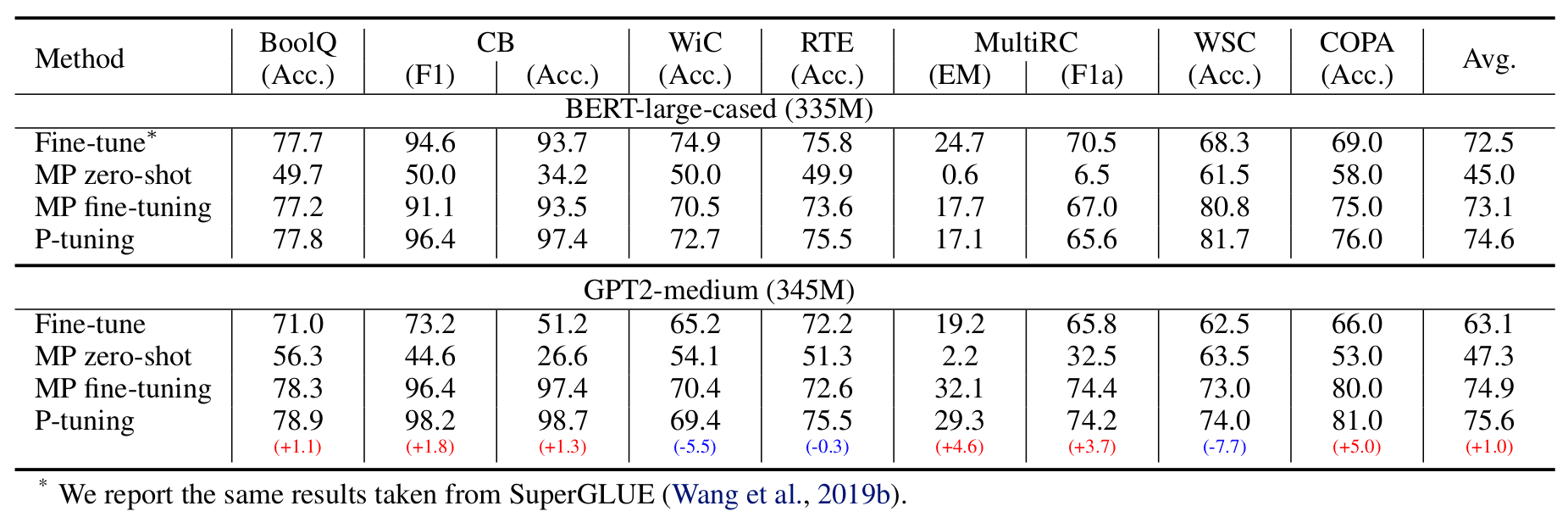
结果是 GPT2 在大部分数据集上优胜。
Lora
论文: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
不同于前三者,PEFT 对于 lora 的实现主要是在模型架构上,因此整个前项传导过程中不会设计任何的 prompt 因素:
output = self.base_model(
input_ids=input_ids,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
labels=labels,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
**kwargs,
)
模型架构的更改由 peft.peft_model.PeftModel.add_adapter() 完成,更改包括以下:
使用
LORA_MODEL来包装 huggingface 模型,class LoraModel(torch.nn.Module): def __init__(self, model, config, adapter_name): super().__init__() self.model = model # 该 model 为 huggingface.transformer 加载的模型 self.forward = self.model.forward self.peft_config = config # config 为 lora-config self.add_adapter(adapter_name, self.peft_config[adapter_name])遍历模型中的所有 module,将需要替换的模块更换为
peft.tuners.lora.Linear(),其结构如下图,除更换模块之外,还需要对fan_in_fan_out, int8 计算等进行适配操作,具体可以看 peft 中 lora 实现方式 。
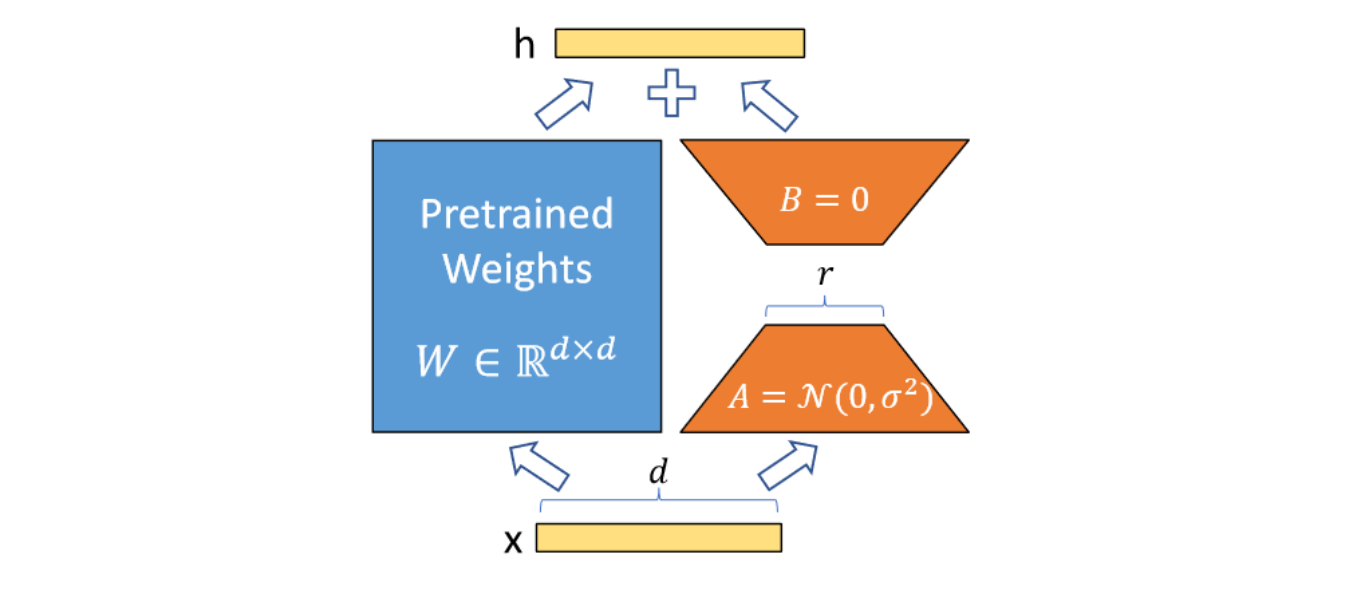
需要替换的模块可以通过 lora_config 中的 target_modules 参数进行传递,比如
["q", "v"]。因为 transformer 中的模型 module 通常会包含k, q, v等字样(比如第 1 层的 multi-headattention 可能命名为decoder.layer_0.attn.q_proj.weight),因此在锁定更换模块时,只需要进行文字匹配即可。参考下图 LORA 论文中作者的实验,冻结 q 和 v 可能是一个不错的选择:
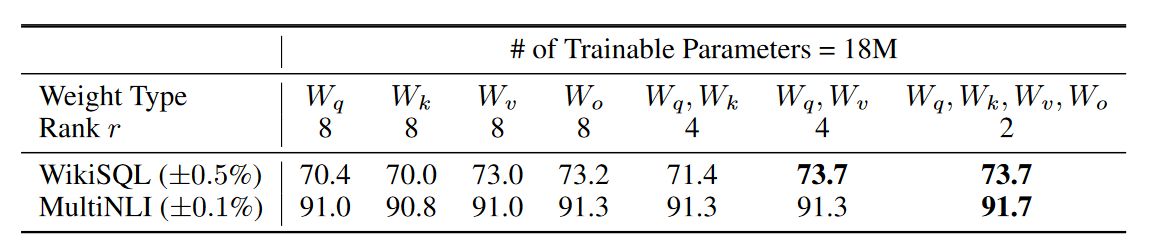
image-20230426000623300 除了 lora 对应的 layer,冻结其他所有参数。
通过 LORA 论文的实验结果,RANK=8 配合
target_modules= ["q","v"]可能是不错的选择。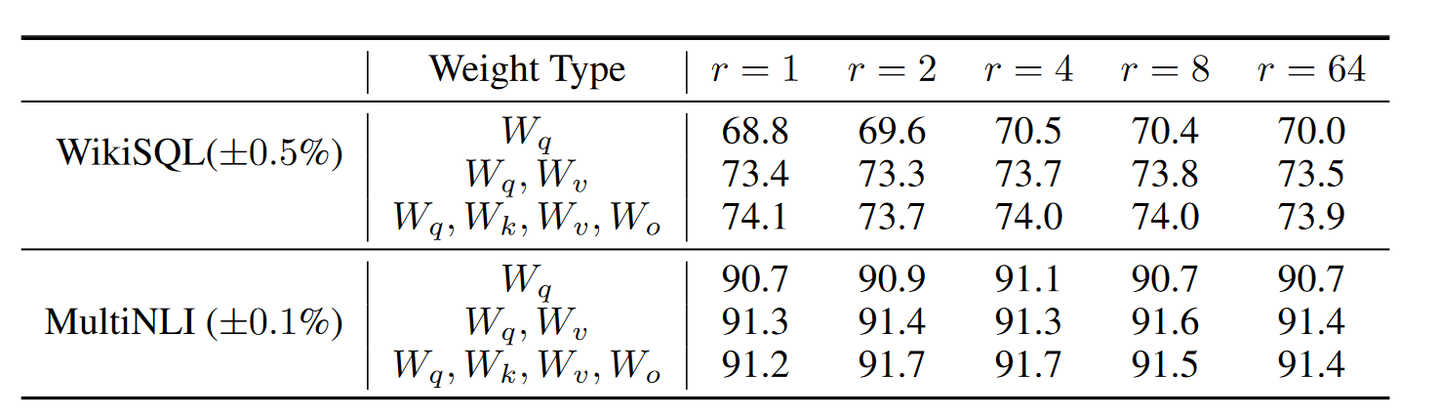
image-20230426000752577