对话模型 PLATO 系列论文笔记
对话模型 PLATO 系列论文笔记
最近又开始着迷对话系统了,于是花时间看了以下几个中文比较有意思的模型。本文对 PLATO,PLATO=2, PLATO-XL,PLATO-KAG 四篇论文进行笔记梳理与总结。
PLATO
论文:PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
概述
比较早的论文了,论文一上来提出,如果直接使用 Bert 在小规模的对话数据集上微调对话任务,其效果是很差的,基于这些问题,论文给出了几点原因猜测:
- 现实对话的分布与训练文本分布的差异是非常大的。
- one-to-many relationship:对于一个问题,在不同场景下,可能可以有多种不同的、正确的回答。而常规的训练过程是一个 one-to-one 对话模式的训练。
- Bert 模型本身对生成任务有局限性。
针对以上问题,论文提出了以下解决方案:
- 在 Reddit 和 Twitter 数据上进行进一步预训练。
- 对话过程中,对于同一个问题,在不同场景下可以有不同的回答。因此 PLATO 用一个隐变量 ,来建模 one-to-many 对话中的信息。隐变量的每个值,都会对应一种特定的对话意图。
- 训练时用了 UniLM 的方案,模型采用与 BERT 相似的 Transformer Encoder 模型,训练时用不同掩码来实现不同的优化目标。
预训练方法
预训练方法如下,采用 bert-case 作为初始权重。
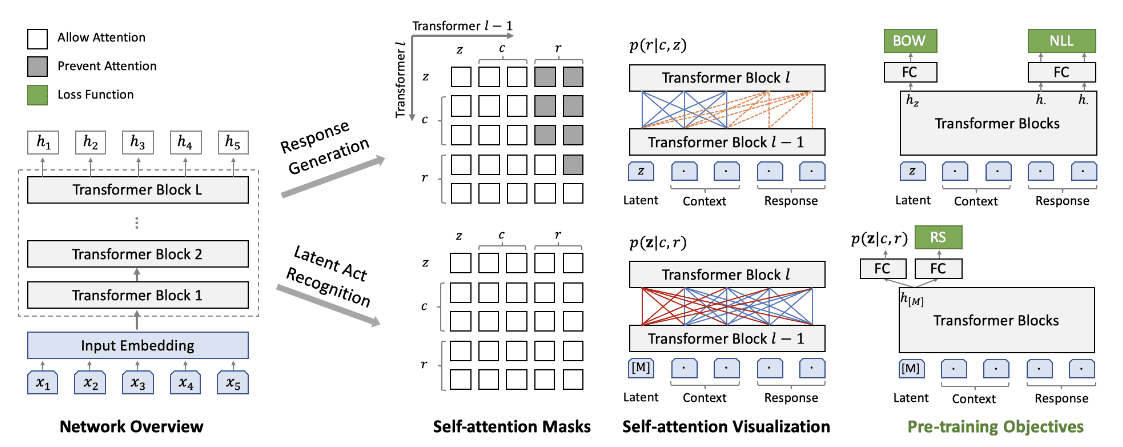
如上图,每一步训练都要进行两次前向传播。第一步负责进行 response generation 任务。
response generation
输入: 隐变量 latent,历史对话内容 Context,回复 Response 三者的拼接,如下图。
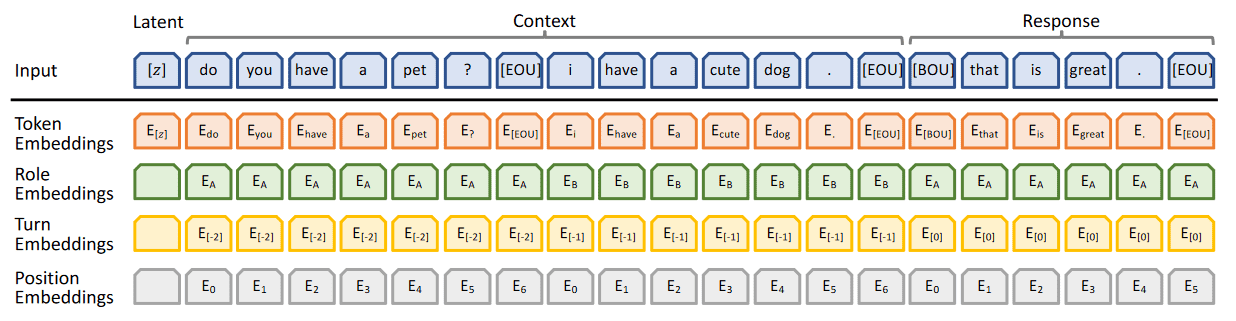
其中 Role Embeddings 用于标记说话的角色。(对于包含了外部知识背景的对话内容,如 Duconv 任务,额外知识对应位置的 Role Embedding 为 )。Turn Embedding 用于标记当前对话轮数。
隐变量的计算
大致的隐变量计算过程为:
X = nn.embedding([context,response]) # 通过 `context, response` 拼接后的 `embedding`
X = gumbel_softmax(dense(X)) # 形状 `[batch_size, num_latent]`
latent_embedding = X.matmul(embedding_params)
比较特别的是,在推理阶段,我们采用 argmax 来取代 gumbel_softmax。详细的隐变量计算 参考代码。
优化目标:
采用 UniLM 的训练方式,对 Response 位置对应的输出 hidden state 计算经典的 。
同时对 进行优化。 主要思想是,我们希望隐变量位置对应的 hidden state ,能够预测答案中包含了哪些 token。大致代码思路如下,比较特别的是 通过一次线性变换后,在计算交叉熵之前被拓展到了 [batch_size, len_pred, num_tokens] 维度,因为最后交叉熵的输入是通过 expand 得来的,因此计算出的 loss 与答案的顺序没有关系。
label = inputs["tgt_token"][:, 1:] # [batch size, len_pred]
self.bow_predictor = FC(name_scope=self.full_name() + ".bow_predictor",
size=self.num_token_embeddings,
# "The number of tokens in vocabulary. "
bias_attr=False)
bow_logits = self.bow_predictor(latent_embed) # [batch size, 1, num_tokens]
outputs["bow_probs"] = layers.softmax(bow_logits) # [batch size, 1, num_tokens]
bow_probs = F.unsqueeze(outputs["bow_probs"], [1]) # [batch size, len_pred, num_tokens]
bow_probs = layers.expand(bow_probs, [1, label.shape[1], 1])
if self.label_smooth > 0:
bow = layers.cross_entropy(bow_probs, smooth_label, soft_label=True,
ignore_index=self.padding_idx)
else:
bow = layers.cross_entropy(bow_probs, label, ignore_index=self.padding_idx)
bow = layers.reduce_sum(bow, dim=1)
token_bow = layers.reduce_sum(bow) / tgt_len
bow = layers.reduce_mean(bow)
详细代码可以参考 PLATO 源码
Response Selection
二分类任务,通过输入隐变量位置对应的 logits,计算交叉熵,文中对这个优化目标记为 。对于一个问答对,其正例就是本身,而负例侧是在无关的语料库中,随机的一个答案。在 plato 源码中可以发现,负例是在训练过程中创建的,即简单的采用同一个 batch 下除自身以外的其他样本作为负例。
而后通过隐变量 对应位置的 hidden state(正样本和负样本各自有一个 hidden state)计算 损失为:
总体优化目标
总体的优化目标为以上介绍的三个损失的加权平均:
论文中没有提三个损失的权重,源码中有用于调整各个 loss 的超参,不过这些超参默认值都是 1。整个预训练用了 8 张 V100(32G) 训练了 2 周 。具体参数可以参考原论文。
推理过程
对于一个历史对话 context:
- 首先给
context添加上不同类型的latent_embed。原本输入为batch size条,变换后,变成了batch size * num_latent条。 - 对
batch_size * num_latent条输入分别进行预测,得到所有 latent 对应的回复 。 - 通过 Response selection 阶段训练的判别器,对所有生成进行打分,选取分数高的作为最终回复。
模型使用
PLATO 采用 UnifiedTransformerModel。对应的使用方法在 PaddleNLP 中可查看到。
from paddlenlp.transformers import UnifiedTransformerModel
from paddlenlp.transformers import UnifiedTransformerTokenizer
model = UnifiedTransformerModel.from_pretrained('plato-mini')
tokenizer = UnifiedTransformerTokenizer.from_pretrained('plato-mini')
history = '我爱祖国'
inputs = tokenizer.dialogue_encode(
history,
return_tensors=True,
is_split_into_words=False)
outputs = model(**inputs)
PLATO-2
来自论文 PLATO-2: Towards Building an OpeDomain Chatbot via Curriculum Learning
PLATO-2 为 PLATO 升级版,除了模型规模不同外,其与 PLATO 的主要差别在于预训练的方式。此外 PLATO-2 用的是依旧是 Transformer encoder 架构,但是采用了 pre-normalization。
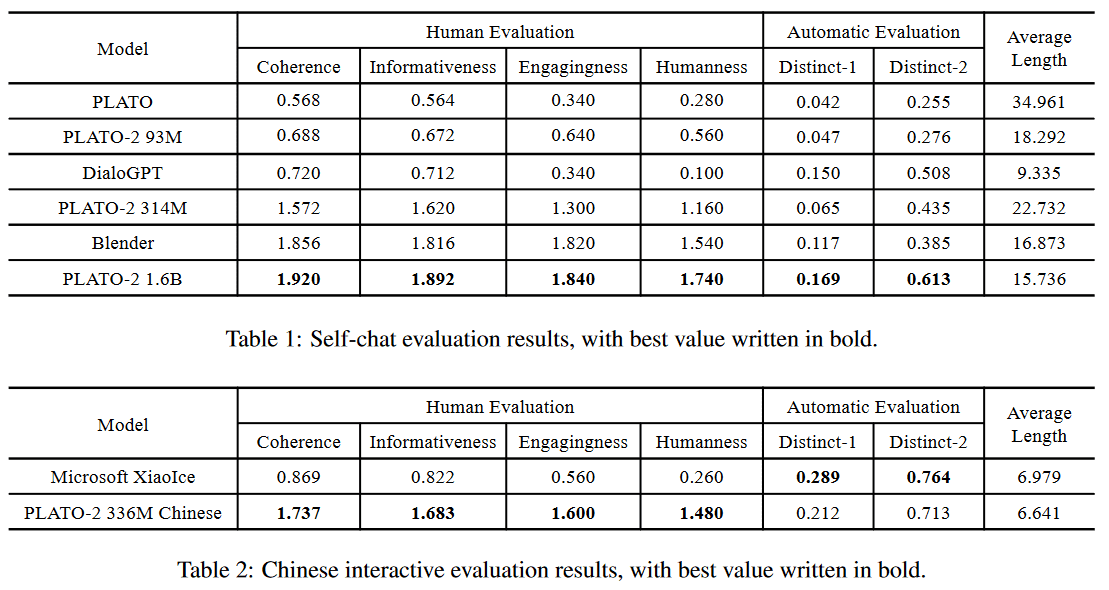
PLATO-2 效果如下:
预训练过程
文中提出了 curriculum learning 的预训练方案。
Step 1
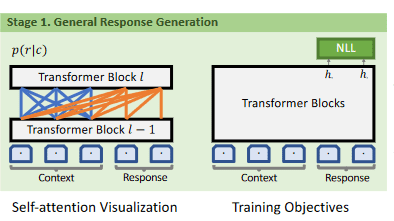
不采用 latent embedding, 直接利用 UniLM 的方式,在正常的生成任务上优化传统的 NLL loss。
Step 2.1
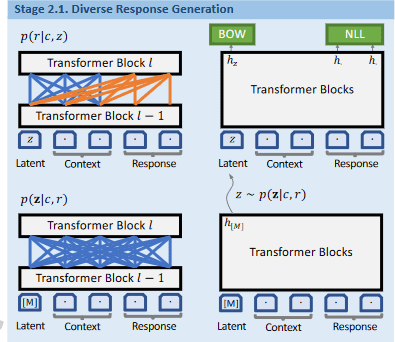
首先计算 latent_embed,该操作于 PLATO 不同。PLATO 中计算 latent_embed 的方式大致为:
x = nn.embedding([context, response])
x = gumbel_softmax(dense(x))
latent_embed = x.matmul(latent_embed_params)
而 PLATO-2 则采用了
x = model([context, response])
x = gumbel_softmax(dense(x))
latent_embed = x.matmul(latent_embed_params)
差别就在于计算 x 过程中,PLATO-2 用的是整个 encoder 进行编码,这也会更耗时。
得到 latent_embed 之后,我们对 进行优化, 优化方法与 PLATO 相同。 参考代码
Step 2.2
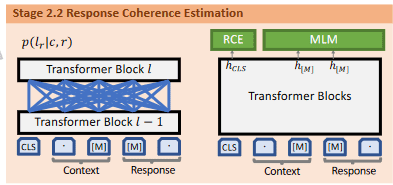
额外训练一个打分器,如图所示,优化的目标和 BERT 预训练时相同,为 。其中 与图中的 大同小异,原理都是预测 Response 是否为 Context 的下一句话。
该步骤与 PLATO 中的 Response Selection 对应,只是在 PLATO-2 中,优化目标多了一个
推理
推理过程同 PLATO,先生成所有 latent 对应的回复,然后在用 step 2.2 训练来的打分器打分。
任务式对话
PLATO-2 在 DSTC9 的部分任务上表现出色,百度也对 PLATO-2 在该任务上的操作提供了论文。相关论文:Learning to Select External Knowledge with Multi-Scale Negative Sampling. Paper link
网友的笔记参考链接
其他
有网友提到第一阶段的预训练花了 1.8M 个 STEP,LOSS 仅下降到 2.66。作者建议 24L 模型的学习率可以用 5e-4 或者更大,Knover 中 24L PLATO 默认的学习率是 1e-3。
论文 STEP 2 采用了多种学习方案,但是并没有消融实验。此外作者并没有公布中文数据集的具体来源。隐约感觉,PLATO-2 的好效果绝大部分来源于语料?
PLATO-2 的 ISSUE 中提到,论文中 table 6 的 batch size 是根据 token 数量来计算的。源码中给到的 batch size 是 8169,通过语料的平均 token 长度换算过来的话,源码中的 batch size 会稍微大一些。
PLATO-2 的预训练权重目前只开源了英文版的,想要中文版的话只能自己收集中文数据集训练了。
PLATO-XL
来自论文 PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
PLATO-XL 仍然采用于 PLATO-2 相同的架构,只是规模变大了,训练方法和预料也有所不同。 PLATO-XL 的训练代码似乎并没有开源,仅英文预训练权重有开源。论文中大致介绍了大模型效果更好,以及一些大模型训练及推理的解决方案。相比于 PLATO-2,PLATO-XL 似乎想说明:花里胡哨的训练,不如大模型,好语料来的管用。
模型训练
模型的优化目标只剩下一个 了。
相比于 PLATO-2,PLATO-XL 的训练预料中,考虑到了多人对话的场景。因此文章提出了 Multi-Party Aware Pre-training,即在 role_embedding 中区分 2 个以上的角色(在 PLATO-2 中,只有机器和用户两个角色,因此只用 和 进行区分)。
由于模型规模大,因此 pre-normalization 和 scaled_initialization 都被采用了,以此提高训练效果。整个训练用了 256 张 V100 32G,训练周期未知。效果如下图:
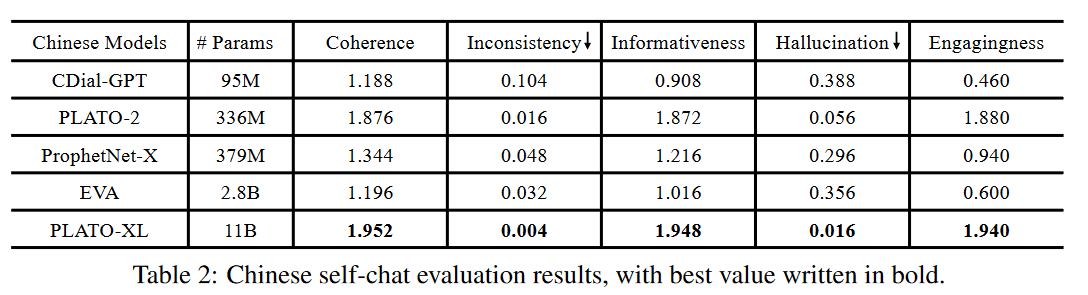
由于 PLATO-XL 模型较大,paddle 官方采用了 PaddleNLP FasterGeneration 进行高性能预测。参考代码
PLATO-KAG
来自论文 PLATO-KAG: Unsupervised Knowledge-Grounded Conversation via Joint Modeling。
相比于之前 PLATO 系列论文,该文主要介绍如何使用 PLATO 架构来进行具备额外知识信息的问答。代码链接
模型训练
模型训练流程如下,整个模型采用 PLATO-2 的权重进行初始化。
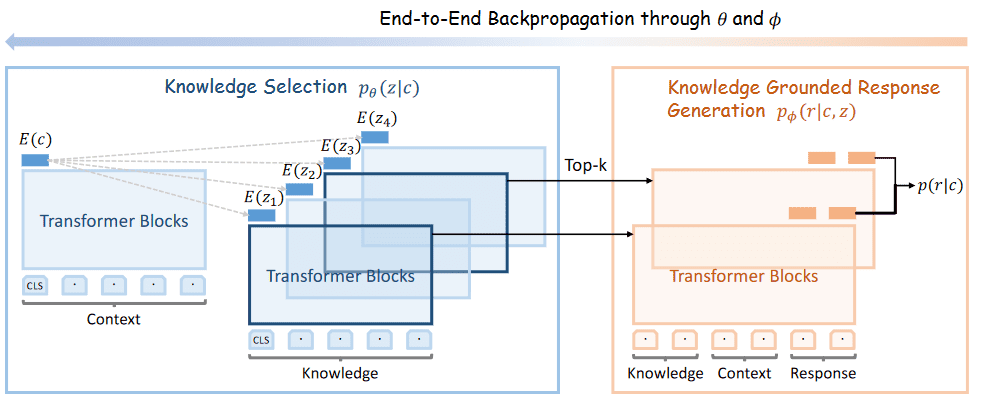
Knowledge Selection
用同一个编码器编码 Context 以及 Knowledge 片段,得到隐状态 。而后通过 计算 context 和 knowledge 片段的相似度。
在计算损失时, 计算 softmax,而后只对 Top K 个 knowledge 对应的 softmax 进行优化。
论文中对 不同的 K 值进行了测试,结果展示了,在训练时选择 Top 8 个相关知识片段进行训练,模型最终的 PPL 和 Recall 都会更好。
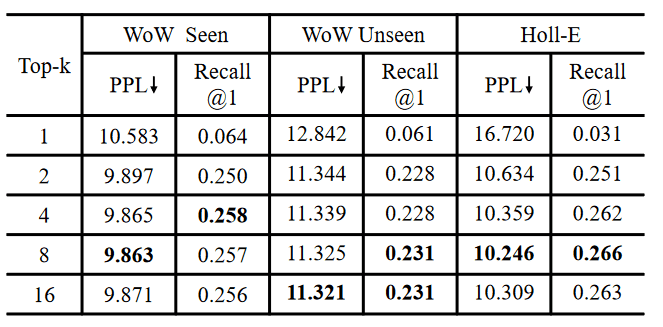
但是 K 越大,对应的训练资源要求就越大,实验中 k=2 时,其效果也不比 k=8 小多少。
Response Generation
由于上一个任务中,选出了 Top K 个可能合适的知识片段,因此在生成任务中,我们需要对这些片段逐一进行拼接、预测和优化。
如原输入形状为 [batch_size, len_seq], 那么训练过程中预测结果的形状就会是 [batch_size * K, len_seq]
Balanced Joint Training
训练过程中,同时对 Knowledge Selection 和 Response Generation 进行优化。参考代码
文中提到了使用超参 来调整两个损失之间的权重,即整个优化目标为:
其中 为 Knowledge Selection 对应的概率。生成任务的概率 用 参数来调整。
但是在 Knover 的源代码中,笔者并没有找到这个设置,整个 PLATO-KAG 训练过程仅是简单地将 Knowledge Selection 任务和 Response Generation 任务权重简单地做了相加。
此外,模型采用 PLATO-2 的预训练权重初始化。
在推理过程中,仅仅选择相似度最高的 knowledge 片段进行推理。
参考
[1] TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
[2] Learning to Select External Knowledge with Multi-Scale Negative Sampling
[3] PLATO-KAG: Unsupervised Knowledge-Grounded Conversation via Joint Modeling
[4] PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
[5] PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
[6] PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning