Prompt 范式(一)

《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》 这篇 prompt 综述中,详细地对 NLP 进展与目前 prompt 的作品进行了充分的分析与总结。同时作者在 github 上 对 prompt 论文进行了总结。Prompt 这个系列将根据这些 prompt paper 进行笔记总结与梳理。
本文中将包括 PET, Prefix-Tuning, P-Tuning 三个模型对应的论文笔记。
Prompt 综述
论文:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing 极力推荐下载并阅读这篇长达 46 的论文 !
笔者第一次阅读该综述时仍对某些部分(如 Continuous prompt)感到十分困惑。于是便决定先深入理解和阅读相关 prompt 论文与模型。相信之后再次浏览该综述时,会有更多的收货。
相关网文:近代自然语言处理技术发展的“第四范式”
NLP 发展经过了四个阶段,可以通过四个关键词来分别概括:
- feature engineering - 注重特征工程的机械学习(完全监督学习)。
- architecture engineering - 注重模型架构的机械学习、深度学习。
- pre-train and fine-tune (objective engineering) - 基于预训练、微调
- pre-train, prompt, and predict (prompt engineering) - 基于预训练,提示(prompt)和预测
而目前,我们似乎正在从第三阶段迈向第四阶段。
prompt 的基础

什么是 Prompt 呢?我们先来看一种基础的 prompt 方法。如上,prompt 方程将一个输入进行拓展与延伸,有点类似于小学语文老师教书时用到的举一反三。对于一个样本(我爱看这部电影, 正面),通过 prompt 范式方程,我们可以从输入语句联系到其他相关的知识点(符合语言逻辑的知识点),如:这是一部很 棒 的电影。(或电影 是一个实体等)。然后我们对原输入与拓展部分进行拼接,得到了新的模型输入:我爱看这部电影。这是一部很 棒 的电影。
Prompt 的直觉
引用文章 -近代自然语言处理技术发展的“第四范式” 中的表述:解决任务时, 大家都是希望让 预训练语言模型和下游任务靠的更近,只是实现的方式不一样 。
Fine-tuning 中:是预训练语言模型“迁就“各种下游任务。 具体体现就是上面提到的通过引入各种辅助任务 loss,将其添加到预训练模型中,然后继续 pre-training,以便让其更加适配下游任务。总之,这个过程中,预训练语言模型做出了更多的牺牲。 Prompting 中,是各种下游任务“迁就“预训练语言模型。 具体体现也是上面介绍的,我们需要对不同任务进行重构,使得它达到适配预训练语言模型的效果。总之,这个过程中,是下游任务做出了更多的牺牲。
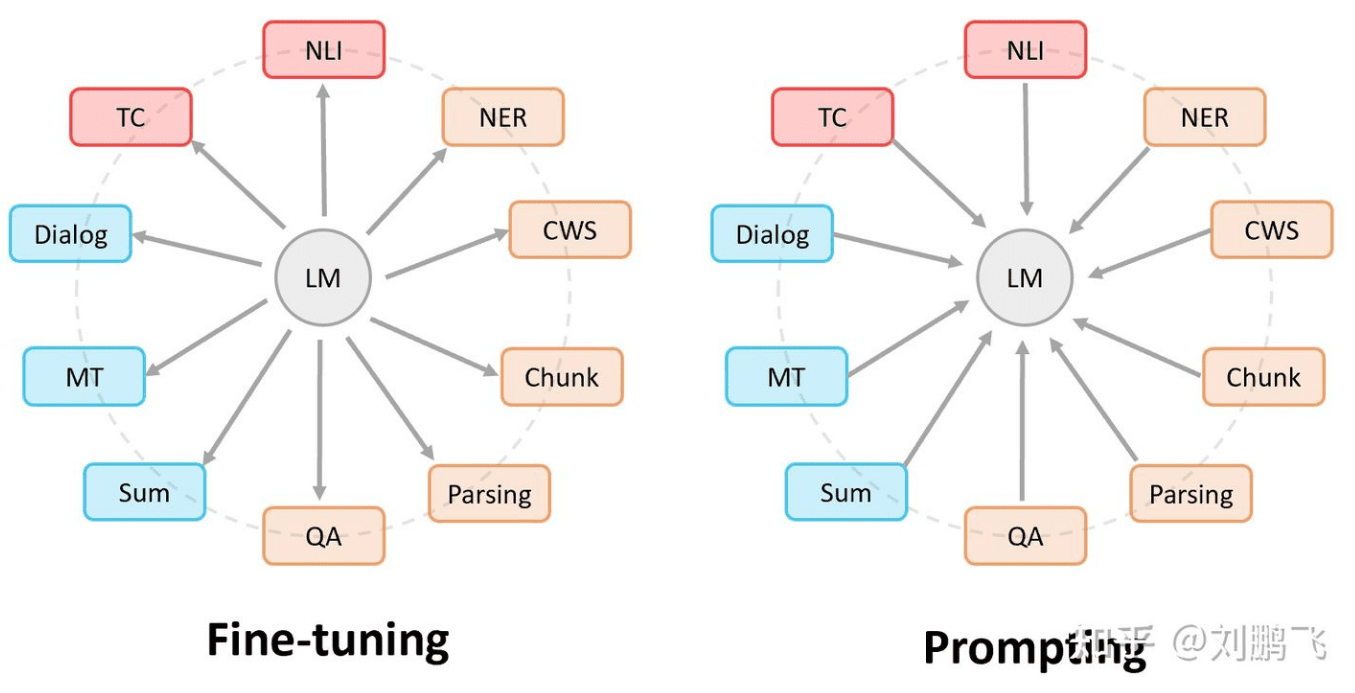
(来源:知乎 近代自然语言处理技术发展的“第四范式” )
由上面的对比,不难看出我们希望尽可能保留预训练模型在大预料库中学习到的知识,这一点体现在大部分 Prompt 的方式都会冻结预训练模型权重,尽可能保留模型的架构。同时通过提示的方式来引导模型完成下游任务。
Prompt 工程
近些年来 prompt 的形式可以总结为两种 - 离散型 与 连续型:
个人理解的离散型有几个关键词:需要更多 人工 , 可解码 (大部分离散型的 prompt 都会对应一些单词)它可以分为 cloze prompts 完形填空 和 prefix prompts 续写两种形式。(具体案例可以参考后续 PET 的介绍。)
除了人工生成 prompt,还有其他几种自动生成 prompt 的方式。包括从大语料库中检索包含输入与输出的高频率语句;根据现有的 prompt 进行修改,生成更多 prompt,单词替换等。
既然 prompt 生成的是一个句子,那么我们也可以通过改变这个句子的复杂度来控制模型的学习。对于语言,我们可以用不同方式表达一句话,对一句话进行拓展,将多句话拼接,将一句话分解成多句话。对于 prompt,我们也可以定义
- ensembling 聚合 - 通过加权来更多的去学习优秀的 prompt
- augmentation - 对 prompt 进行筛选或者排序
- decomposition - 将一个复杂的 prompt 分解成多个简单的, 反之为 composition 。
Pet - Prompt 开山
论文:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
由 PET 这个模型来开启 Prompt 之旅再合适不过了。
PET 的主要思想为:我们在小数据集上构造额外的完型填空任务,试图让预训练模型通过这些任务来提高对小数据集的学习效率。
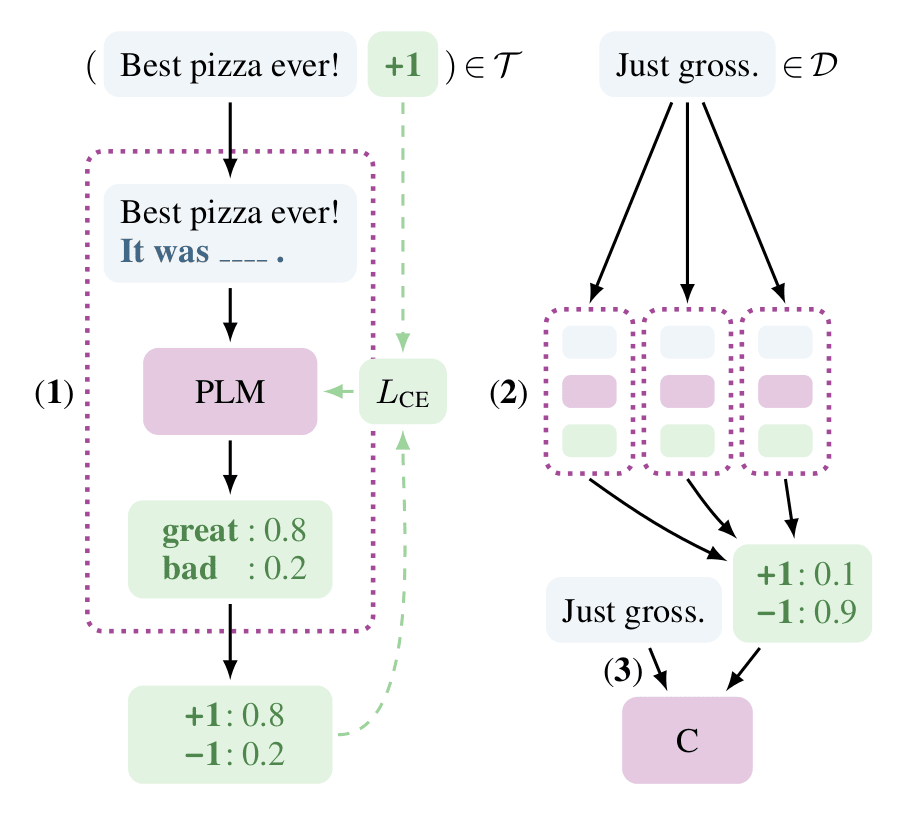
整体流程如上图:
- 根据(1),首先构造出完型填空任务"Best pizza ever! It was __",每个空格有他独特的答案(参考下文)。将 PLM 在构造好的数据集上训练,训练中模型将:一、预测挖空部分单词(属于分类任务),二、完成一个 MLM 任务(类似 bert 预训练,需要对其他单词进行额外 mask)。于是损失函数为:
- 根据 (2),由于数据量小,哪种 prompt 形式好不得而知,因此 PET 针对不同 prompt 训练多个模型;分别对这些模型将他们在小数据集上进行下游任务的 finetune。而后通过 ensemble 加权投票的方式对未标注数据进行 soft-label;
- 根据(3),我们使用 PLM+classification head 对(2)中的 soft-label 进行 finetune。这两步有点类似知识蒸馏。
PET 作者认为,这样做的话各种 prompt 训练出来的模型之间无法互相学习。因此设计了 iPET:
- 与 PET 相同的,我们针对不同的 prompt 训练不同模型。而后随机选择几个模型进行 soft-label,由此获得几份数据集。
- 类似 PET 的(3),通过这几份数据集分别训练出新的模型。
- 迭代以上两个步骤多次后,将所有数据集整合并训练出最终的模型。
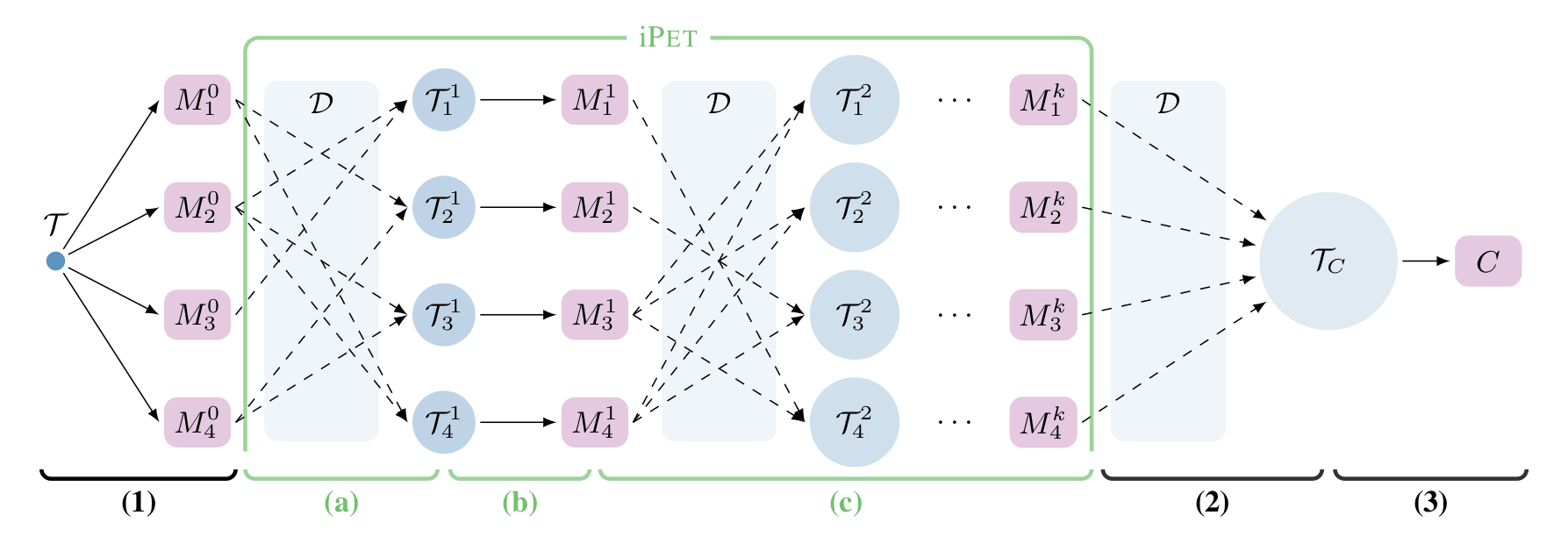
(图:PET(1,2,3)与 IPET(a,b,c)算法大致流程)
Prompt 设计
PET 通过完形填空方式构造 prompt,对于不同的数据集,prompt 的模版也不同。比如,对于原输入语句 a, b:
- 对 Yelp reviews 数据集可以采用:

其中填空的答案将从
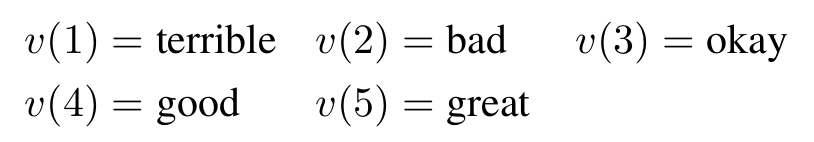
五个类别里面选
实验结果
不出所料的,经过更多训练的 PET 效果明显由于普通的监督学习,毕竟我们可是花了人力构造了额外的数据的。因此有不少网友认为 这样的对比不公平,不能说明 prompt 这个方法有效果(要是把同样的人工构造 prompt 时间拿去标注更多的数据,说不定也能达到同样的效果)。
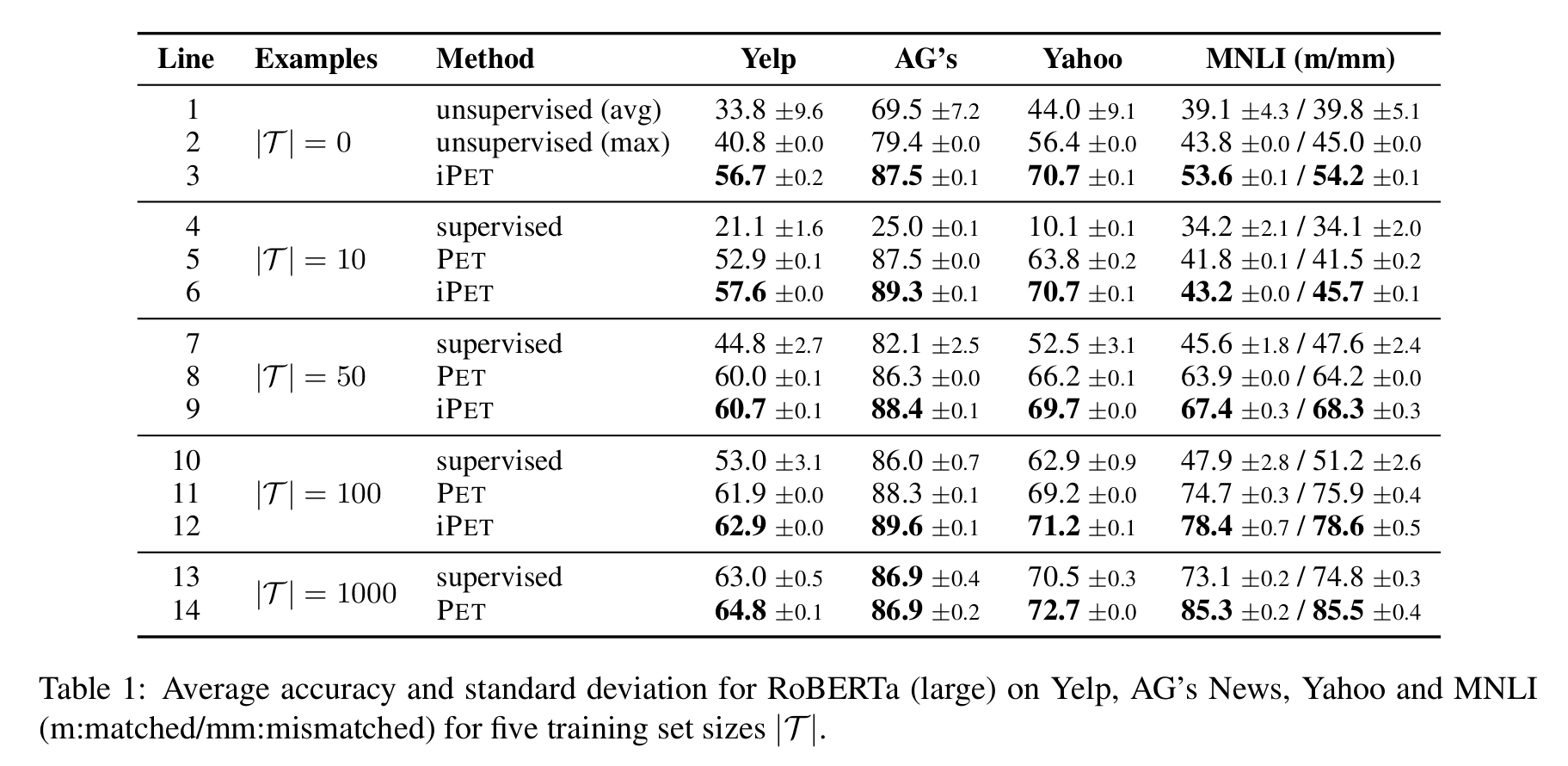
个人看完 PET 也是这种观点,PET 的 prompt 为离散型 prompt,需要额外的人工数据处理,并不能完全体现 prompt 的优点。
Prefix-Tuning
论文:Prefix-tuning- Optimizing continuous prompts for generation
官方代码:https://github.com/XiangLi1999/PrefixTuning
不同与 PET, Prefix-Tuning 使用了参数化的 prompt 来引导模型解决不同的下游任务。这种参数化的 prompt 也被称为 continous prompt。不同于 PET 的离散型 Discrete Prompt,连续型 prompt 由非字符的参数组成。
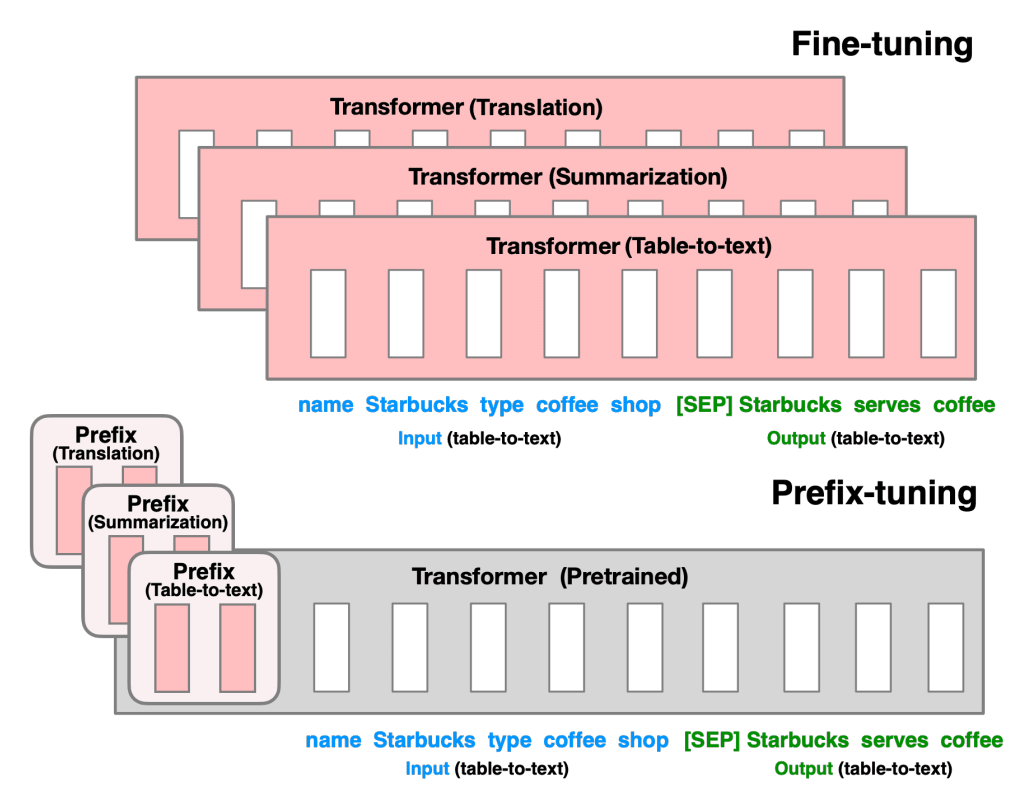
Prefix-tuning 的直觉
对于原先的 GPT2 模型,我们在不同任务上 finetune 的时候经常需要对所有的参数进行微调,然后保存不同模型的权重。因此,如上图,论文作者提出在模型前加入可学习的 prefix 参数来引导整个模型的注意力机制,在区分不同下游任务的同时提高模型的学习能力,尽可能多得保留原预训练模型的知识。

(图:添加 prefix 实例)
参考以上例图,原输入序列 添加 prefix id 后变成了 。在传统的 GPT2 中计算隐状态的方式为:
不同于 LM 模型,prefix 部分隐状态的计算方式为取索引,因此对于添加 prefix 之后的模型,隐状态计算方式为:
其中 为对应 prefix 的 index。
作者发现若直接对 prefix 参数进行更新会出现学习不稳定,模型表现变差等问题。于是添加了一个临时的 MLP 层与更小的临时参数矩阵来计算 prefix 参数,即:
当训练完成后,只保留 。同时在训练过程中 其他模型参数将会被冻结 。
从作者的实验结果看出,prefix-tuning 在数据量小的时候,能够用更少的参数实现更好的效果。
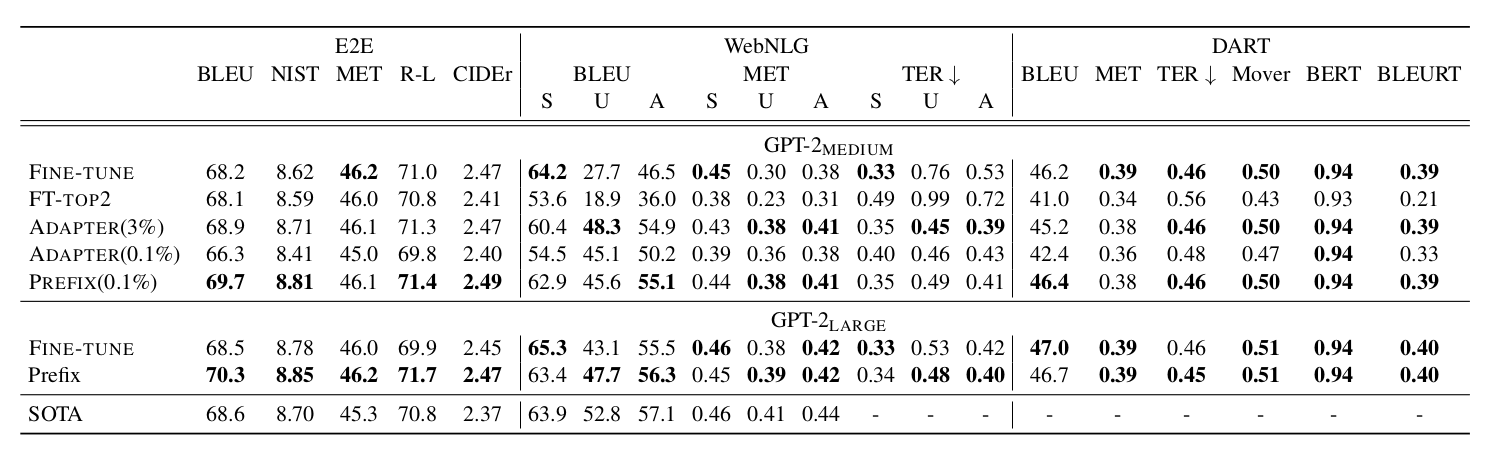
P-Tuning
论文:P-tuning-GPT Understands, Too
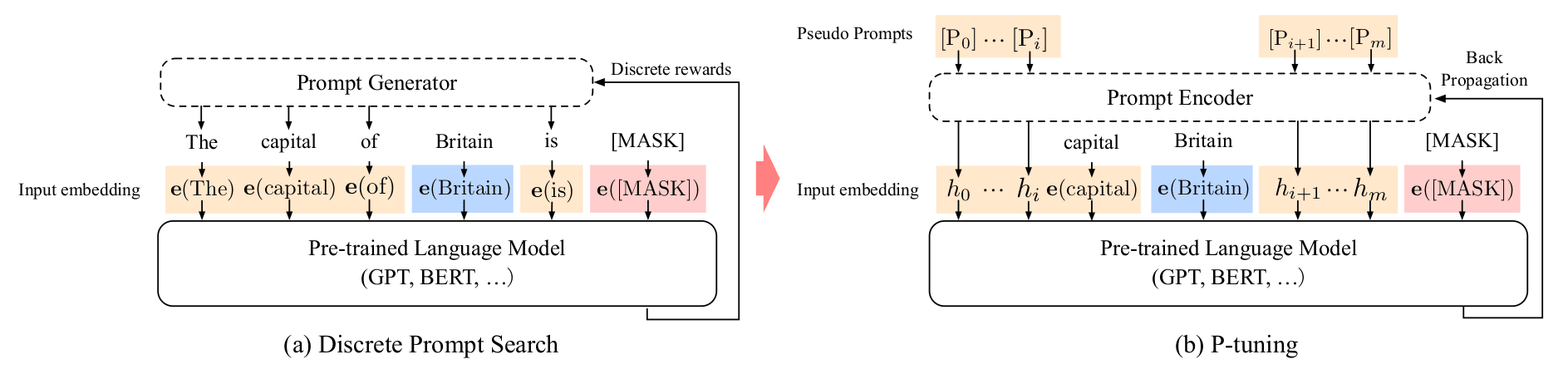
(图:P-tuning 与 Discrete Prompt 差别)
P-Tuning 采用的也是参数化的 Prompt,先来看他与 Discrete Prompt 的区别:
假设原输入为: 。
Discrete Prompt 使用 PLM 的 embedding 层 将原输入编码成 , 此处的每个 P 对应一个 token,如(a)所示;
而 P-Tuning 则使用可学习的参数替代,将原输入编码为 , 此处 P 为 pseudo token,并没有实际指向的 token。 (prompt 重要的是放在哪,和能不能引导模型解决任务,而非表现形式。)对于 LM 模型,将 prompt token 置于前缀是很重要的。
与 prefix-tuning 不同的是,此处 prompt 的编码将与其他 embedding 一起传入预训练模型中进行训练。
P-tuning 的设计
为了使得 prompt 的编码之间存在相关性,并解决 embedding 分布离散 (Discreteness)的问题(PLM 中的 embedding 高度离散导致使用 SGD 会很容易陷入局部最优),作者使用 BiLSTM 计算 prompt 的 hidden state。
根据网友的咨询与解析 论文作者认为此处一种更自然的做法 对下游任务目标与其他任务(如 LM 或者 MLM)一起优化 ,类似 PET 的优化方案。
此外作者还发现加入一下小标志符号有助于 NLU,如“[PRE][prompt tokens][HYP]?[prompt tokens][MASK]”中的问号。
作者对比了以下四种训练方式:(MP 代表 Manual Prompt)
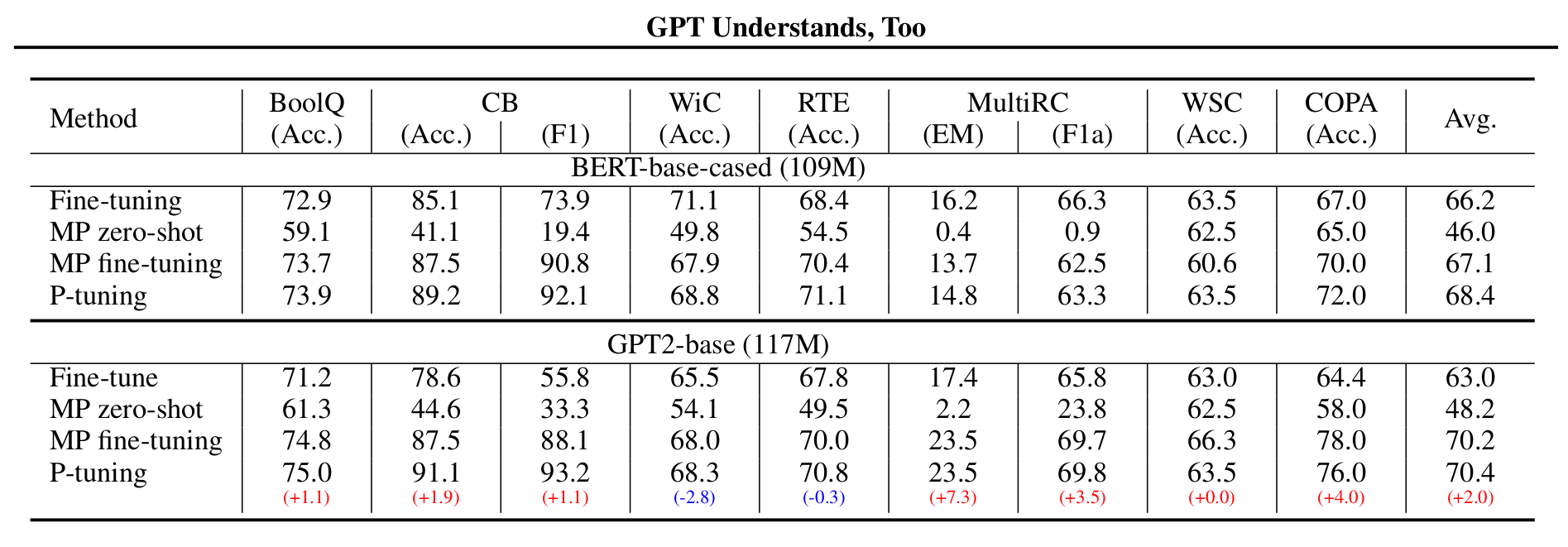
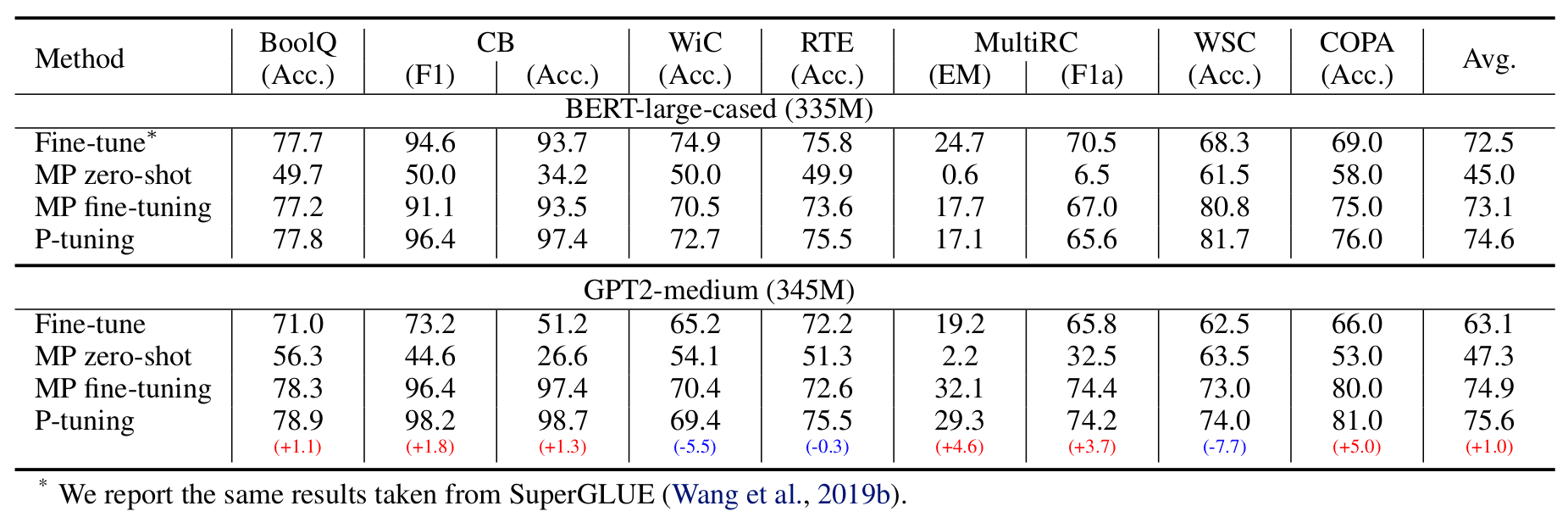
结果是 GPT2 在大部分数据集上优胜。
几个关注点:
- 当标注数据较少的时候,我们只学习新添加模版的权重, 冻结原 PLM 的权重 ;当标注数据充足时,对所有权重进行微调(有点类似经典的 bert 微调,但是这种形式效果更好点。)
- 由于冻结了大部分的权重,因此在算理有限情况下,我们一定程度上可以使用规模更大的模型了。
同时网友也对中文进行了 P-Tuning 的实验 代码
参考
ZHOU-JC - Pattern Exploiting Training(PET)范式
论文
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- Prefix-tuning- Optimizing continuous prompts for generation
- P-tuning-GPT Understands, Too