Prompt 范式(二)
本文总结了 Prompt Tuning(The Power of Scale for Parameter-Efficient Prompt Tuning)、UDG (Towards Zero-Label Language Learning) 读论文总是枯燥且难熬呢,于是便尝试在阅读时便对论文进行了知识点的梳理与记录,有助于加深理解与记忆。希望这份笔记也能提供一些小小的帮助
Prompt Tuning
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
论文使用了 encoder-decoder 结构的 T5 模型对参数化的 prompt 进行了研究。
主要方法:
使用可学习的 prompt 参数作为输入前缀与长度为 的原输入 embedding 拼接得到 ,其中 为 prompt 的长度(超参), 为 embedding 的维度大小。训练时针对 进行优化,冻结预训练模型权重,单独对 prompt 参数进行训练与更新。
总体上 Prompt Tuning 与 P-Tuning (来自论文 P-tuning-GPT Understands, Too) 较为相似。但 Prompt Tuning 的 prompt 参数全部置于左侧,并且论文将注意力集中在了冻结模型权重的一系列实验上,更好的验证了 prompt 的效果。
由实验数据可看出,仅对 prompt 参数进行学习,在模型规模足够大时媲美对模型全参数进行 finetune。由于更新的参数熟练减小,训练难度降低,同时也不需要针对不同的任务各保存一份完整的 T5 模型,只需储存 prompt 参数部分即可。
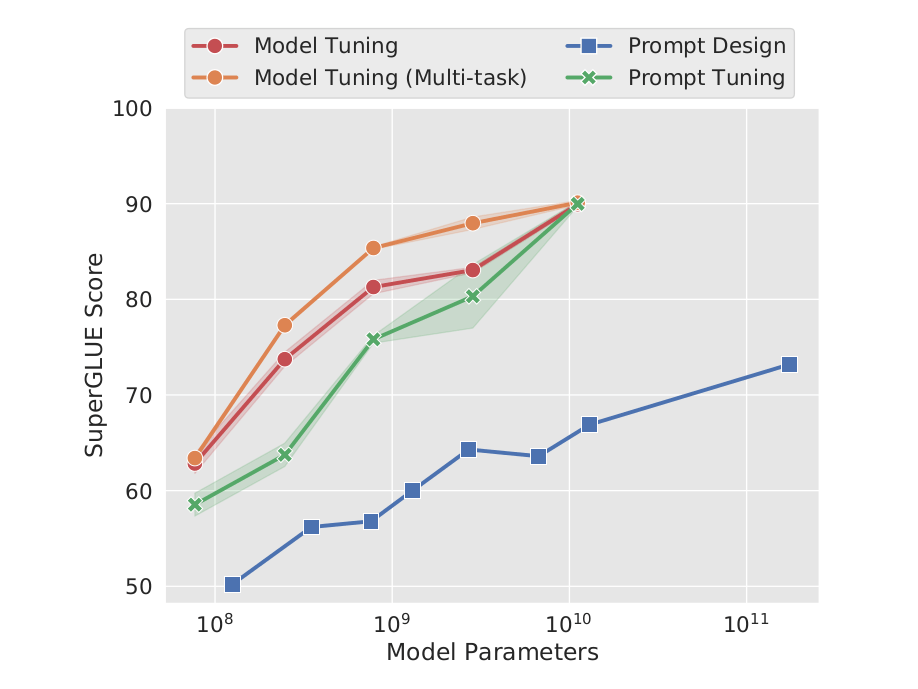
(图:T5 模型在不同训练方式下的结果)
Prompt 参数长度
参考下图 a,论文针对 1,5,20,100,150 五种不同的 prompt 参数长度进行了测试。当 prompt 参数长度超过 20 时,整体模型的效果提升并不是很明显。当预训练模型较大时,不同 prompt 参数长度的表现差异较小。
Prompt 参数初始化方案
如下图 b 所示,sampled vocab 与 class label 的效果明显好于随机初始化。
- sampled vocab :从 5000 个 T5 字典最常用的 token 中提取。
- Class label :从任务 label 对应的 token 中提取。由于任务 label 通常数量较少,当任务 label 不够满足 prompt 参数长度时,使用 sampled vocab 进行填充。当一个 label 存在 multi-token 时,取其平均值。
有趣的一点是,在训练结束后,作者对这些 class label 初始化的 prompt 参数与所有 token 的 embedding 计算距离,发现与其距离最短的 token 表征是他们对应 class label 的初始值。
预训练目标的影响
取消预训练中的 Span Corruption
Span Corruption 是 T5 预训练任务之一,其将完整的句子根据随机的 span 进行掩码。如:原句:“Thank you for inviting me to your party last week”
Span Corruption 之后得到输入: “Thank you [X] me to your party [Y] week”;目标:“[X] for inviting [Y] last [Z]”。其中 [X] 等一系列辅助编码称为 sentinels。
作者认为使用这种不自然的 sentinels 来引导回答的学习方式对 prompt 不利。图 c 诡异的曲线似乎印证了作者的猜想,随后作者采用了 LM Adaptation (试图将 T5 转变成 GPT3 的风格),使得模型总是输出一个实际的文本。同时所有任务都被转变成了文本生成任务(与 T5 的 "text-to-text" 方法相似)。
综合全部结果可看出,适当地增加模型的规模,可以很大程度上减小超参带来的波动与影响。
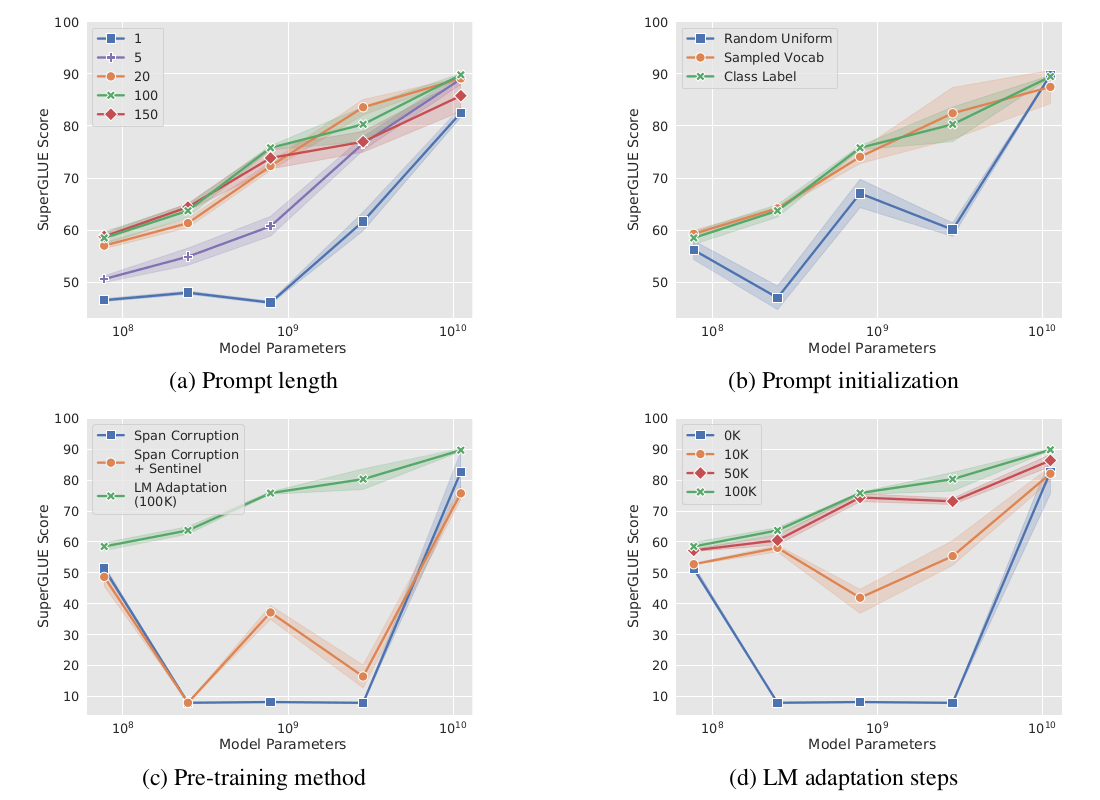
Prompt Ensemble
传统的 ensemble 通常需要保存不同的模型,并逐一运行计算结果后聚合。对于 prompt tuning 的模型,我们只需要对同一个模型训练不同的 prompt 参数,然后在一个 batch 下计算结果就行(非常方便啊)。并且结果也相对好于 Average Ensemble 和 Best Ensemble。
Unsupervised Data Generation (UDG)
论文:Towards Zero-Label Language Learning
UDG
Unsupervised Data Generation (UDG)的主要思想是:使用一个预训练好的 GLM 模型(如 GPT3)来生成训练数据集,从而实现 "zero-label Language learning"。比较特别的是,UDG 根据给定的标签来生成对应的输入语料,而非对现有数据打标签。同时 UDG 使用未标注数据集作为 prompt 提示,来提高生成数据的质量。
给定:
- :任务描述语句 Task Description
- :K 个未标注的样本
- :伪标签。
- :任务转变函数。将标签 映射到语言表述上 Label Description
我们可以使用 top-k sampling 来对训练集的输入 进行采样:
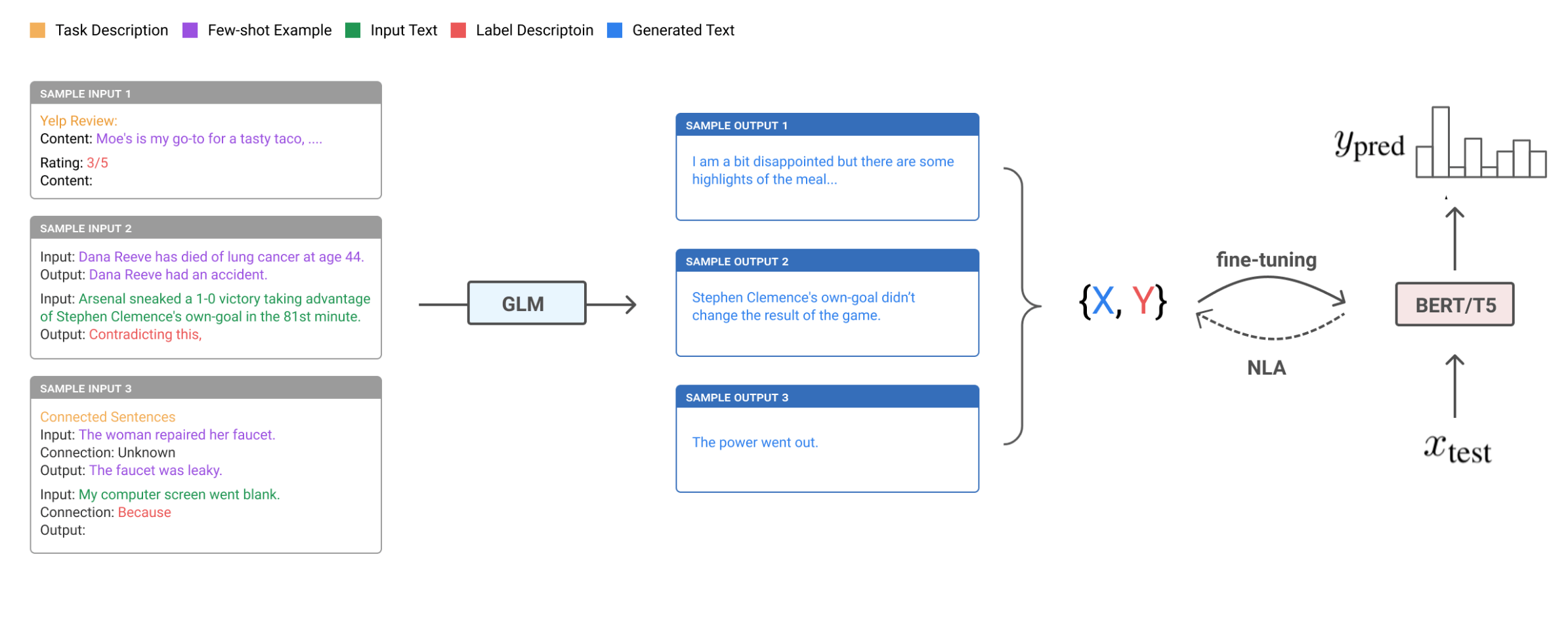
(图:UDG 整体框架)
作者提出,若使用给定的 输入 X 来预测标签 Y(类似 soft-label),我们可能无法很好地发挥 GLM 的实力来生成最优的训练数据。 在真实的网络文档中,label 通常出现在输入文档之前。 比如 IMDB 的评分就总是出现在评论前面。
这个现象似乎合理:总结性的内容(如点题句)通常出现在一段表述的前段,这种开门见山的方式这样使得文章或者网页内容结构更清晰,读者有更好的阅读体验。
论文在 背景描述 一节提到了 few-shot inference。 few-shot inference 的大致想法是:
若我们要通过输入 预测 ,可以使用一个任务描述 和 个相关的输入输出数据对 进行提示,使任务变成:
可以认为 few-shot inference 尝试从其他 带标注的数据集 获取提示,来提高模型的预测能力,使得预测结果 更准确。但同样是采用数据集作为 prompt 来提高模型输出水平,few-shot inference 却需要使用带标注的数据集,效果还不及 UDG。
NLA - Noisy Label Annealing
作者发现生成的样本中有许多噪声,因此提出了一种样本过滤方式 Noisy Label Annealing:模型训练时, 在时间步 ,若模型对某个样本的预测结果高于某个阀值 ,并且预测标签不同于生成样本的标签时,将该生成样本移除。实验中 为 0.9(毕竟模型初期比较不稳定,很容易误判),并随时间步增加逐渐下降到 , 为标签类别数量。
在 NLA 处理后,我们便可以在 NDG 生成的数据集上为下游任务 finetune 一个模型。(感觉有点知识蒸馏的味道)。
实验与结果
理论上,用于参考的样本数量 越大,模型得到关于输入的信息越多,生成的数据集质量也就越好。 与 的实验结果差别不是很大,一定程度上受限于模型输入的最大序列长度,当参考样本数量较大时,我们不得不根据输入长度对其进行截取。
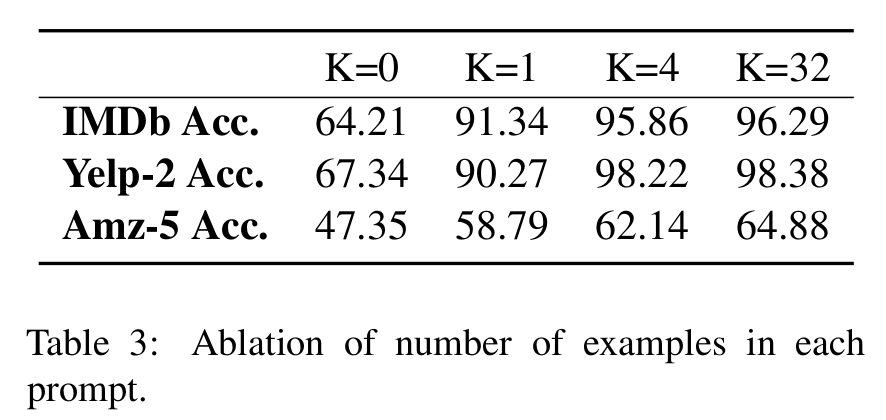
UDG+NLA 组合方式的绝大部分指标优于 few-shot+UDA,同时使用 BERT LARGE finetune 的结果优于 Supervised Learning。
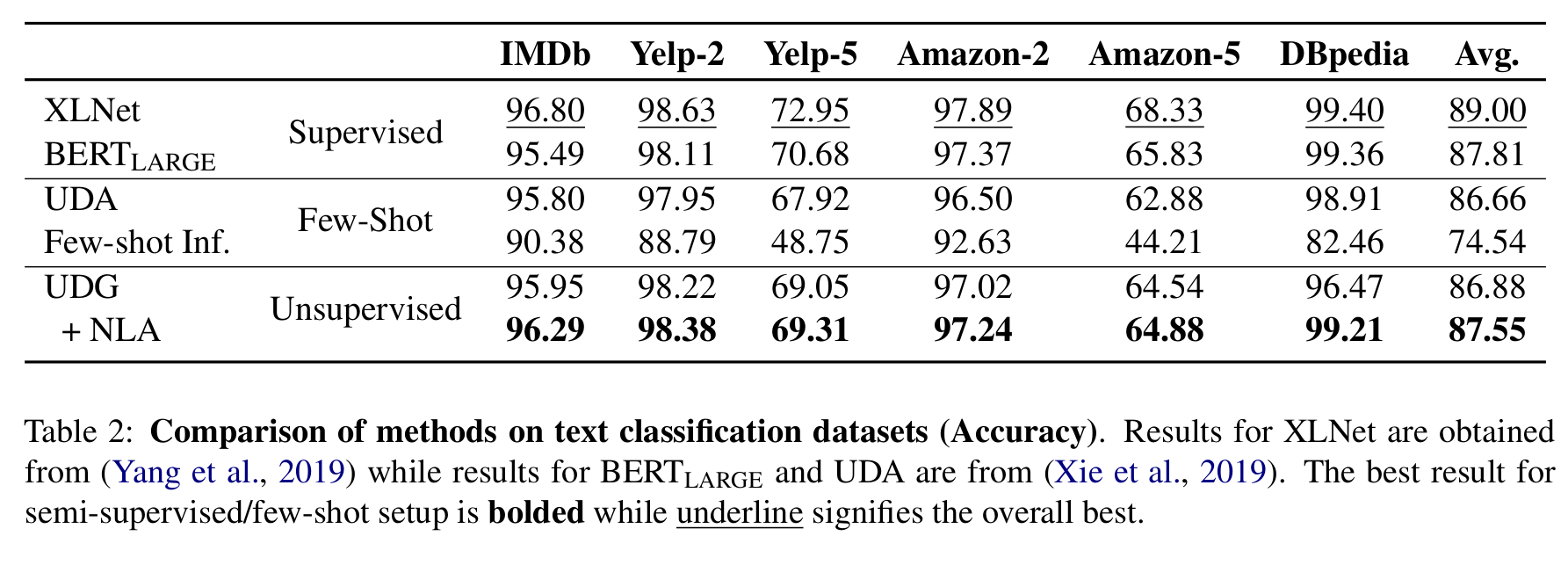
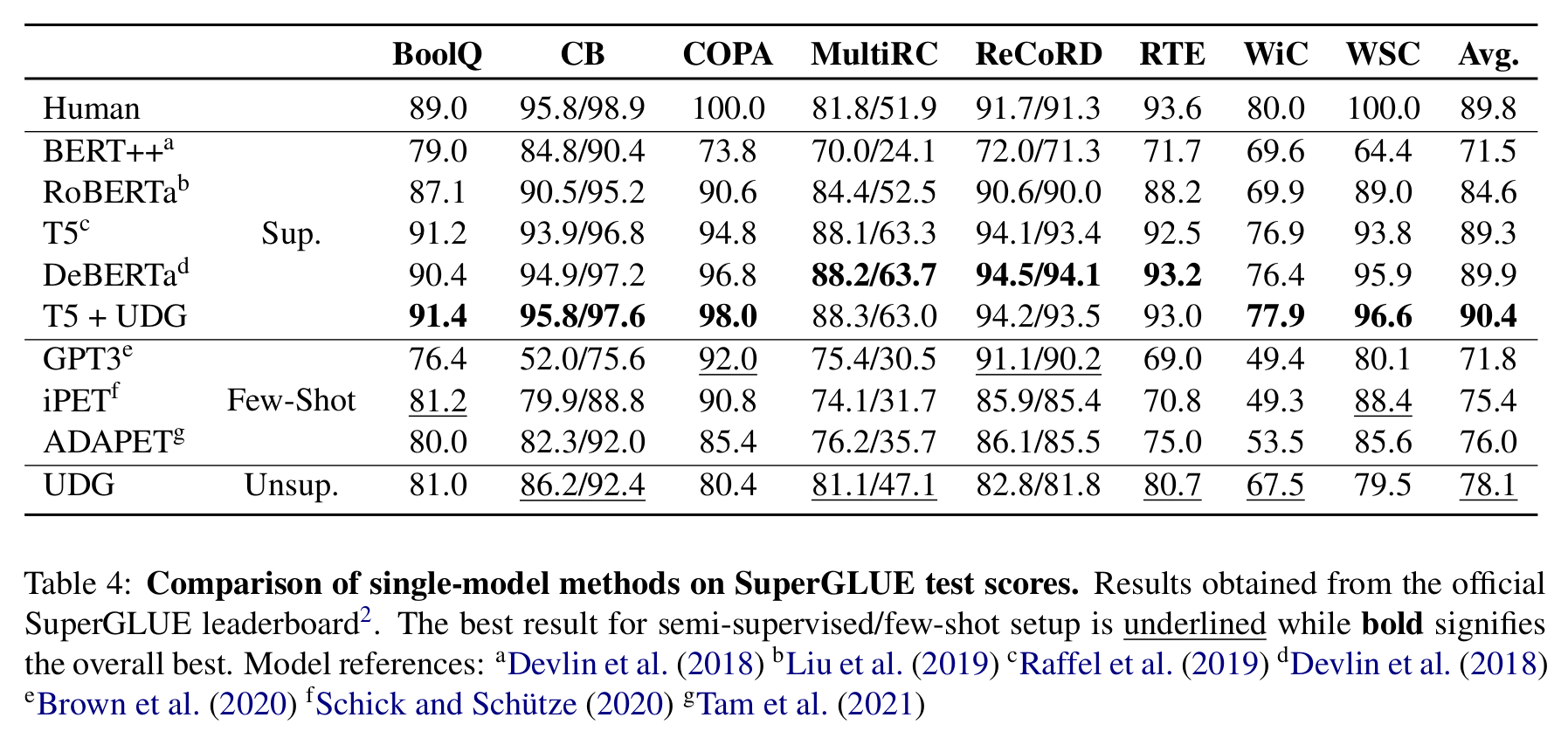
下图结果显示,在已有标注数据集上,使用 UDG 进行数据增强(T5 + UDG)可以进一步提升模型效果。