python 高性能编程
本文章以 《python 高性能编程》一书为基础,对 python 编程下代码性能优化进行梳理。
最重要的笔记
永远不要把某些优化技术一直当做信条。程序运行效率可能会因为不同原因改变,如 CPU 架构、内存缓存层级、指令流水等。对代码的剖析一定要落实到真实的生产数据!最后,不要迷失在这个极客工具里,确认你交付了相关的问题。
python 代码的优化方向与思路总结:
性能诊断: 确定各部分代码的效率,包括速度、内存等,以选择优化方向。常用工具:line-profile, monory_profiler, dis, /usr/bin/time 等。
利用 Python 的丰富生态系统: 这也是最重要的一步!如果别人写的某些库已经能够很好的解决你的问题,那么没必要浪费更多的时间。如果他们的库不能达到性能要求,那也可以考虑基于他们的代码进行改进。
- 算法与数据结构层面优化:
- 算法: 多刷力扣。
- 数据结构: 采用合适的数据结构,关注数据结构实现细节。如对于 hash 表,可以考虑采用不同的 hash 函数以减少 hash collapse 的概率。
- 矢量计算: 例如矩阵计算,使用 numpy 等进行矢量计算可以提高效率。
- 考虑通过
numexpr优化 numpy:numexpr很多优化都和缓存有关,是否采用他取决于你的缓存和你的矩阵大小。 - 提高硬件配置: 程序效率受计算、数据传输两方面影响。计算效率上提供 CPU、传输效率上提高 RAM 以及缓存。
- 并行计算: 首先考虑已有的并行计算模块,如
multiprocessing等
- 进程间通信: 考虑使用 queue 或其他队列库等来实现进程间通信。进程间通信不一定能提高代码效率。
- 数据共享: Redis、Multiprocessing 中的 Value、Array、RawArray 等都可以提供共享。共享时候需考虑给数据上锁以避免数据丢失。
- 编译成 C: 可能直到 python 的 JIT(及时编译器)技术成熟之前,Cython 都是最好的选择。本书主要以 Cython 为例讲解
- 变量类型优化、更换 python 函数为 Cython 函数: 使用 Cython 语法给变量进行类型定义,或者为函数输入输出进行类型定义。主要是为了减少 c 变量转化为 python 变量时的损耗。
- 取消 Cython 保护性检查 :取消如除 0 检查、列表边界检查等条件。但这个并不是一直能提高效率的。
- 还有其他如: 采用并行计算 等。
- 字节码层面的优化:
- *优化命名空间的搜索: 包括优化导入包方式,优化变量引用方式(
import math+math.sin()慢与import math.sin+sin()慢于sin=math.sin+sin()) - 减少内存分配次数:**移除掉没必要的变量赋值,不仅可以减少字节码。还能够较少内存查找、回收、分配等一系列开销。
- 集群: 该书中讨论了 Parallel Python、IPython Parallel 和 NSQ 三种集群化方案。
- 工作队列: 能够给系统带来鲁棒性
使用更少的 RAM: 考虑牺牲掉一部分精度,使得用较少的 RAM 保存更大的数据。如 Trie、概率计数等。
更底层: BLAS
可读性权衡: python 流行,很大功劳在于他的可读性能为团队带来较高的效率,包括团队沟通、代码维护等等。很多时候需要考虑,这份 代码的加速是否以牺牲团队效率为代价 。
计算机底层组件
计算单元
如 CPU/GPU,由每个周期能进行的操作数量以及每秒能完成多少个周期。第一个属性通过每周期完成的指令数(IPC) 来衡量,而第二个属性则是通过其时钟速度衡量。(目前受晶体管物理限制而停滞)
矢量计算是指一次提供多个数据给一个 CPU 并能同时被操作。这种类型的 CPU 指令被称为 SIMD(单指令多数据),联系一下矩阵计算。
阿姆达尔定律认为如果一个可以运行在多核上的程序有某些执行路径必须运行在单核上,那么这些路径就会成为瓶颈导致最终速度无法通过增加更 多核心来提高。
储存单元
储存单元包括了寄存器、RAM、硬盘。读写数据的速度与读写方式相关(顺序读取 VS 随机读取)
- 硬盘:关机也能长期储存、读写慢,随机访问性能下降但容量高。
- RAM:用于保存应用程序的代码和数据(比如用到的各种变量)
- L1/L2 缓存:极快的读写速度。进入 CPU 的数据必须经过这里。很小的容量(KB 级别)。
异步 I/O 和缓存预取等技术还提供了很多方法来确保数据在被需要时就已经存在于对应的地方而不需要浪费额外的计算时间
通信层
使用 GPU 的不利之处很多都来自它所连接的总线:因为 GPU 通常是一个外部设备,它通过 PCI 总线通信,速度远远慢于前端总线。
异质架构使得 GPU 能够被使用在需要传输大量数据的计算上
- 总线速度=总线贷款(一次传输数据量)+总线频率(每秒传输次数)
高的总线带宽有助于矢量化的代码(或任何顺序读取内存的代码),而另一方面,低带宽高频率有助于那些经常随机读取内存的代码。这些属性是由计算机设计者在主板的物理布局上决定的:当芯片之间相距较近时,它们之间的物理链路就较短,就可以允许更高的传输速度。而物理链路的数量则决定了总线的带宽
为什么 python 慢
Python 对象不再是内存中最优化的布局。因为 Python 是一种垃圾收集语言——内存会被自动分配并在需要时释放。这会导致内存碎片并影响向 CPU 缓存的传输。
Python 虚拟机抽象层使得矢量操作变得不是直接可用
Python 的动态类型让代码难以优化,并且 Python 并不是一门编译性的语言。(如 C)当编译静态代码时,编译器可以做很多的事情来改变对象的内存布局以及让 CPU 运行某些指令来优化它们。
对于 Python 来说,充分利用多核性能的阻碍主要在于 Python 的 全局解释器 锁 (GIL)。GIL 确保 Python 进程一次仅有一个核心可以被使用,无论当前有多少个核心。该问题可以通过 multiprocessing(多进程)、Cython、numexpr、分布式计算模型等避免。
为什么使用 python
python 易上手、且有大量稳定的库,如 numpy, sklearn, pytorch, pyspark 等。系统通常要在性能与可维护性上取舍,Cython 将 Python 代码注释成类似 C 语言的类型,被转化后的代码可以被一个 C 编译器编译。它在速度上的提升令人惊叹(相对较少的努力就能获得 C 语言的速度),但后续代码的维护成本也会上升。
Python 性能瓶颈分析
性能分析为程序优化提供了方向。能够节省我们的时间消耗。
小结
如何找到代码中速度和 RAM 的瓶颈?
- 对于整个代码,可以使用 python 自带的 time 模块计时,更好的办法是采用
/usr/bin/time -p python file.py来对整体运行速度进行判断;对于内部函数,可以使用cProfile查看函数开销,或使用line-profile逐行诊断;对于内存,可以使用memory_profiler
如何分析 CPU 和内存使用情况?
- 如 Ubuntu 系统中可以直接使用资源查看器
我应该分析到什么深度?
- 考虑使用 dis 来对字节码分析,直接了解到函数底层的运作。
如何分析一个长期运行的应用程序?
- 考虑 dowser 和 dozer(书中提到的,并没有细看)
在 CPython 台面下发生了什么?
- 教你阅读 Cpython 的源码 CPython 可以轻松导入 C 库并从 Python 中使用它们一样
如何在调整性能的同时确保功能的正确?
- 不要抛弃单元测试,可以加入函数来动态调整
@profile的效果;不要吝啬使用文本保存需要验证的中间值。
部分笔记
《python 高性能编程》一书中采用了 julia 集合的案例。以下提到的 julia.py 文件就是一个普通需要被测试性能的代码。(julia 集合很有趣,可以考虑复现以下书中成果)
函数性能分析
可以考虑用 python 自带的 time 和装饰器判断函数开销,但这种方式很简单,能得到的信息也很有限。
from functools import wraps
def timefn(fn):
@wraps(fn)
def measure_time(*args, **kwargs):
t1 = time.time()
result = fn(*args, **kwargs)
t2 = time.time()
print("@timefn:" + fn.__name__ + " took " + str(t2 - t1) + " seconds")
return result
return measure_time
代码整体运行速度
使用 timeit 来计算时间消耗。默认循环(n)10 次,重复(r)5 次。 timeit 暂时禁用了垃圾收集器
python -m timeit -n 5 -r 5 -s "import julia1"
"julia1.calc_pure_python(desired_width=1000,
max_iterations=300)"
也可以通过 UNIX 中的 /usr/bin/time:
/usr/bin/time -p python julia1_nopil.py
/usr/bin/time --verbose python julia1_nopil.py
注意:该方案考虑到 python 脚本的启动时间,更适合用来测量。
代码性能诊断工具
cProfile
python -m cProfile -s cumulative julia1_nopil.py
采用 -s cumulative 来对每个函数累计花费时间进行排序。输出信息中包括函数调用总次数、pre-call 时间、函数名等
可以使用 pstats 库进行分析,首先生成函数分析文件:python -m cProfile -o profile.stats julia1.py。而后通过 python 分析数据:
import pstats
p = pstats.Stats("profile.stats")
p.sort_stats("cumulative") # 累计时间排序
p.print_stats()
p.print_callers() # 查看最耗时函数
p.print_callees() # 显示函数相互调用情况
可以通过 runsnake 对 profile.state 进行可视化分析(但似乎只支持 Python2)
line-profile
line-profile 可以对函数进行逐行分析,包括每行调用次数、时间等。首先安装 pip install line_profiler ,用 @profile 装饰器标记需要分析的函数,不需要导入任何的依赖。最后通过终端运行:
kernprof -l -v julia1_lineprofiler.py
-l:选项通知 kernprof 注入@profile 装饰器到你的脚步的内建函数, -v:选项通知 kernprof 在脚本执行完毕的时候显示计时信息。
对每一行进行分析往往是不够的,如对于判断语句 if func1 and func2: ,我们可能希望对行内的每一部分进行分析以及优化。
memory_profiler
对内存进行分析,安装:pip install memory_profiler;执行:python -m memory_profiler julia.py,同 line-profile 一样的,需要使用@profile 标记被分析函数。
内存分析很慢(通常需要花上原代码 10 倍+的运行时间)通过 memory_profiler 可以观察到 Julia 集案例中,使用 range() 占用了非常大的 RAM,对于 python2 建议使用 xrange()。python3 中将 xrange() 取消并合并为 rrange()
dis Python 字节码反汇编器
用 dis 模块检查 CPython 字节码,dis 模块可用于了解函数内部发生了什么Python 中文官方文档https://docs.python.org/zh-cn/3/library/dis.html。以下 5 列输出结果分别表示:代码所在行数、指向其他代码的跳转点、操作名和地址、操作的参数、原始参数名。 最后一列为笔者个人备注。
import dis
import julia
dis.dis(julia.func1)
'''
部分输出:
26 0 LOAD_GLOBAL 0 (complex) # 搜索名词空间,找到 complex 函数并加载到栈
2 LOAD_GLOBAL 1 (c_real) #
4 LOAD_GLOBAL 2 (c_imag)
6 CALL_FUNCTION 2
8 STORE_FAST 3 (c)
27 10 LOAD_GLOBAL 3 (range)
12 LOAD_GLOBAL 4 (len)
>> 38 FOR_ITER 68 (to 108) # 跳转点(>>)匹配 JUMP_ABSOLUTE 以及
>> 108 JUMP_ABSOLUTE 22 # POP_JUMP_IF_FALSE 等指令
'''
比如对于以下两个函数分析:
def fn_expressive(upper = 1000000):
total = 0
for n in range(upper):
total += n
return total
def fn_terse(upper = 1000000):
return sum(range(upper))
dis.dis(fn_expressive)
dis.dis(fn_terse)
fn_expressive 的字节码是fn_terse 的两倍,字节码越多开销自然越大。sum() 由 C 编写,可以跳过循环中创建 python 对象的步骤。
进行单元测试
如上节中提到,可以使用 @profile 来标记需要测试性能的函数,但如果我们要运行文件时有需要把 @profile 去掉,否则会出现 NameError,很麻烦。可以考虑加入以下函数来动态调整 @profile。
if 'line_profiler' not in dir(): # python3
def profile(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
外在因素
检查电脑是否处于节电模式,是否插入电源等;关闭其他运行软件或进程;重启并重跑第二次实验。 进行单元测试时候,不要吝啬将输出储存到一个文本文件中,而后用diff进行对比;比如浮点数取整或舍入等问题。
列表和元组
小结
查询列表/元组的复杂度是什么?
- 均为 O(1),Python 内建排序使用了 Tim 排序,其运用了多种排序算法,根据给定数据进行选择,以达到最优化。
列表和元组的区别是什么?
- 主要为动态静态之分,由于部分元组不会频繁地被内存释放机制回收,而是预留下了空间供其他程序使用,因此初始话列表比初始化元组慢 5 倍!
向列表添加新项目是如何实现的?
- 列表使用了动态数组,分配公式为 ,即当元素个数大于 M 中的阀值时,列表将会自动申请一个更大的空间,而后将数据移动到新空间上。因此当列表越长时,其浪费的空间也就越大(列表中有太多位置是空的、待填充的)。列表的 append 开销是很大的,可以通过为列表预分配内存等来优化速度。
字典和集合
小结
字典和集合的共同点是什么?
- 字典与集合都采用散列表。散列函数对键的使用方式极大影响了数据结构的性能
字典的开销在哪里?
字典最基本的功能为键值查询:
# Cpthon 中字典查询的近似伪代码
def index_sequence(key, mask=0b111, PERTURB_SHIFT=5):
perturb = hash(key) #X
i = perturb & mask
yield i
while True:
i = ((i << 2) + i + perturb + 1) # 此处公式并不重要,仅表示一个线性转换
perturb >>= PERTURB_SHIFT
yield i & mask
以上为字典散列(HASH)函数的近似伪代码。可以看出大部分开销由解决碰撞产生。因此,让散列值均匀分布(熵最大化)可以提高性能。
自定义类默认的 __hash__ 和 __cmp__ 比较的是对象在内存中的位置,因此会出现类中以下情况:
class Point(object):
def __init__(self, x, y):
self.x, self.y = x, y
p1 = Point(1,1)
p2 = Point(1,1)
Point(1,1) in set([p1, p2]) # False
解决方案是重写 __hash__ 与 __eq__
class Point(object):
def __init__(self, x, y):
self.x, self.y = x, y
def __hash__(self):
return hash((self.x, self.y))
def __eq__(self, other):
return self.x == other.x and self.y == other.y
字典与集合默认大小为 8,每次改变大小时,桶的个数增加到原来的 4 倍,直至达到 50000 个元素,之后每次增加到原来的 2 倍。
我如何优化字典的性能?
- 提前知道字典大小或者散列值范围,可以通过修改散列函数
def __hash__(self)来优化性能。
为了找到大小为 N 的字典的掩码,我们首先找到能令该字典保持三分之二满的最低桶数( N * 5 / 3 ),然后找到能满足这个数字的最小字典大小(8; 32; 128; 512; 2048; 等等)并找到足以保存这一数字的 bit 的位数。比如,如果 N=1039 ,那么我们至少需要 1731 个桶,这意味着我们的字典有 2048 个桶。那么掩码就是 bin(2048 - 1) = 0b11111111111 。
# 最优双字母散列函数(如果键值仅由双字幕组成)
def twoletter_hash(key):
offset = ord('a')
k1, k2 = key
return (ord(k2) - offset) + 26 * (ord(k1) - offset)
Python 如何使用字典记录命名空间?
Python 查找 locals() 数组,其内保存了所有本地变量的条目。Python 花了很多精力优化本地变量查询的速度,而这也是整条链上唯一一个不需要字典查询的部分。如果它不在本地变量里,那么会搜索 globals() 字典。最后,如果对象也不在那里,则搜索__builtin__ 对象。要注意 locals() 和 globals() 是显式的字典而__builtin__则是模块对象,在搜索__builtin__中的一个属性时,我们其实是在搜索它的 locals()字典(对所有的模块对象和类对象都是如此!)。
通过以下操作,我们便知道如何通过修改引用变量的方式,来提高效率:
import math
from math import sin
def test1(x):
"""
>>> %timeit test1(123456)
1000000 loops, best of 3: 381 ns per loop
"""
return math.sin(x)
def test2(x):
"""
>>> %timeit test2(123456)
1000000 loops, best of 3: 311 ns per loop
"""
return sin(x)
def test3(x, sin=math.sin):
"""
>>> %timeit test3(123456)
1000000 loops, best of 3: 306 ns per loop
"""
return sin(x)
对于以上函数,可以用 dis 查看字节码,发现 test1 比另外两者多了一步 LOAD_GLOBAL (math) 即对 math 模块的引入。此外 test3 中使用本地变量保存了 sin 函数,因此无需进行额外的字典查询,这样的字典查询被大量调用时会降低性能,一个有趣的例子便是:
def test3(iterations=1000000):
result = 0
local_sin = sin
for i in range(iterations):
result += local_sin(i)
# 直接使用 result += sin(i) 会慢 8%
迭代器和生成器
小结
生成器是怎样节约内存的?
生成器的一个特点是使用 yield 返回值,当函数结束时,一个 StopIteration 异常会被跑出来终止函数。
使用生成器的最佳时机是什么?
对大数据进行分析,内存不足以一次分析全部信息的时候。
我如何使用 itertools 来创建复杂的生成器工作流?
itertools 中常用的函数:
islice(fun(),beg,end)对一个无穷生成器进行切片chain()将多个生成器链接在一起takewhile()给生成器添加终止条件cycle()不断重复有穷生产器,使其变为无穷
更多查看官方文档。
延迟估值何时有益,何时无益?
延迟估值:仅当生成器被调用时才回去读取下一组数据,如果出现了一个提前终止的条件,那么就可以 大幅降低整体的运行时间。
对于生成器,很多时候都智能访问当前的值,而无法访问数列中其他的元素,导致原生成器难用。
矩阵和矢量计算
该节突出了代码优化的两个核心思想:矢量计算和减少内存分配。
矢量操作(比如两个数组相乘)和非矢量操作使用的是不同的 CPU 计算单元和指令集。为了让 Python 能够使用这些特殊指令,我们必须有一个模块专门用来使用这些指令集,如 numpy。
案例
本节以热传导为例子。u 表示扩散质量的矢量
根据以上公式,我们可以给出一阶扩散方程的伪代码:
# Create the initial conditions
u = vector of length N
for i in range(N):
u = 0 if there is water, 1 if there is dye
# Evolve the initial conditions
D = 1
t = 0
dt = 0.0001
while True:
print "Current time is: %f" % t
unew = vector of size N
# Update step for every cell
for i in range(N):
unew[i] = u[i] + D * dt * (u[(i+1)%N] + u[(i-1)%N] - 2 * u[i])
# Move the updated solution into u
u = unew
visualize(u)
对于二阶扩散方程,有:
# 计算 2 阶差分算法
for i in range(N):
for j in range(M):
unew[i][j] = u[i][j] + dt * (
\
(u[(i+1)%N][j] + u[(i-1)%N][j] - 2 * u[i][j]) + \ # d^2 u / dx^2
(u[i][(j+1)%M] + u[j][(j-1)%M] - 2 * u[i][j]) \ # d^2 u / dy^2
)
扩散方程也被称为热方程。此时, u 表示一个区域的温度而 D 描述了材料的热传导能力。解开方程可以告诉我们热如何传导。这样,我们就能够了解 CPU 产生的热量如何扩散到散热片上而不是水中染料的扩散。
更多关于扩散方程请百度。
这边的案例中对上述热扩散计算进行了多次优化,包括
- 矢量运算代替 python 原生 for 循环。 原生 Python 并不支持矢量操作。这有两个原因: Python 列表存储的是指向实际数据的指针,且 Python 字节码并没有针对矢量操作进行优化,所以 for 循环无法预测何时使用矢量操作能带来好处。
- 减少计算二阶差分时候额外分配的内存 ,如额外的中间变量赋值等。
- 通过
numexpr优化 numpy 运算。 numexpr 引入的大多数额外的机制都跟缓存相关。当我们的矩阵较小且计算所需的所有数据都能被放入缓存时,这些额外的机制只是白白增加了更多的指令而不能对性能有所帮助。另外,将字符串编译成矢量操作也会有很大的开销。当程序运行的整体时间较少时,这个开销就会变得相当引人注意。
from numexpr import evaluate
def evolve(grid, dt, next_grid, D=1.0):
laplacian(grid, next_grid)
evaluate("next_grid*D*dt+grid", out=next_grid)
def evolve2(grid, dt, next_grid, D=1.0):
laplacian(grid, next_grid)
next_grid *= D * dt
next_grid += grid
以上例子为 numexpr优化,当 grid 维度越大, evolve 的优化效果越明显,相反的维度的时候,可能会有性能损失。而这一阀值由电脑的缓存决定,如 20480KB 的缓存,其阀值约为 20480KB/64bit=2560K 个数,大概用 2 个 1131 的矩阵就能填满
小结
cache-miss 和 page-faults 是什么?
这个在正确的时候将正确的数据传输给 CPU 的问题被称为“冯诺伊曼瓶颈”。
缓存失效 cache-miss: 为了支持 CPU 运算,我们必须从 RAM 中预取数据并将其保存在一个更小但更快的 CPU 缓存中,并希望当 CPU 需要某个数据时,它可以从中更快读取到。如果我们的缓存中还没有数据并需要从 RAM 获取,缓存失效 cache-miss 便发生了。
page-fault 页面丢失: 是现代 UNIX 内存分配机制的一部分。分配内存时,内核除了告诉程序一个内存的引用地址以外没做任何事。但是,之后在这块内存第一次被使用时,操作系统会抛出一个缺页小中断,这将暂停程序的运行并正确分配内存。这被称为延迟分配系统。虽然这种手段相比以前的内存分配系统是一个很大的优化,缺页小中断本身依然是一个相当昂贵的操作,因为大多数操作都发生在你的程序外部。另外还有一种缺页大中断,发生于当你的程序需要从设备(磁盘、网络等)上请求还未被读取的数据时。这些操作更加昂贵,因为他们不仅中断了你的程序,还需要读取数据所在的设备。这种缺页不总是影响 CPU 密集的工作,但是,它会给任何需要读写磁盘或网络的程序带来痛苦
矢量计算的瓶颈在哪里?
- 数据传输速度 是瓶颈。减少瓶颈最好的方法是让代码知道如何分配我们的内存以及如何使用我们的数据进行计算。矢量计算(或者说让 CPU 在同一时间进行多个计算)仅能发生在我们能够将相关数据填满 CPU 缓存的情况下。
我可以用什么工具查看 CPU 进行计算时的效率?
使用 Linux 的 pref:
perf stat -e cycles,stalled-cycles-frontend,stalled-cycles-backend,instructions,\
cache-references,cache-misses,branches,branch-misses,task-clock,faults,\
minor-faults,cs,migrations -r 3 python diffusion_python_memory.py
详细查看《python 高性能变成 6.3.1》如果你想要一个在 CPU 层面各种性能指标更彻底的解释,请参考 Gurpur M. Prabhu 的“计算机架构导论”
其中的 page-fault, cache-miss 等指标都能很好的说明我们要优化的方向
numpy 为什么比纯 Python 更适合数值计算?
- 在后台有极其优化的 C 代码来专门使用 CPU 的 矢量操作 。
- numpy 数组在内存中是 连续储存 的底层数字类型
- numpy 也降低了 缓存失效 的频率。减少了 内存分配 频率。
我如何追踪代码中的内存分配?
- python 中可以通过 id 查询,减小内存分配可以有效的优化代码速度
编译成 C
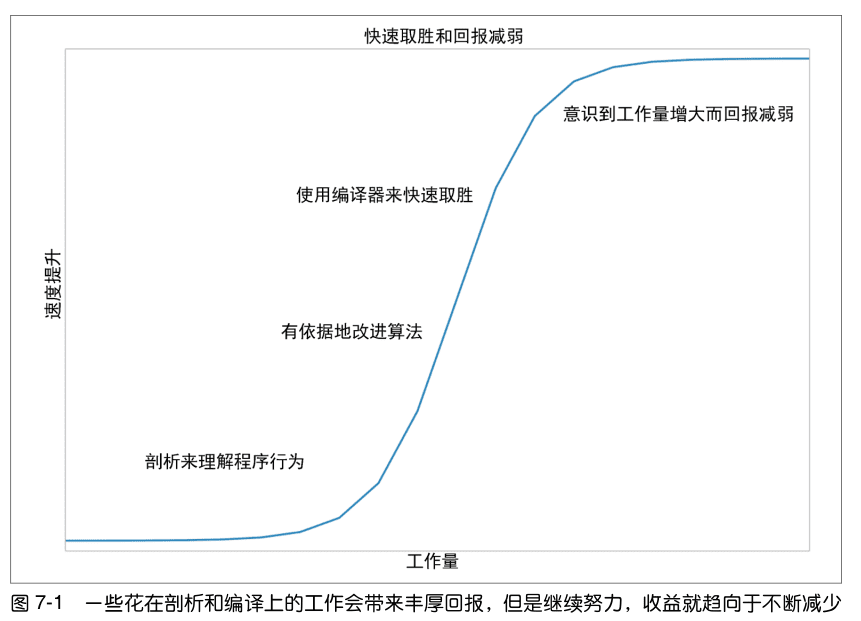
编译后的代码不可能比精心编写的 C 程序快,但也不可能慢太多。切忌投入 过多 精力在这方面上。
我怎样让我的 Python 代码作为低级代码来运行?
- 本节主要以 Cython 为例总结
JIT 编译器和 AOT 编译器的区别是什么?
- JIT(即使编译)存在冷启动问题,但不需要人工干涉;AOT(提前编译)需要人工的改动更多的代码,但是效率兼容性等更高。
编译后的 Python 代码运行什么任务能够比本地 Python 快?
- 确定变量类型,少让代码保持泛型。python 对象告状了额外的函数,如
__hash__,__str__等,对于 CPU 密集型 的代码区域,不改变变量类型情况下可以做静态编译加快代码。
为什么类型注解提升了编译后 Python 代码的运行速度?
函数几乎每一行都回调了 Python 虚拟机。因此数值运算也都 回调了 Python 虚拟机,因为我们使用的是高层的 Python 对象。如果没有类型注解,再回调 python 时候,所有的数值对象都需要再转化为 python 对象。
Cython 中进行类型注解,数值不需要回调 python 栈,但是也损失了灵活性。
我该怎样使用 C 或 Fortran 为 Python 编写模块?
- Cython 使用了 gcc, shed skin 使用了 g++。
- 以之前的 julia 集合为例子,编译模块需要的文件大致为:
julia.pycythonfn.pyxsetup.py - setup.py 脚本调用 Cython 把.pyx 文件编译成一个编译模块。在类 UNIX 系统上,编译模块可能会是一个.so 文件;在 Windows 上应该是一个.pyd(类 DLL 的 Python 库)。
我该怎样在 Python 中使用 C 或者 Fortran 的库?
- 采用外部函数接口模块,如 Ctypes 等,具体参考书中第 7 章。
Cython
Cython 文档 pip install Cython
》Cython 使用了 gcc, shed skin 使用了 g++。
快速上手
以之前的 julia 集合为例子,编译模块需要的文件大致为:julia.py calculate.pyx setup.py
calculate.pyx 中定义需要编译的函数,一般为 CPU 密集型。
def calculate_z(maxiter, x, y):
# ...
for j in range(len(y)):
for i in range(len(x)):
z = complex(x[i],y[j])
n = 0
while abs(z) < 2 and n < maxiter:
z = z * z + c
n += 1
pix[i,j] = (n<<19) + (n<<11) + n
# ...
而后 setup.py 中配置需要编译的文件,并通过 python setup.py build_ext --inplace 来生成 .so/.pxd 文件。setup.py 脚本调用 Cython 把.pyx 文件编译成一个编译模块。在类 UNIX 系统上,编译模块可能会是一个.so 文件;在 Windows 上应该是一个.pyd(类 DLL 的 Python 库)。
from setuptools import setup
from Cython.Build import cythonize
from Cython.Distutils import build_ext
from distutils.extension import Extension
setup(
name='julia cal app',
cmdclass = {'build_ext': build_ext},
ext_modules = [Extension("calculate", ["calculate.pyx"])],
# 也可以直接使用:
# ext_modules=cythonize("calculate.pyx"),
zip_safe=False,
)
最后在你的文件 julia.py 中就可以导入 import calculate 并使用其中的函数了。 这样花费很少的工作量就可以提升越 10%以上的速度性能。
优化思路分析
通过 cython -a calculate.pyx 来生成 一个 calculate.html 文件,越黄的部分代表越多 python 虚拟机调用,白色为更多的 C 代码执行,因此目的就是尽量转黄为白。
当然我们也可以使用 line_profile

一般最消耗 CPU 时间的代码都在紧凑的循环内、复杂的数学运算或解引用 list、array 等这些项。
进一步的优化
以上的优化并没有对代码进行较大的改动, calculate_z 函数还是使用 python 来编写的。为了进一步提高 Cython 的运行效率,可以考虑类型注释等方案。
类型注解等
优化方案总结:变量类型优化、更换 python 函数为 Cython 函数、取消 Cython 保护性检查、采用并行计算
除此外,也可以考虑前几章讨论的优化方向,如减少字节码数量,减少内存分配次数
- 首先考虑为数添加类型,如整数、复数等:
声明变量使用 cdef int i,cdef double complex j等;类型包括了常见的 C 语言变量类型。 变量类型转换:b = <double> a
- 而后考虑对使用的 python 函数进行替换,如
abs(),complex()等替换为 Cython 版本。 - 而后考虑对列表等进行优化,首先是关闭边界检查
Cython 中默认会保护程序员免于超出边界,因此可以在文件头添加以下代码进行配置,True为开启:
#cython: boundscheck=False
或者使用装饰器:
cimport cython
@cython.boundscheck(False)
def myfun():
除了边界检查外,还有其他的一些可以关闭以提高速度:
boundscheck # 数组下标越界
wraparound # 负索引
cdivision # 除 0 检查
initializedcheck # 内存视图是否初始化
而后对列表类型进行定义,如:
def func(double[:]x):
cdef int[:] y = ....;
cdef int[:,:] z # 二维数组
其中,若使用 cimport numpy as np 需要在 setup.py 中添加 include_dirs=[np.get_include()]
- 采用并行计算
.pyx 中:
from cython.parallel import parallel, prange
with nogil:
for m in prange(leny,schedule="guided"):
setup.py 中引入 openmp:
ext_modules=[Extension("calculate",["calculate.pyx"],
extra_compile_args=['-fopenmp'],
extra_link_args=['-fopenmp'])
- 效果记录:Cython 编译纯 python(1.34s),类型转变(0.51s),替换 python 基础函数如
abs()等(0.32s), 关闭各种检查(0.31s),对传入的 array 参数进行类型定义(0.18s)。
# 结构体定义
cdef union Food:
char *spam
float eggs
cdef int a_global_variable
def int func(int a, int[:] b):
cdef int i = 10, j, k
cdef float f = 2.5
# cdef float g[4] = [1,2,3,4] # currently not supported
cdef float *g = [1, 2, 3, 4]
cdef float *h = &f
return a
numpy 代替 list :list 中的对象分布再内存的各个位置,而 numpy.array 中的对象储存再连续的内存中。
其他工具
除了 Cython 外,还有 Shed Skin,pypy 等。PyPy 是普适的 CPython 代替工具,提供了几乎所有的内置模块,并且他的效率也挺高(几乎与上一些中经过所有优化环节后的 Cython 速度相当),但是 PyPy 与 C 拓展代码的兼容性不是很好。并且占用内存较大
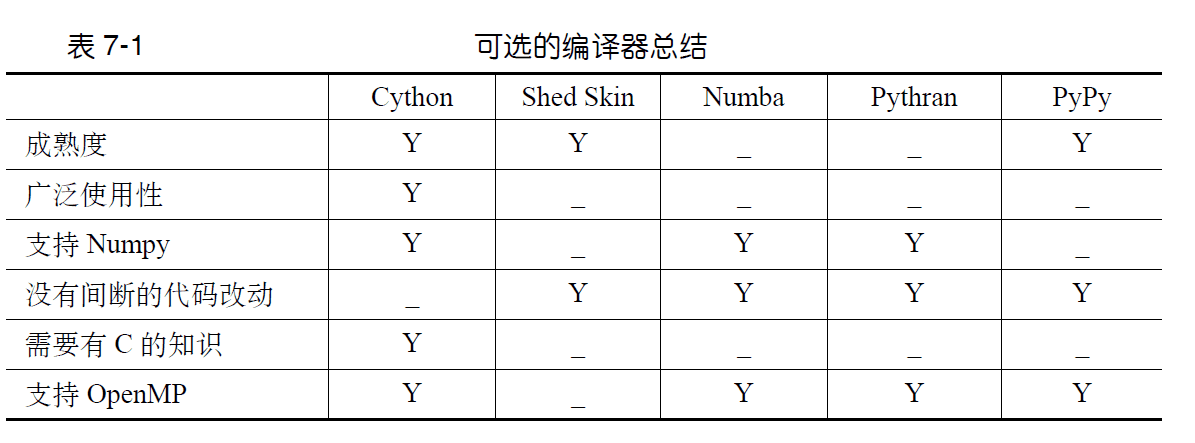
上图中对比了几种比较古老的编译器,可以看出 Cython 是一个较为好的选择。
外部函数接口
有时候自动化解决方案不起作用,这时候就需要自己写函数接口。比如用 C 写好接口,然后编译成 .so 的文件共享模块。
CPython 中最基础的外部函数接口是 Ctypes,此外还有 cffi,f2py
并发
前一节我们介绍了如何优化 CPU 密集型程序。这节讨论了如何优化 I/O 密集型程序。
小结
什么是并发,它如何起帮助作用?
CPU 并不是不间断的在计算,进程中需要有 IO 读取等其他操作,因此 CPU 暂停计算进入等待(I/O 等待)的时间可以用来计算其他的任务。
并发和并行的区别是什么?
并发单 CPU,并行多 CPU。
什么任务能够用并发来做,什么不能做?什么时候是利用并发的合适时机?
比如爬虫等需要有 IO 等待的任务,可以对获取数据(如 request)函数采用并发。常见的并发库有 gevent,grequest,tornado, AsyncIO
并发的各种模式是什么?
事件循环编程可以分为两种:回调型和 future 型。
以 下载数据-处理数据-打印处理成功 为例:
回调型中的异步函数没有返回值,一般处理数据函数内调用打印处理函数
def save_value(value, callback):
print("Saving {} to database".format(value))
save_result_to_db(result, callback) # 异步函数
def callback(db_response):
print("Response from database: {}".format(db_response))
future 型中,异步函数通常有返回值;其中让步函数 yield 会暂定 save_value,直到值准备好了再继续。
@coroutine
def save_value(value, callback):
print "Saving {} to database".format(value)
db_response = yield save_result_to_db(result)
print "Response from database: {}".format(db_response)
multiprocessing
Amdahl 定律
其中,a 为并行计算部分所占比例,n 为并行处理结点个数。这样,当 1-a=0 时,(即没有串行,只有并行)最大加速比 s=n;当 a=0 时(即只有串行,没有并行),最小加速比 s=1;当 n→∞时,极限加速比 s→ 1/(1-a),这也就是加速比的上限。例如,若串行代码占整个代码的 25%,则并行处理的总体性能不可能超过 4。这一公式已被学术界所接受,并被称做“阿姆达尔定律”,也称为“安达尔定理”(Amdahl law)。--引用百度百科
案例
预测 pi
采用蒙特卡洛来预测 pi。我们模拟投掷 n 次飞镖,以一个正方形为靶子。则 pi 可以通过落在正方形内切圆中的飞镖数量和总飞镖数量推算出来。
python 串行
def estimate_nbr_points_in_quarter_circle(nbr_estimates):
nbr_trials_in_quarter_unit_circle = 0
for step in xrange(int(nbr_estimates)):
x = random.uniform(0, 1)
y = random.uniform(0, 1)
is_in_unit_circle = x * x + y * y <= 1.0
nbr_trials_in_quarter_unit_circle += is_in_unit_circle
return nbr_trials_in_quarter_unit_circle
multiprocessing 多进程
from multiprocessing.dummy import Pool
def estimate_pi_multiprocessing(nbr_estimates):
nbr_parallel_blocks = 4
pool = Pool(processes=nbr_parallel_blocks)
nbr_samples_per_worker = nbr_estimates / nbr_parallel_blocks
nbr_trials_per_process = [nbr_samples_per_worker] * nbr_parallel_blocks
nbr_in_unit_circles = pool.map(estimate_nbr_points_in_quarter_circle, nbr_trials_per_process)
pi_estimate = sum(nbr_in_unit_circles)
return pi_estimate
多线程(一个进程)测试只需要将上面多进程案例的导入函数更改为:
from multiprocessing.dummy import Pool
效率对比: 以上三个版本代码运行速度对比:
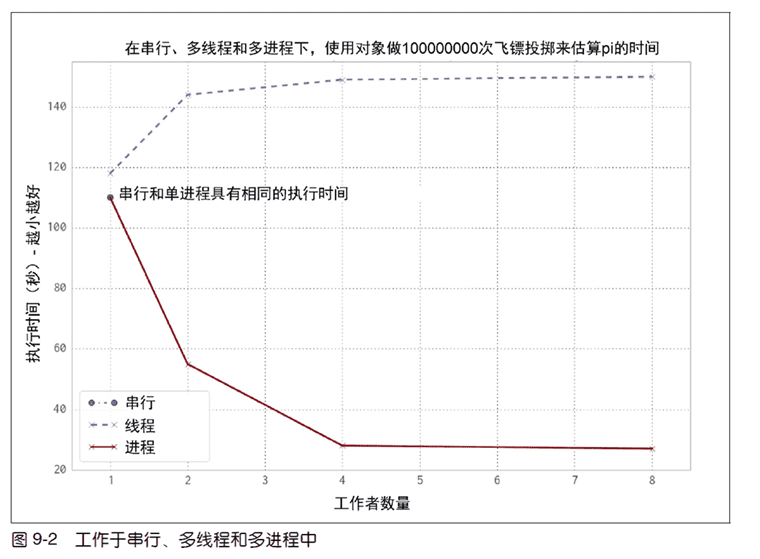
可以注意到多线程的运行效率更差了,因为由“GIL 竞争”所导致的开销实际上让我们的代码运行得更慢了。注意“GIL 竞争”近存在于多核程系统。 如果没有 GIL 的限制的话,多线程是可以提高速度的,因为所有的 CPU 都会参与到线程的计算当中。
现实中,还有很多其他的线程、进程模块以及调用方法。
检查素数
最朴素的串行方案:
def check_prime(n):
if n % 2 == 0:
return False
from_i = 3
to_i = math.sqrt(n) + 1
for i in xrange(from_i, int(to_i), 2):
if n % i == 0:
return False
return True
我们可以将检查范围分区,而后通过多进程对每个区域进行检查:
def check_prime(n, pool, nbr_processes):
from_i = 3
to_i = int(math.sqrt(n)) + 1
ranges_to_check = create_range(from_i, to_i, nbr_processes) # 对检查范围分区
ranges_to_check = zip(len(ranges_to_check) * [n], ranges_to_check)
results = pool.map(check_prime_in_range, ranges_to_check)
if False in results:
return False
return True
但当 n 较小的时候,进程之间的通信消耗将令整个程序运算效率降低,因此可以对以上版本进行改进,根据 n 的大小采取不同的算法。(就和 python 中的排序算法一样)
def check_prime(n, pool, nbr_processes):
# cheaply check high-probability set of possible factors
from_i = 3
to_i = 21
if not check_prime_in_range((n, (from_i, to_i))):
return False
可以添加不同进程间的通讯信号,当一个进程发现非质数时,通知其他进程终止计算。书中使用了 multiprocessing.Manager 的 Value 对象进行进程间共享参数。要注意的是: 通讯的频率设计是值得考虑的。 或者采用 multiprocessing.RawValue
采用 Redis 来进行数据共享,任何与 Redis 有接口的语言或工具都能以一种可兼容的方式来共享数据。可以轻易地不同编程语言之间平等地共享数据。
书中认为,最快的共享方式是使用 mmap 内存映射(共享内存)。
小结
multiprocessing 模块提供了什么? python multiprocessing 库链接
multiprocessing 封装了进程、池、队列、管理者、ctypes、同步原语等模块。支持单机多核并行计算(多机多核计算我们有更好的选择),提供队列来共享工作,再并行任务之间共享状态,如数据、字典、字节等。
进程和线程的区别是什么?
进程是资源分配的最小单位,线程是 CPU 调度的最小单位。参考知乎回答 可以将进程-线程关系比喻成火车与车厢。
ps -ef|grep python 查看以下案例中的代码运行情况,多线程下会有多个 PPID 以及对应的 PID。而单进程多线程的话,只能查看到一个进程 PID。
我该如何选择合适大小的进程池?
一个额外的进程会占用额外的内存,因此需要根据代码的实际情况判断。大多数情况下,进程池的数量不会大于 CPU 的核心数。当进程池数量大于 CPU 核数时,效率的提升将会减少。
我该如何使用非持久队列来处理工作?
multiprocessing.Queue,考虑采用in,out两个队列进行进程间通信。在每个进程中,我们从 in 队列中获取任务,处理完成后导入到 out 队列中。
manager = multiprocessing.Manager() # 多线程采用 multiprocess.manager 中的 Queue
queue_in = manager.Queue()
queue_out = manager.Queue()
def subprocess(queue_in, queue_out):
args = queue_in.get()
result = task(args)
queue_out.put(args)
进程间通信的代价和好处是什么?
进程间通讯是需要开销的,但进程间通讯能够实现更复杂的,更大的任务。如书中验证多个素数案例,进程数量越大,进程间通讯代价越高,导致多进程不如单进程来得快。
我该如何用多 CPU 来处理 numpy 数据?
多进程可以提高效率,矢量化也可以提高效率。那么这个讨论的就是多进程+矢量化。
备注:多进程中的随机数要避免相同随机数种子。就该节中的 pi 估值案例而言,采用 numpy 的代码如下:
def estimate_nbr_points_in_quarter_circle(nbr_samples):
# set random seed for numpy in each new process
# else the fork will mean they all share the same state
np.random.seed()
xs = np.random.uniform(0, 1, nbr_samples)
ys = np.random.uniform(0, 1, nbr_samples)
estimate_inside_quarter_unit_circle = (xs * xs + ys * ys) <= 1
nbr_trials_in_quarter_unit_circle = np.sum(estimate_inside_quarter_unit_circle)
return nbr_trials_in_quarter_unit_circle
若使用多进程的话,操作方式与本文中的 pi 估计案例类似。由于使用并行运算,因此很难使用之前提到的 line_profiler 一类工具。若要检验效率的话,可以尝试人工地注释掉每一行,然后分别计算时间。
可以在进程之间共享矩阵来节省 RAM 的占用,比如使用 multiprocessing.Array , multiprocessing.RawArray等。
为什么我需要加锁来避免数据丢失
如 4 个进程以一定次数递增一个共享的计数器时。缺少同步的话,计数就是错误的。
对于文件的读写同步,可以采用 lockfile 模块;对于值,可以考虑 multiprocessing.Value 及其 lock()
multiprocessing 解决棘手问题的贴士
- 把你的工作拆分成独立的工作单元。
- 如果工作者所花的时间是可变的(如检查素数任务),那就考虑随机化工作序列(另一个例子 就是处理大小可变的文件)。
- 对你的工作队列进行排序,这样首先处理最慢的任务可能是一个平均来说有用的策略。
- 使用默认的 chunksize,除非你已经验证了调节它的理由。
- 让任务数量与物理 CPU 数量保持一致(默认的 chunksize 再次为你考虑到了,尽管它默认会使用超线程,这样可能不会提供额外的性能收益)。
multiprocessing 的一些基础
- Process 类 - 及用于操作进程的类。doc multiprocessing 支持 spawn,fork,forkserver 三种不同的进程启动方式。可以通过
mp.set_start_method('spawn')来更改。
from multiprocessing import Process
p = Process(target=print, args=('bob',)) # 定义一个进程
p.is_alive() # 查看进程状态
p.start() # 启动一个进程
p.join() # join(t) 阻塞 t 秒,t 默认为 None,即阻塞知道该进程终止
- Queue -
Queue类是一个近似queue.Queue的克隆。在 multiprocessing 中可用来做进程通信。multiprocessing 中的 queue 不能用于 pool 进程池。线程池中通信可以使用 Manager 中的 queue
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello']) #
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get(timeout=1)) # 提取头元素,等待 1 秒。timeout 默认为 None(一直等待)
p.join()
- Pool - 进程池可以对一系列进程进行操作。常用的方法包括如下:
from multiprocessing import Pool
import time
def f(x):
return x*x
if __name__ == '__main__':
with Pool(processes=4) as pool: # start 4 worker processes
result = pool.apply_async(f, (10,)) # evaluate "f(10)" asynchronously in a single process
print(result.get(timeout=1)) # 尝试获取结果
print(pool.map(f, range(10))) # 返回可迭代对象,将 range10 分块添加到进程中
it = pool.imap(f, range(10)) # 对于很长的可迭代对象,考虑使用 imap
print(next(it)) # prints "0"
print(it.next(timeout=1)) # prints "1" ,除非 timeout
result = pool.apply_async(time.sleep, (10,))
print(result.get(timeout=1)) # raises multiprocessing.TimeoutError
- Manager - 管理器提供了一种创建共享数据的方法,从而可以在不同进程中共享,甚至可以通过网络跨机器共享数据。
FLAG_CLEAR = b'0'
FLAG_SET = b'1' # 此处使用 1-byte char 作为进程通信的信号
manager = multiprocessing.Manager()
value = manager.Value(b'c', FLAG_CLEAR) # 1-byte character 生成一个可储存值的 value 对象
value.value = FLAG_CLEAR
# ...
lock = multiprocessing.Lock() # 变量锁可以确保数据同步正确
with lock:
value2.value += 1
其他
Array 的共享:4 个进程分别采用 random 来生成随机数的效率,不如生成完一个大随机块后再共享开得快。
with multiprocessing.Pool(processes=nbr_parallel_blocks) as pool:
ranges_to_check = create_range(0, len(eval_examples), nbr_parallel_blocks) # 对检查范围分区
tydi_pred_dict_list = [
pool.apply_async(construct_prediction_object_in_range,
(eval_examples, beg, end, candidate_beam, max_answer_length)
).get()
for beg, end in ranges_to_check
]
使用 pool 进行多线程时候,运行的函数不可以是 local 函数。尽管如此,但我们可以用 partial 来传递内部参数。
此外,multiprocessing 中的字典或者 list 对象无法直接通过引用更改,需要整个对象重新赋值。
# create a list proxy and append a mutable object (a dictionary)
lproxy = manager.list()
lproxy.append({})
# now mutate the dictionary
d = lproxy[0]
d['a'] = 1
d['b'] = 2
# at this point, the changes to d are not yet synced, but by
# reassigning the dictionary, the proxy is notified of the change
lproxy[0] = d
内存占用问题:
multiprocessing 的 fork 方式下,子进程会复制一份父进程的资源。尝试使用 forkserver 或者 spawn。
对于需要多进程处理超大队列,可以考虑采用 imap或 imap_unordered 代替 map。使用 chunksize 参数的作用和 map() 方法的一样。对于很长的迭代器,给 chunksize 设置一个很大的值会比默认值 1 极大 地加快执行速度。
集群和工作队列
集群的关键点落在了维护集群上,书中重点强调需要考虑到操作集群时可能发生的任何情况,并且定期地检查集群的健康状况。
而后书中介绍了三个集群化解决方案:Parallel Python、IPython Parallel 和 NSQ。
其他集群化工具:Celery,Gearman,PyRes,SQS
小结
为什么集群是有用的?
- 集群的特点在于能够轻松的扩展服务器规模,只要激活服务器的速度够快,就能够很好的应对业务高峰期。并且集群能够提升系统整体的容错性(部分集群点宕机不会影响整体服务)
集群的代价是什么?
- 你所面临的问题包括:机器间版本、信息统一问题;每台机器维护;数据转移;集群管理成本高;集群部分机器宕机后可能面临的问题;
惨痛的案例:在 2012 年,高频交易公司骑士资本在集群中做软件升级期间引入了一个错误,损失了 4.62 亿美元。软件做出了超出客户所请求的股票买卖。在交易软件中,一个更老的标记转用于新函数。升级已进行到了 8 台活跃机器中的 7 台,但是第 8 台机器使用了更旧的代码来处理标记,这导致了所做出的错误的交易。
我该如何把一个多进程的解决方案转换成一个集群解决方案?
采用 Parallel Python,通过multiprocessing 转化集群方案。
IPython 集群如何工作?
NSQ 是怎样有助于创建鲁棒的生产系统?
NSQ 提供了关于消息递送的基本保证,并且它使用了两个简单的设计模式来做好了一切:队列和发布者/订阅者模式。
- 队列: 起到缓冲的作用;一、如果处理任务的机器下线,那么客户任务会被缓存在队列中;二、在业务高峰期,不能被及时处理的任务能够得到存放。NSQ 的队列能够存储与内存或硬盘,这取决于队列中的任务数量。
- 发布者/订阅者: 有点类似于 MQTT 的发布者/消费者。NSQ 提出数据消费者,(多个进程能够连接到相同的数据进行发布)当新数据发布时,订阅者能够得到一份拷贝。
一般来说,当使用队列系统来工作时,设法让下流的系统处于正常工作负载 60%的容量是一个好主意。
使用更少的 RAM
小结
为什么我应该使用更少的 RAM?
了解为什么 RAM 被吃光了而且考虑更有效的方式来使用这个稀缺资源将有助于你处理扩展性的问题。
抽象的来说,内存中数据越多,移动起来越慢
为什么 numpy 和 array 对存储大量数字而言更有利?
- 用连续的 RAM 块来保存底层数据。
- numpy 或 array 中的数字对象并不是 python 对象,而是字节。
怎样把许多文本高效地存储进 RAM?
要在一个静态结构中存储大量的 Uncode 对象,可以采用 Trie 树和有向无环图单词图(DAWGs)import dawg 来压缩文本内容。
可以考虑概率数据结构,如 HyperLogLog++ 算法。该方法牺牲了准确率来换取 RAM。
我该如何能仅仅使用一个字节来(近似地)计数到 1e77?
class MorrisCounter(object):
counter = 0
def add(self, *args):
if random() < 1.0 / (2 ** self.counter):
self.counter += 1
def __len__(self):
return 2**self.counter
如上计数器,再计数的时候,当 counter越大,counter += 1 的概率就越小。因此,从概率的角度出发,通过counter大小能够大致知道具体计数的次数。概率计数能够用一个无符号字节,math.pow(2, 255) 可以计数到 5e76。
除此外可以使用散列函数来进行非 重复元素个数的计数 。如 KMinValues 算法:如果我们保存了我们所见到的 k 个最小的唯一散列值,我们就能近似估算散列值的总体空间,并且推导出这些项的全部数量。
KMinValues 算法 - Beyer,K.,Haas, P.J., Reinwald, B., Sismanis, Y.,和 Gemulla, R“. 在多集和操作下,有关对独立值估算的概要”。2007 年 ACM SIGMOD 数据管理国际会议进展——SIGMOD ’07, (2007): 199 210. doi:10.1145/1247480.1247504。
什么是布隆过滤?为什么我可能会需要它们?
布隆过滤主要思想:对数据进行多次散列,得到散列列表,从而降低散列冲撞的概率。
布隆过滤 - Bloom,B.H. “以允许的误差使用 hash 编码做空间/时间的权衡。”ACM 通信。13:7(1970):422-426doi:10.1145/362686.362692
现场教训
书中的这一部分值得任何技术出身的创业者反复斟酌!
该部分包括自适应实验室(Adaptive Lab)案例、专注于机器学习的咨询业务的技术框架等
几个关键想法:
Redis 消息服务中心。其中的 Celery 任务队列(面对需求变动大)可以快速分发大量的数据流给任意数量的服务器来做独立处理和索引
Elasticsearch 做索引产品、实时文档存储
Cassendra 数据库
Graphite 被用来做报告、和 collectd、statsd 一起可以画出运行状况的漂亮图表。这带来一种观察趋 势的方法,并反溯分析问题来找到根本原因
Sentry 一个针对事件日志的大系统,并且跟踪了集群中的机器所产生的异常被用来记录和诊断 Python 的栈跟踪信息;
Jekins 被用来和内存数据库配置做连续集成。
SaltStack 被用来定义和配给复杂的集群,并处理所有的库、语言、数据库和文档存储的设置
flask web 框架,比 Django 更容易追踪代码,更灵活(但不意味着 flask 更好)。
ngix 反向代理
一个例子
来看看一家帮助客户为数据处理设计(文本数据)和构建系统的公司的建议。(就是 gensim 的创作团队!他们用 python 实现了比 c 更快的 word2vec!)该企业面对不同的客户,需要考虑不同的技术栈来插入客户已经存在的数据流和管道中。来看看他们给的建议:
创业建议:
- 沟通: 和客户沟通分为几个步骤:
- 业务开端: 在更高的层面(业务)上理解客户的问题。包括他们所需要的东西、他们在联系你之前对问题解决方案的理解(什么方法是可以做的、方法的效果等)
- 业务结束: 事先对验证解决方案的方式达成一致
- 寻找有前途的技术: 发觉那些良好的、健壮的、正在得到关注的技术,让价值/成本比值最大化。如几年前的 Elasticsearch。
- 保持简单: 注重系统的维护,并且让维护变得简单。除非是性能上的强行要求。
- 在数据管道中使用手动的完整性检查: 优化数据处理系统时,容易停留在二进制模式中,即使用高效的、紧凑的二进制数据格式和压缩过的 I/O。这样在很多情况下,数据总是以不可理解的形式进行传递,当系统发生问题时也难以调试。 建议: 对系统中的这些部分计入日志,挑选一些做简单的数据可视化,真实世界的数据总是杂乱无章的。
- 小心地在潮流中导航: 一个客户痴迷 X 技术,并且希望得到他,但他可能并不需要这个技术。X 随时间变化,因为炒作的浪潮来来去去。想想现在可能有哪些 X?大数据?人工智能?
代码优化建议: 很多优化的细节在 radim rehurek 博客 上能找到。
- 流化你的数据,观察你的内存: 学习过程中,很多时候我们把所有数据都装进 RAM。但实际情况下,面对海量数据,这是不可能完成的。
- 利用 Python 的丰富生态系统: gensim Word2vec 就是从一个可读的、使用 numpy 的干净的 word2vec 的移植开始的。numpy 是 python 科学与数字领域的开拓者。虽然他很快,但是还是比 google 的 C 版本 word2vec 慢了不少。
- 配置和编译热点: gensim 团队选择使用 Cython + C。由于团队基于一个移植版本的 word2vec 进行开发,因此优化过程中可以进行免费的单元测试。
- 知道你的 BLAS:
- numpy 中包装了 BLAS(基础线性代数子例程)- 这些是低级的例程集合,直接通过处理器供应商(英特尔、AMD 等)使用汇编、Fortran 或者 C 来做优化,被设计用于从一种特定的处理器架构中挤榨出最佳的性能
- 如,调用一个 axpy 的 BLAS 例程来计算 vector_y += scalar * vector_x,这样比通用的编译器为一 个等价的显式的循环所产生的代码要更快。因此把 word2vec 的训练表示成 BLAS 操作导致了额外的 4 倍速度提升。这也是 python gensim word2vec 快过 google C 版本 word2vec 的关键。
- 并行化和多核、静态内存分配 等,请参考原书最后一章。