Qwen 模型小记(一)
针对 2024 年左右的 Qwen 模型的一些要点记录
Qwen 1.5 系列
发布时间:24 年 2 月。
模型大小:包括 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense 模型,以及 MoE-A2.7B 模型。
架构:32B 以上的模型用了 GQA,其他架构大致相同。
训练:
- RLHF:直接策略优化(DPO)和近端策略优化(PPO)等技术。
- 长序列:全系列支持 32K+ tokens 的上下文
数据:
- 挑选了来自欧洲、东亚和东南亚的 12 种不同语言
官方给出的评分:
| Model | MMLU | C-Eval | GSM8K | MATH | HumanEval | MBPP | BBH | CMMLU |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 86.4 | 69.9 | 92.0 | 45.8 | 67.0 | 61.8 | 86.7 | 71.0 |
| Llama2-7B | 46.8 | 32.5 | 16.7 | 3.3 | 12.8 | 20.8 | 38.2 | 31.8 |
| Llama2-13B | 55.0 | 41.4 | 29.6 | 5.0 | 18.9 | 30.3 | 45.6 | 38.4 |
| Llama2-34B | 62.6 | - | 42.2 | 6.2 | 22.6 | 33.0 | 44.1 | - |
| Llama2-70B | 69.8 | 50.1 | 54.4 | 10.6 | 23.7 | 37.7 | 58.4 | 53.6 |
| Mistral-7B | 64.1 | 47.4 | 47.5 | 11.3 | 27.4 | 38.6 | 56.7 | 44.7 |
| Mixtral-8x7B | 70.6 | - | 74.4 | 28.4 | 40.2 | 60.7 | - | - |
| Qwen1.5-7B | 61.0 | 74.1 | 62.5 | 20.3 | 36.0 | 37.4 | 40.2 | 73.1 |
| Qwen1.5-14B | 67.6 | 78.7 | 70.1 | 29.2 | 37.8 | 44.0 | 53.7 | 77.6 |
| Qwen1.5-32B | 73.4 | 83.5 | 77.4 | 36.1 | 37.2 | 49.4 | 66.8 | 82.3 |
| Qwen1.5-72B | 77.5 | 84.1 | 79.5 | 34.1 | 41.5 | 53.4 | 65.5 | 83.5 |
Qwen1.5 MOE,模型总共有 14.3 的参数,实际推理过程中,只是用到了 2.7B。
Qwen 1.5 MOE 对 Mixtral MOE 的架构进行了优化,包括 Finegrained experts,初始化,新的 routing 机制等。更多欢迎参考 https://qwenlm.github.io/zh/blog/qwen-moe/
Qwen 2 系列
架构: Dense 模型及 MOE 模型与 Qwen 1.5 对应版本的架构一样。
模型大小: 有 0.5B,1.5B,7B 和 72B 四种 dense 模型;同时还有一个 57B-A14B 的 MOE。
预训练: 训练数据 一共有 7T,包含了 30 种语言,数据中收集了更多高质量的代码、数学和多语种数据。
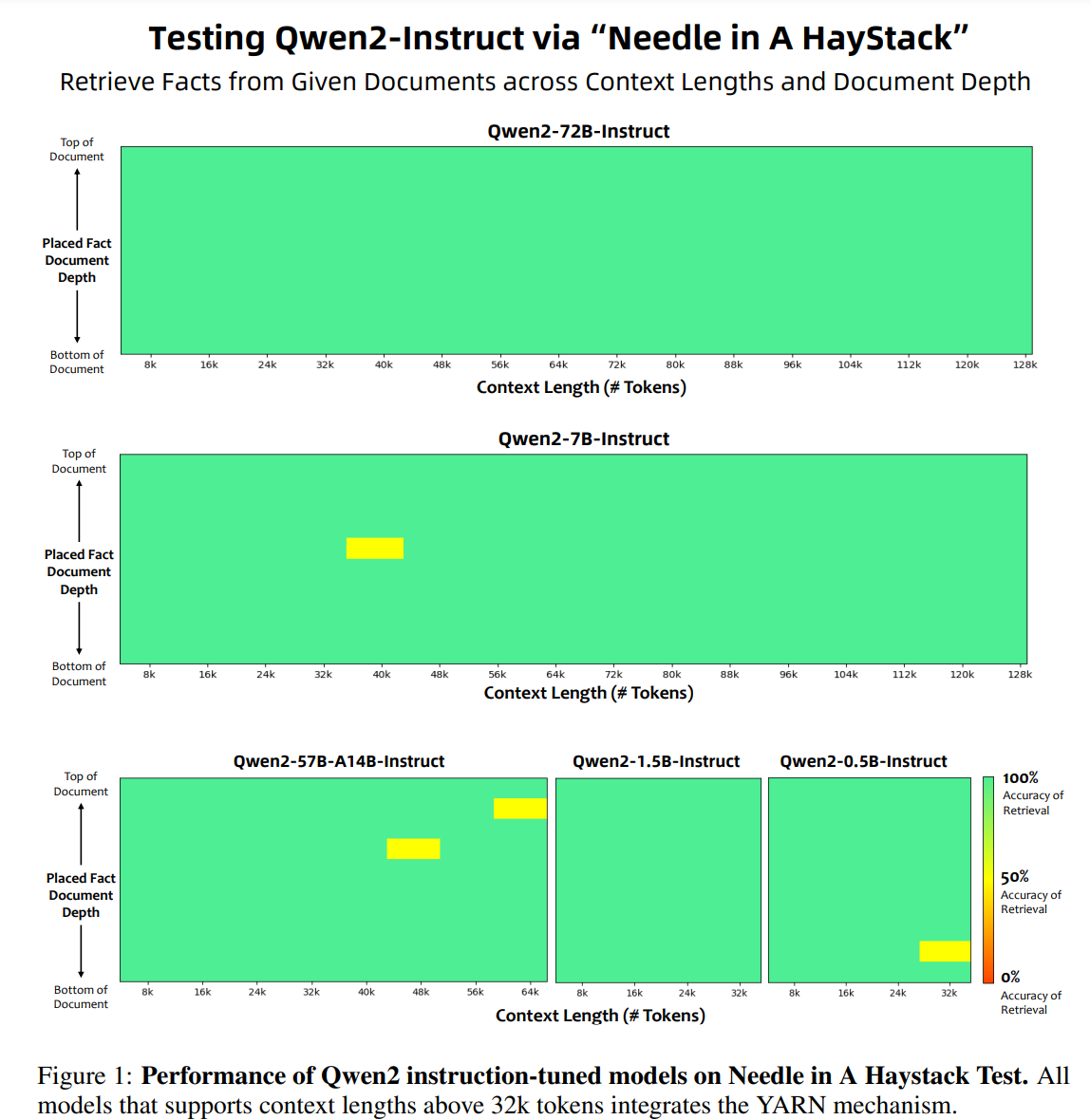
超长上下文: 先用 4096 的长度训练,而后再训练结束前,换成 32K。采用了 YARN 和 Dual Chunk Attention。以下为大海捞针评测:
SFT: 用了超过 500K 的实例进行训练,数据集中包含指令遵循,代码,数学,逻辑推理,角色扮演,安全等数据。finetune 了 2 个 epoch,训练文本长度限制再了 32K。
RLHF:
- 离线训练: 用 DPO 再标注好的偏好数据集上训练。
- 在线训练: 同样采用 DPO,同时采用 Online Merging Optimizer 来缓解对齐税。
模型效果:
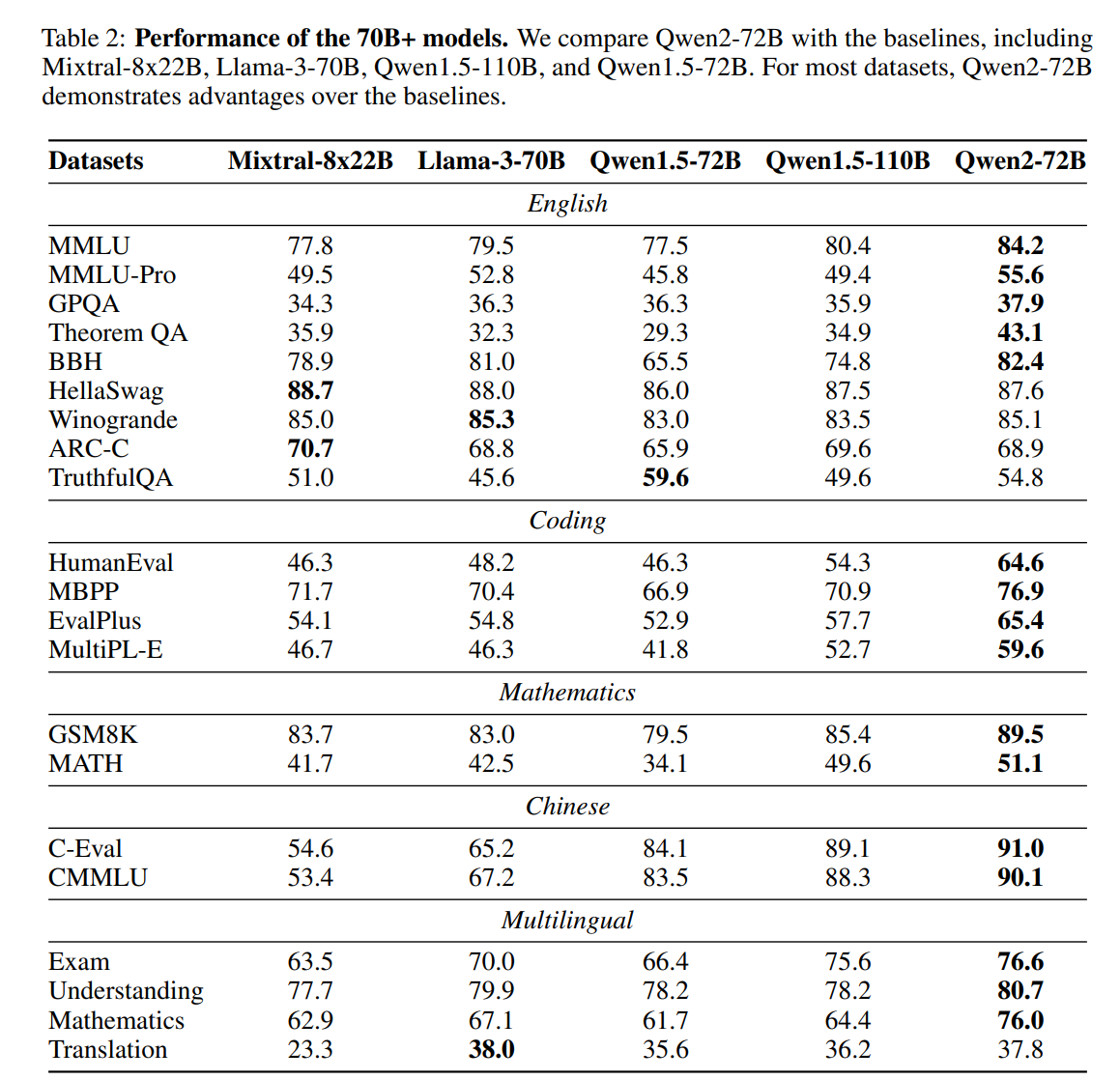
Qwen2 72B 效果:
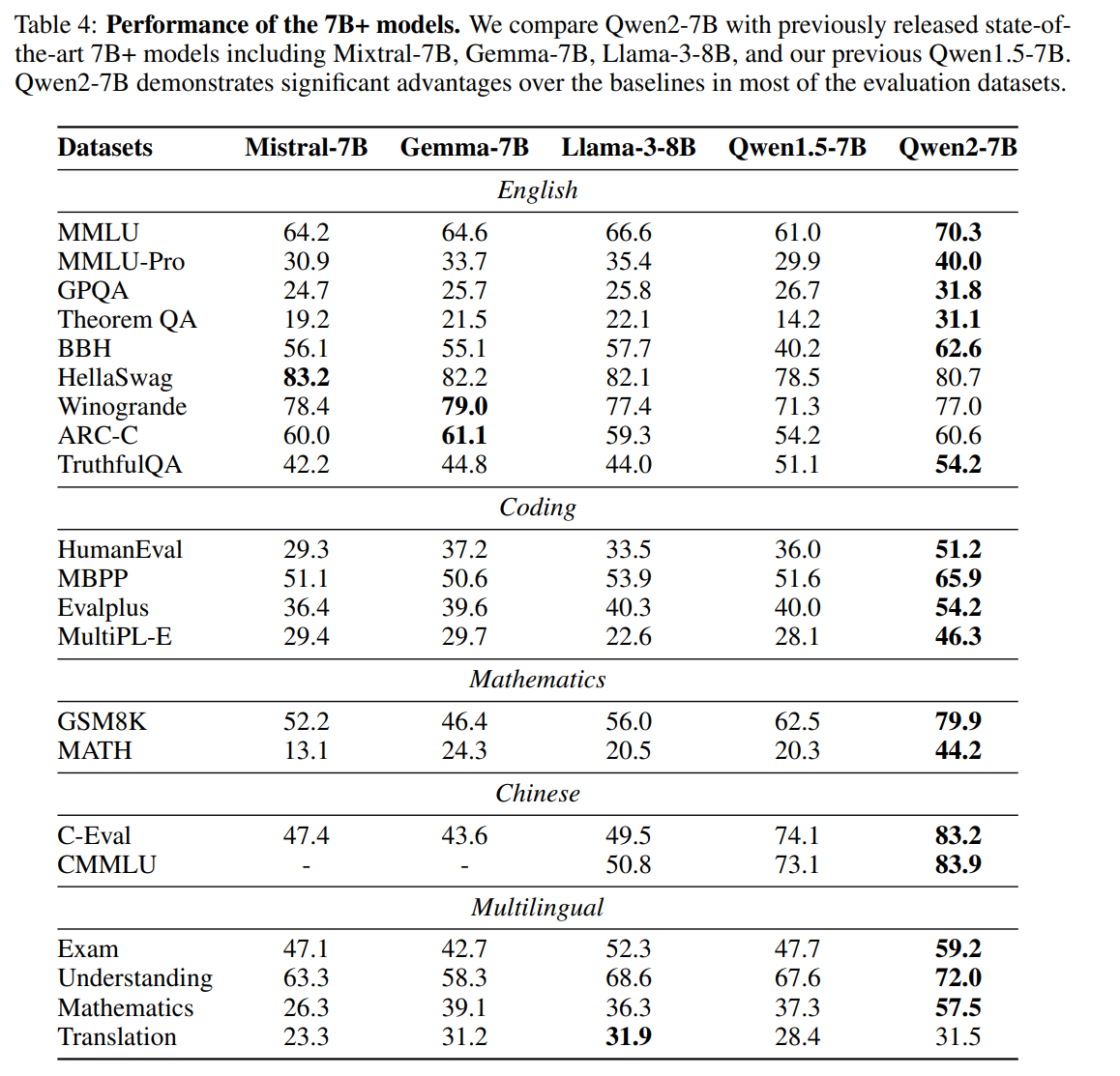
Qwen2 7B 效果:
更多模型效果可以查看:Qwen2 官网
Qwen-Audio
Arxiv: https://arxiv.org/pdf/2311.07919
23 年发布的模型,再当时就有了一定的语音理解能力。
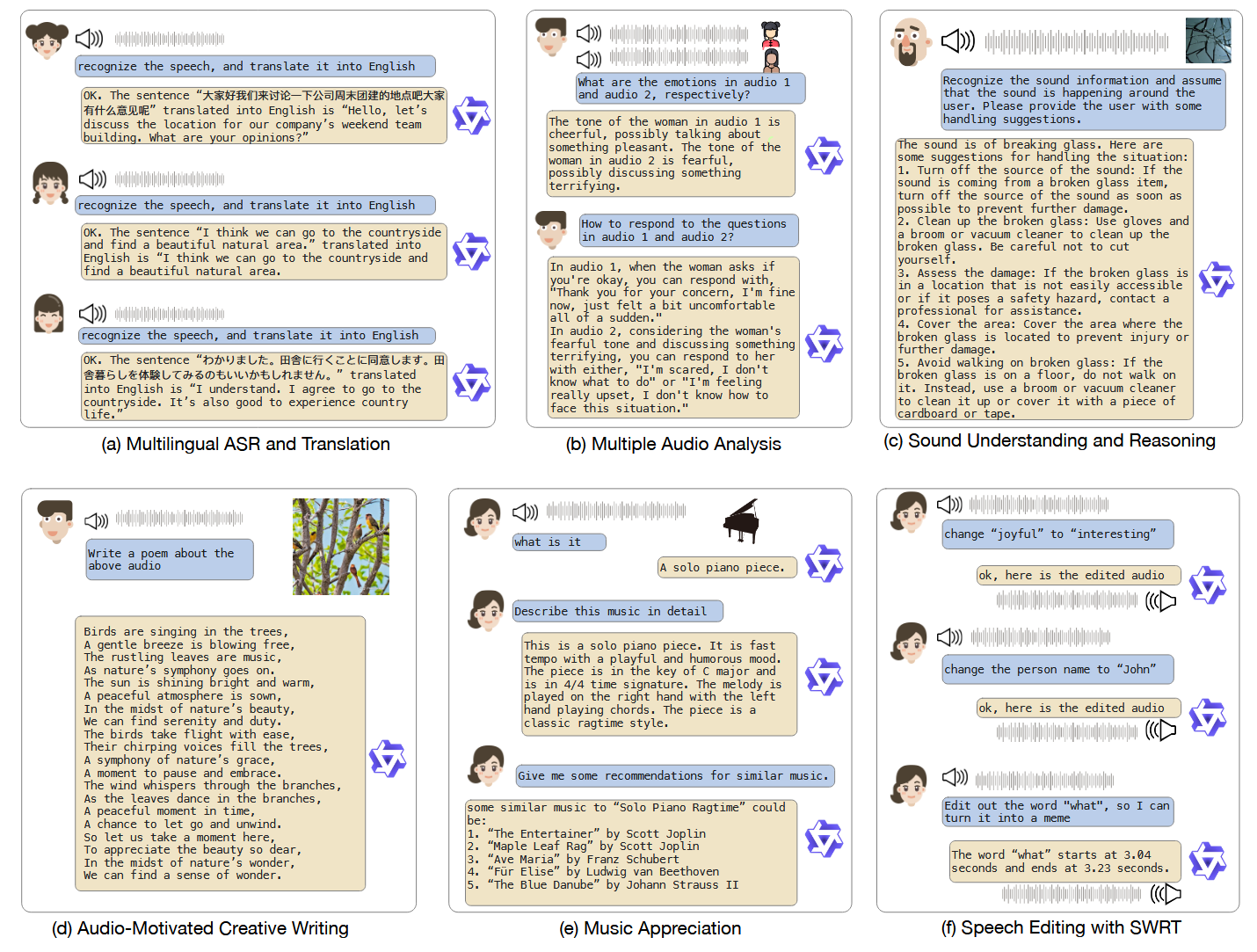
模型架构如下,
- audio encoder 采用 Whisper-large-v2(32 层 transformer+2 个 Conv Down-sampling Layer),采样率 16KHz;音频被处理成 80 channel 的 mel spectrogram。
- QwenLM 采用 Qwen-7B
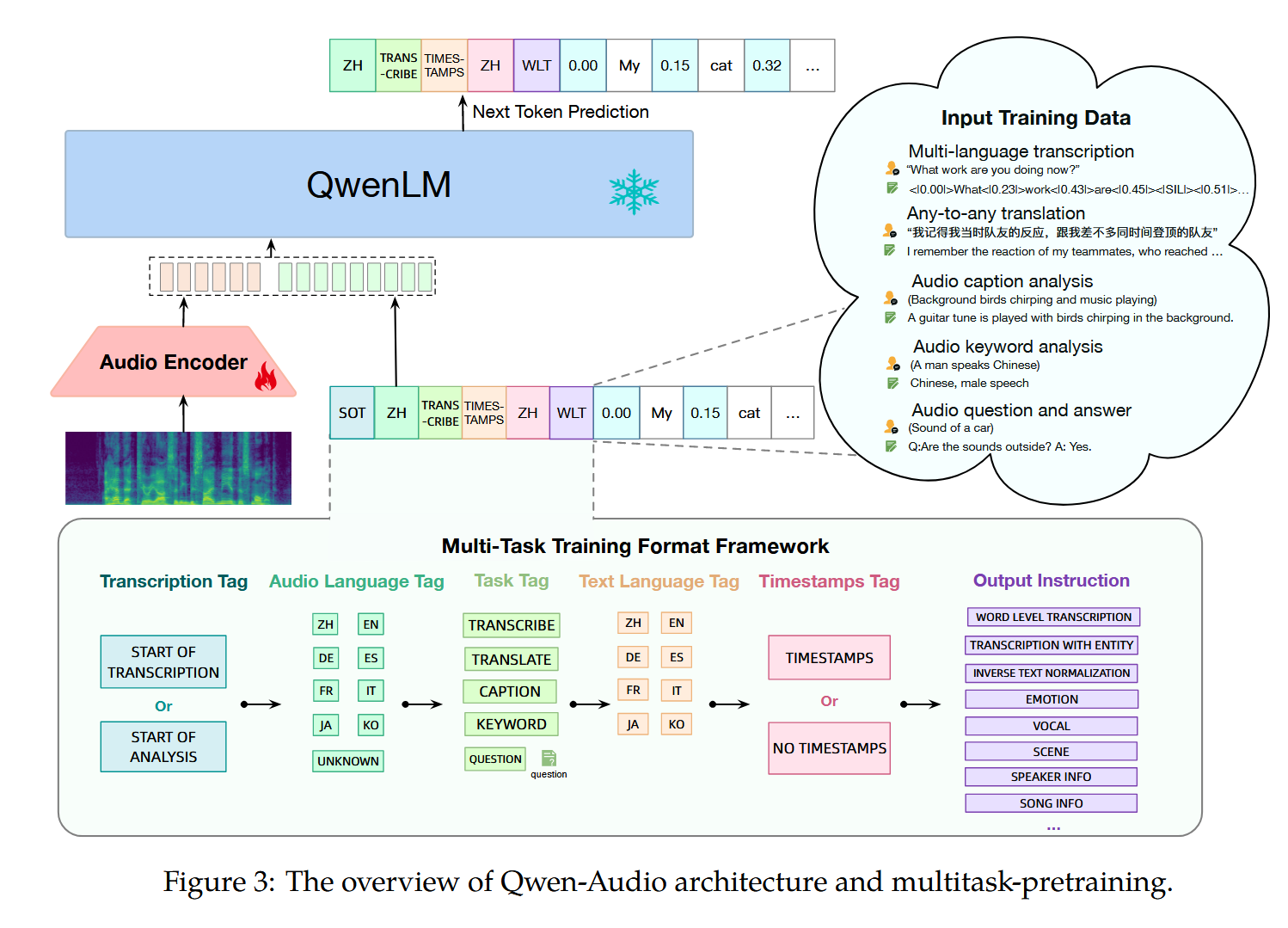
预训练
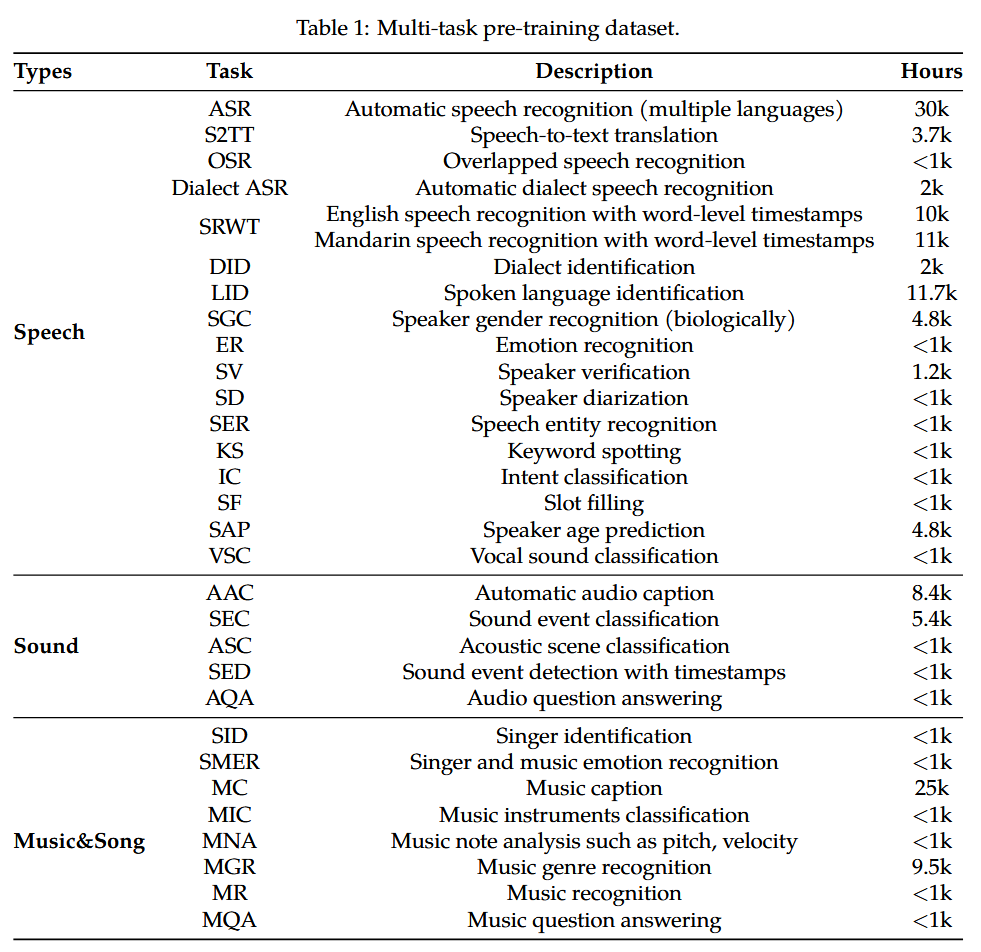
预训练采用了 multitask pretraining,预训练的数据集如下:
Whispher 模型中,有上下文标记(special token)来处理不同任务,比如说语言检测,翻译,等等。Qwen-Audio 也采用了相似的处理方式,加入了不同的 tags,可以参考上方的架构图中的 tags:
- 采用 Transcription Tag:预测的开始由转录标签表示。使用
<|startoftranscripts|>标签来表明任务是准确转录语音内容并捕捉语言信息,例如语音识别和语音翻译任务。而对于其他类型的任务,则使用<|startofanalysis|>标签。 - 采用 Audio Language Tag:用于指示音频中的口语语言。这个标签使用一个唯一的标记,对应训练集中出现的每种语言(共八种语言)。如果某段音频中不包含语音,例如自然声音或音乐,模型会被训练去预测
<|unknown|>标签。 - Task Tag:将采集的音频任务分为五类:
<|transcribe|>、<|translate|>、<|caption|>、<|analysis|>和<|question-answer|>任务。对于问答(QA)任务,会在标签后附加相应的问题。 - Text Language Tag:制定需要输出的语言类型。
- Timestamps Tag:时间戳的有无由
<|timestamps|>或<|notimestamps|>标签决定。与 Whisper 中的句级时间戳不同,<|timestamps|>标签要求模型进行细粒度的词级时间戳预测(SRWT,Speech Recognition with Word-level Timestamps)。在这种模式下,预测的时间戳与转录词交错:在每个转录词之前预测开始时间标记,在其之后预测结束时间标记。根据我们的实验,SRWT 提升了模型对音频信号与时间戳的对齐能力。这种改进使模型对语音信号的理解更加全面,从而在语音识别和音频问答等多项任务中取得显著进步。 - Output Instruction:输出指令
微调
采用了下面这种 instruction 方式构造 template,总共训练数据是 20K

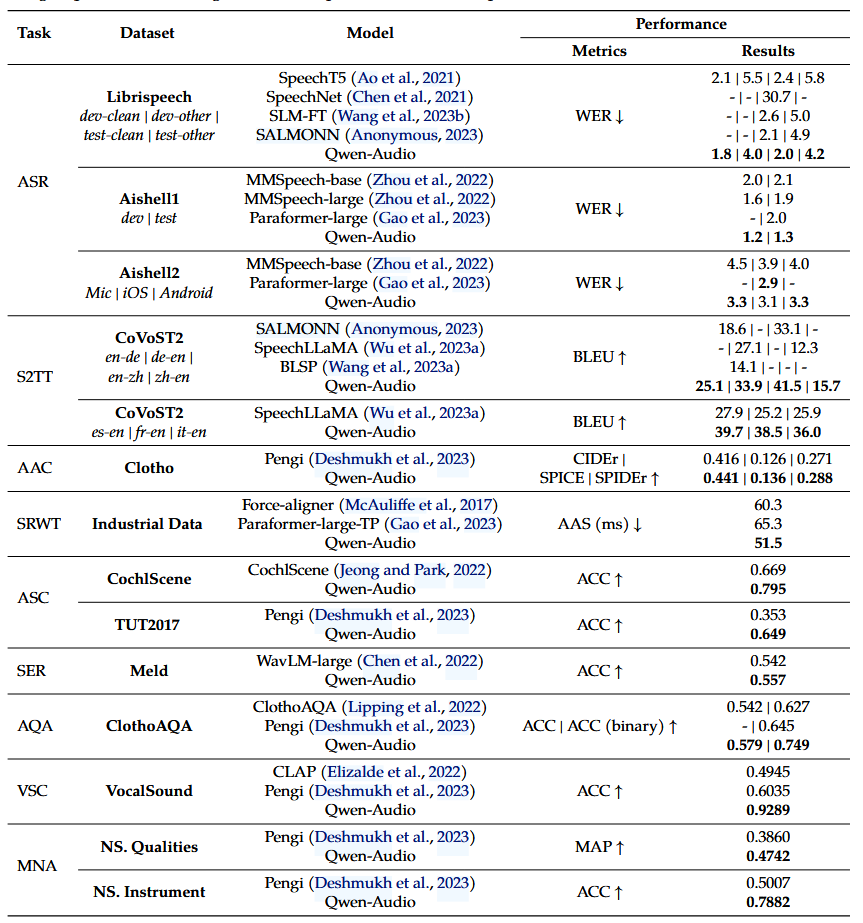
可以看到在各种任务上,Qwen-Audio 在当时的效果还是不错的:
Qwen2-Audio
arxiv: https://arxiv.org/abs/2407.10759
24 年 8 月左右进行了 Qwen2-Audio 的更新
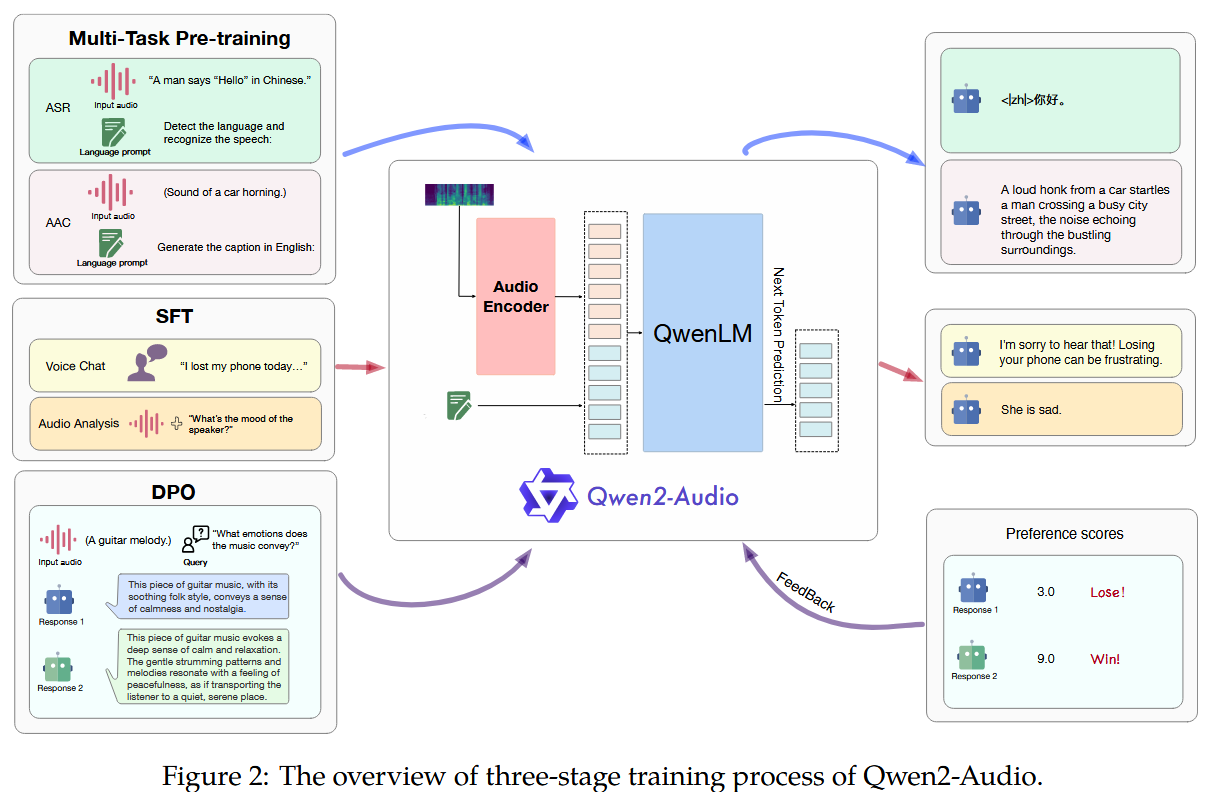
架构
- Audio Encoder 通过 Whisper-large-v3 初始化,采样频率 16kHz,转换成 128 channel 的梅尔频谱(window size 25ms, hop size 10 ms);同时采用 pooling layer(stride 2)来减少表征的长度。
预训练:
- 与 Qwen-Audio 的差别很大,在这一代中取消了 tags 的处理,使用了自然语言 prompt 来进行训练,可以参考上面架构图中的例子。
- 370k 数据为 speech,10k 为 sound,140k 为 music。
SFT
分了 2 中不同的交互模式,两种模式是同时训练的:
- Audio Analysis:通常用于线下的音频分析。
- Voice Chat:通常用于实时对话。
RLHF:
- 采用了 DPO
Qwen-VL
论文:https://arxiv.org/pdf/2308.12966
效果:23 年提出的 VL 版本已经表现出了一定的 instruction following 能力,以及 in context learning 能力,并且模型具备一定的理解图片能力。qwen VL 在训练之后,似乎纯文字能力并没有降低。
潜在的优化点:learnable query 的作用类似于连续型的 prompt,直觉上看,增加多类型预训练任务能够提高模型在推理时候的泛化能力。参考 GPT-3 以及 FLAN 系列模型的对比,应该有比 learnable query 更好的图片 embedding 方式。图片 embedding 似乎永远放在了最前面,图片像素限制容易丢失信息。
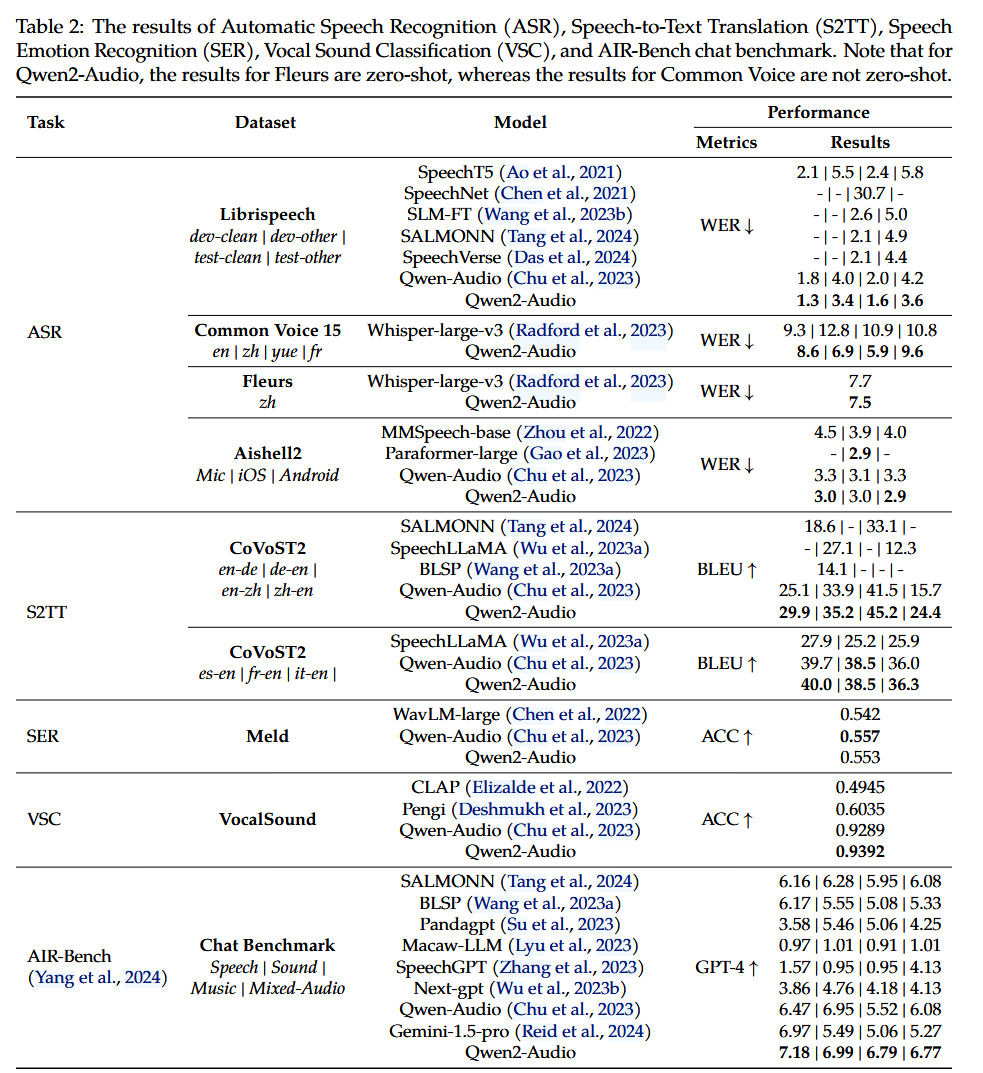
模型架构:
Vistion Encoer:
- 采用 Openclip’s ViT-bigG 的预训练权重。
- 推理和训练时候,图像会 resize 到特定的像素。
- VIT 将图片转化为 patch 时候,采用了 14 的 stride
Position-aware Vision-Language Adapter
- 该适配器由一个随机初始化的单层交叉注意力模块组成,该模块使用一组可训练向量(Embedding)作为查询向量 ,并将来自视觉编码器的图像特征作为键进行交叉注意力操作,从而将视觉特征序列压缩至固定长度 256。
- 为了弥补压缩过程中丢失掉的位置信息,cross-attension 中加入了 2D absolute positional encodings
Large Language Model
- 采用了 Qwen-7B 作为 LLM。
输入输出样式:
- 添加了
<img> and </img>token 来标记图像 feature。 - 训练过程中加入了 bbox 和对应 reference 的信息,并用
(<ref> and </ref>)以及<box> and </box>来标记。
总体训练架构如下,训练分为 3 步:
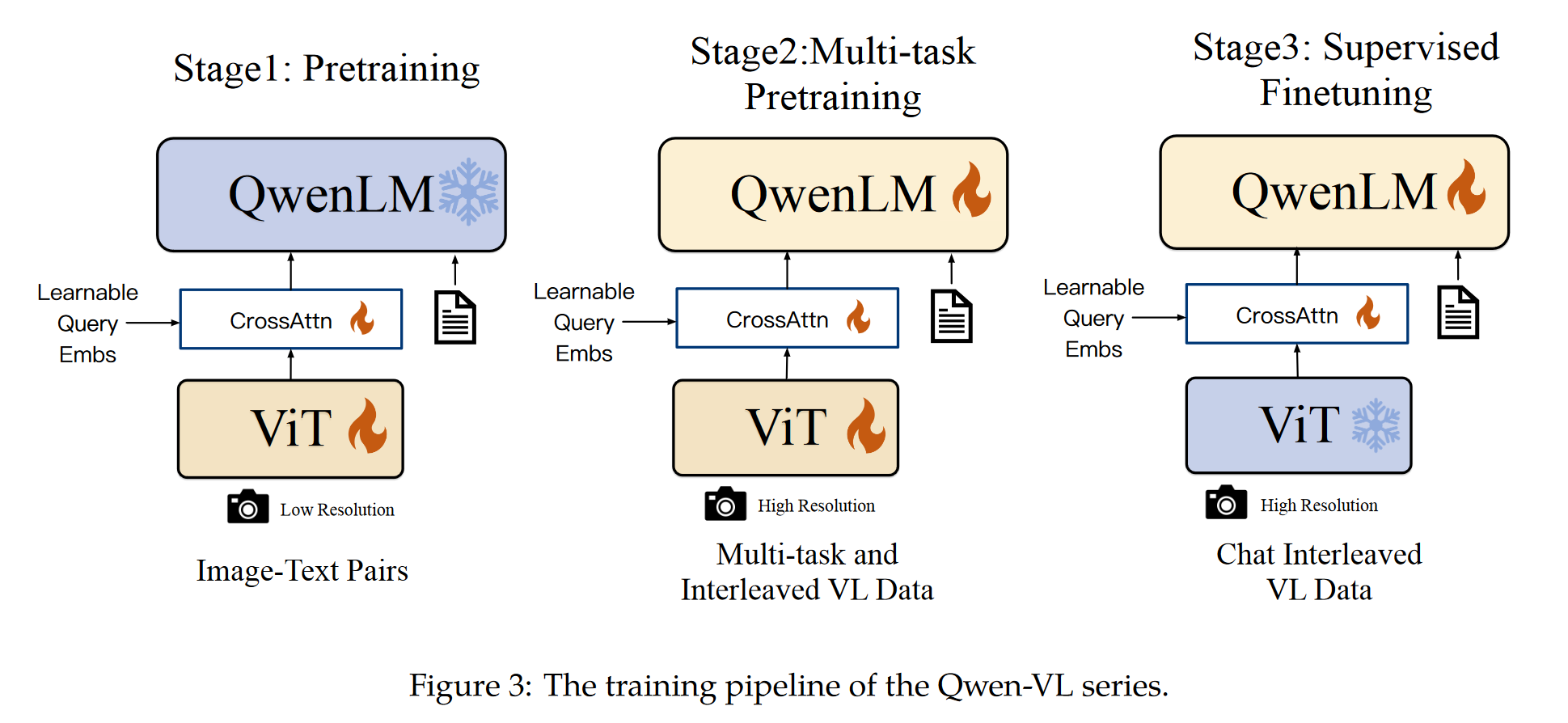
- 第一步:预训练数据分布(数据为 224x224 image-text pair,共 1.4 billion)冻结 LLM 只训练 Vision encoder 和 VL adapter:优化目标,NTP
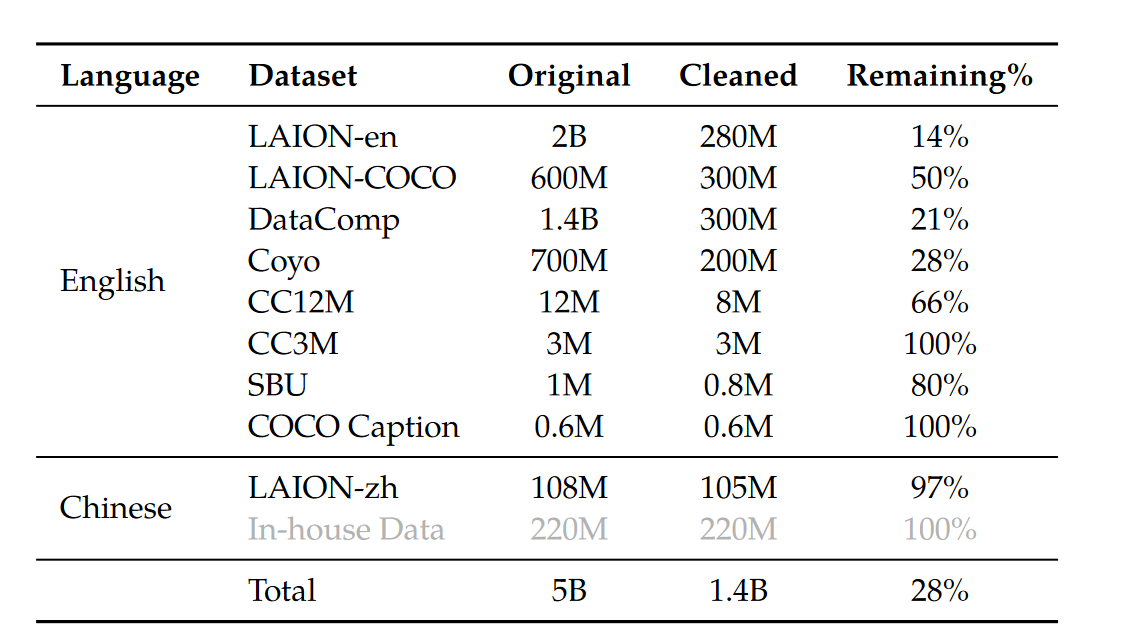
- 第二部:multi-task pretraining。input image 大小增大到 448x448。整个模型都进行优化,优化目标和第一阶段一样。
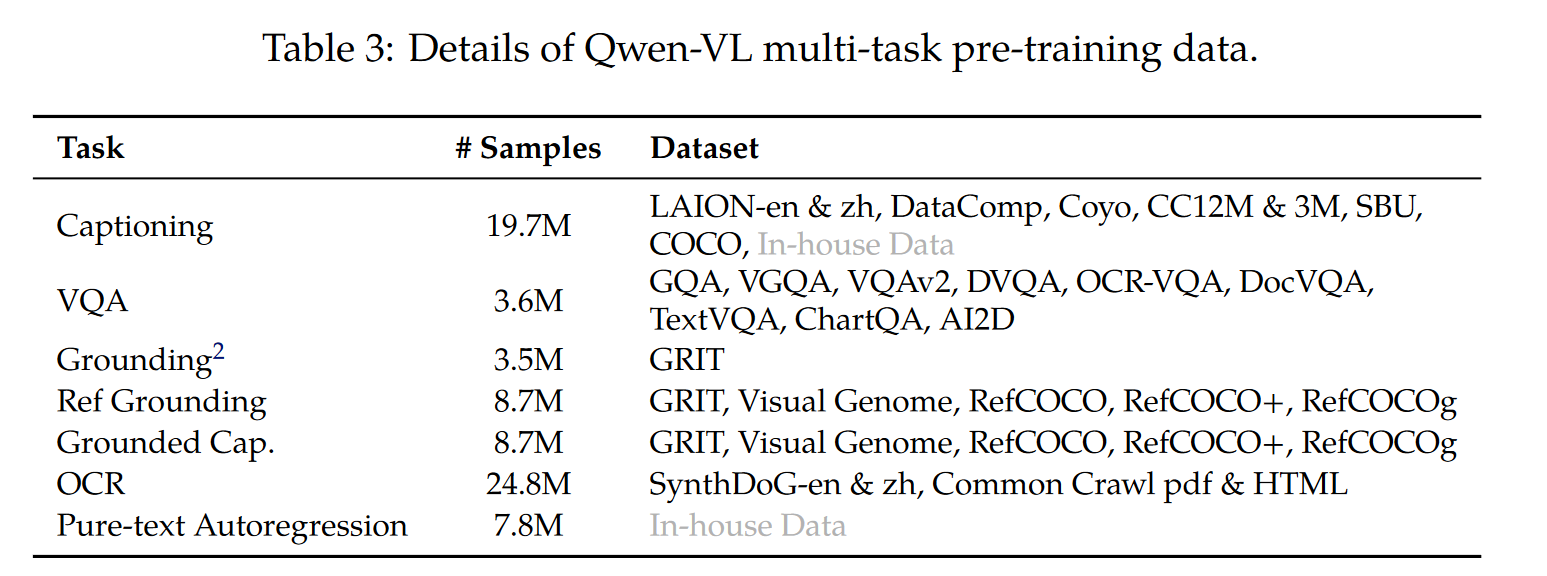
训练数据格式如下:
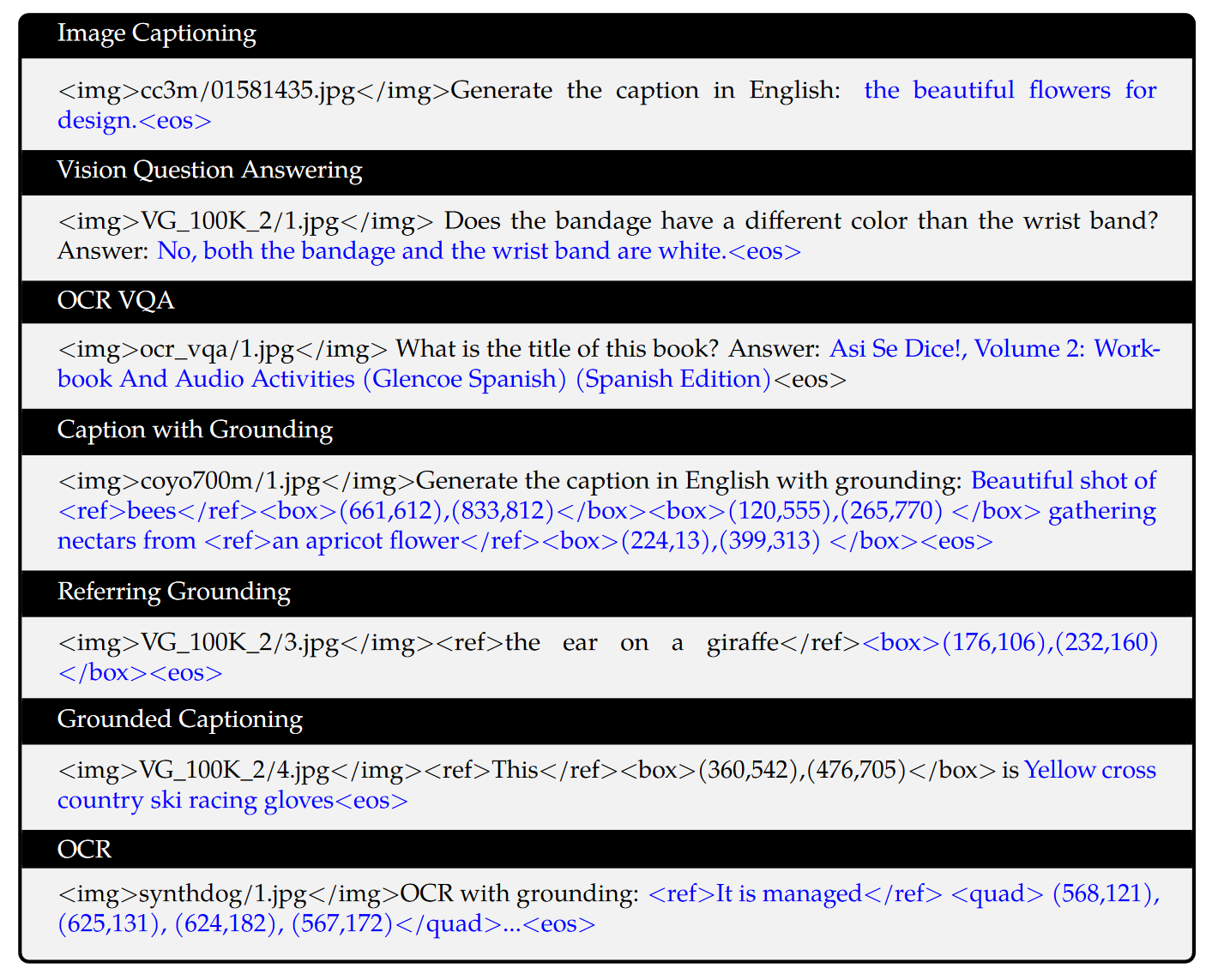
其中比较有意思的是 <ref> 以及 <box> 的使用方式,有点用点读机教小朋友的感觉。
- 第三步:SFT。数据数量共 350k,数据格式如下,只训练 LLM 部分:
<im_start>user
Picture 1: <img>vg/VG_100K_2/649.jpg</img>What is the sign in the picture?<im_end>
<im_start>assistant The sign is a road closure with an orange rhombus.<im_end>
<im_start>user How is the weather in the picture?<im_end>
<im_start>assistant The shape of the road closure sign is an orange rhombus.<im_end>
Qwen2-VL
官方博客:https://qwenlm.github.io/zh/blog/qwen2-vl/
论文:https://arxiv.org/pdf/2409.12191
huggingface:https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
主要特点:模型提供了 2B, 7B, 72B 三种尺寸; 支持不同分辨率图片,支持视频理解,能操控手机或机器人。
- 读懂不同分辨率和不同长宽比的图片 :Qwen2-VL 在 MathVista、DocVQA、RealWorldQA、MTVQA 等视觉理解基准测试中取得了全球领先的表现。
- 理解 20 分钟以上的长视频 :Qwen2-VL 可理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中。
- 能够操作手机和机器人的视觉智能体 :借助复杂推理和决策的能力,Qwen2-VL 可集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作。
- 多语言支持 :为了服务全球用户,除英语和中文外,Qwen2-VL 现在还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
官方博客中有示例,可以看出 qwen2-vl 可以理解颜色,位置,文字内容等图片内容。同时可以根据这些内容进行一定的推理。此外还具备视频理解功能,根据官方提供的视频理解示例,Qwen2-vl 可以做到实时视频聊天。此外,qwen2-vl 还加入了 function calling 功能,有了 function call 后,就可以实现一些如智能体控制屏幕的功能。当然官方表示这些功能还都不是很完美。
模型架构:
- Qwen2-VL 在架构上的一大改进是 修改了图像编码器 ,实现了对 原生动态分辨率 的全面支持。与上一代模型相比,Qwen2-VL 能够处理任意分辨率的图像输入,不同大小图片被转换为动态数量的 tokens,最小只占 4 个 tokens。
- 修改了 vit 中的绝对位置编码,改为了 2D-RoPE,
- 用
<|vision_start|> and <|vision_end|>来区分图片信息。 - 使用 1 个 MLP 层压缩 VIT 的输出,来限制 token 数量。MLP 将临近的 2*2 的 token 转换为 1 个 token。比如 224 乘 224 的图片,如果 patch size = 14 的话,图片会被压缩成 66 个 token (224/14 * 224/14 / 4 + 2)。
- 对于视频输入,采用了 3D 的 2x2 Conv 层来进行 embedding。(16 * 336/14 * 644/14 / 8 = 2208)
- 参考下图的架构,似乎图片编码可以放在任意的位置。

- Qwen2-VL 在架构上的另一重要创新则是 多模态旋转位置嵌入(M-ROPE) ,M-ROPE 通过将原始旋转嵌入分解为代表时间、高度和宽度的三个部分,使得大规模语言模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息。
- 视频理解:每秒 2 帧进行采样。通过 3D Conv (depth=2)来编码。
输入数据格式如下:


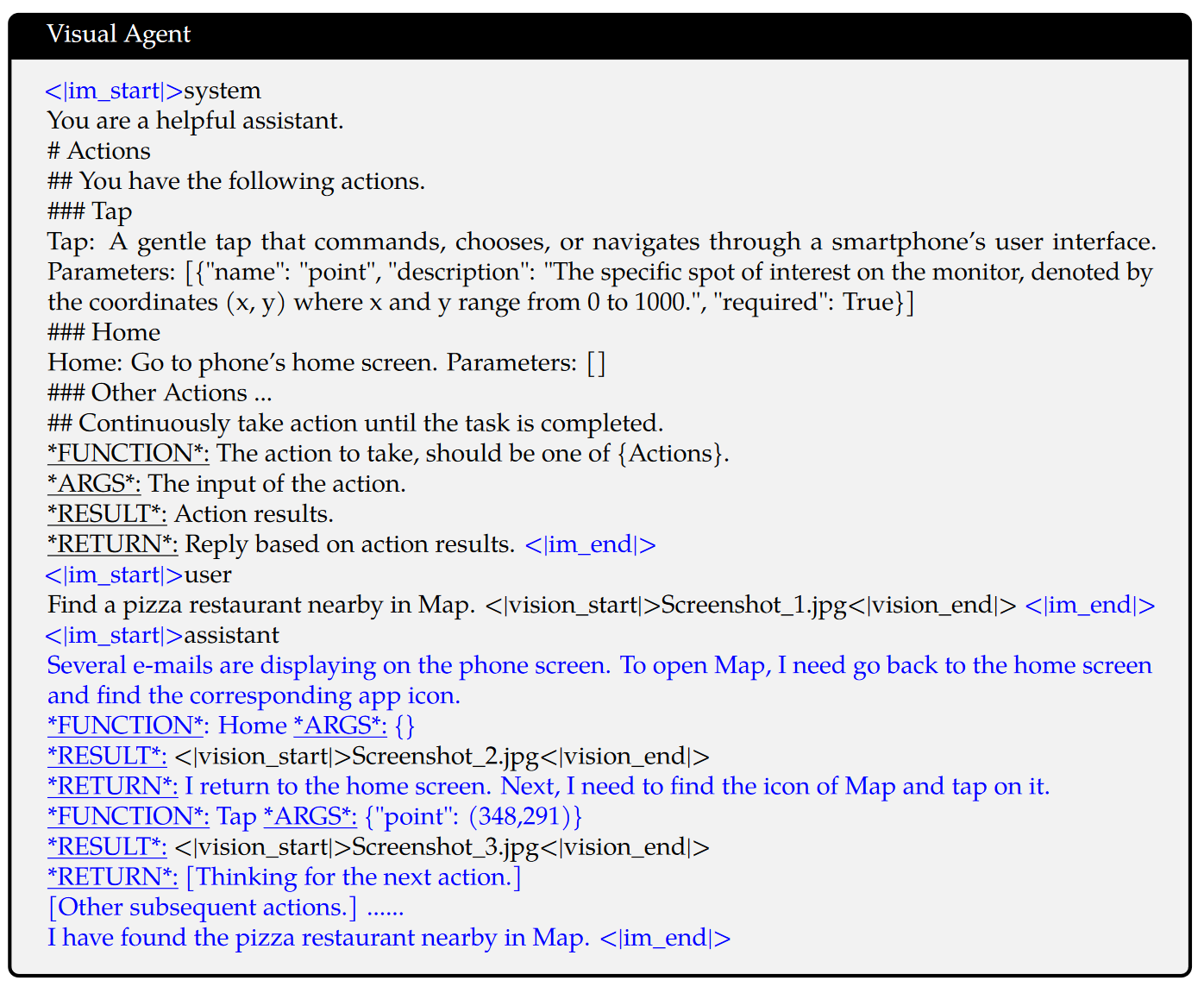
训练方法
主要重点整理:
- 三阶段训练方法
- 第一阶段:专注训练视觉变换器(ViT),利用海量图像-文本对增强 LLM 的语义理解。
- 第二阶段:解冻所有参数,使用更丰富的数据进行全面训练。
- 第三阶段:锁定 ViT 参数,利用指令数据集对 LLM 进行专门微调。
- 预训练数据集
- 数据种类包括:图像-文本对、OCR 数据、交错图文文章、视觉问答数据集、视频对话、图像知识数据集。
- 数据来源主要为清洗后的网页、开源数据集和合成数据(数据截止至 2023 年 6 月)。
- 初始预训练阶段
- 模型处理约 6000 亿个标记。
- LLM 组件初始化采用 Qwen2 参数;视觉编码器初始化使用 DFN 的 ViT,并将固定位置嵌入替换为 RoPE-2D。
- 主要任务为学习图像与文本的关系、OCR 文本识别和图像分类。
- 第二阶段预训练
- 增加 8000 亿个与图像相关的标记,加入更多混合图文内容和视觉问答数据。
- 引入多任务数据集,强化模型对复杂视觉-文本交互的理解,同时维持纯文本语言能力。
- 总体预训练量与监督
- 累计处理 1.4 万亿个标记(包括文本和图像标记,但训练时仅对文本标记提供监督)。
- 指令微调阶段
- 使用 ChatML 格式构建指令跟随数据,涵盖纯文本及多模态(图像问答、文档解析、多图像比较、视频理解、视频流对话、代理交互)对话数据,提升模型多模态任务执行能力。
Qwen2.5
arxiv: https://arxiv.org/abs/2412.15115
博客:https://qwenlm.github.io/zh/blog/qwen2.5-llm/
hugginface:https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
24 年 9 月左右推出了 Qwen2.5-LLM,对标模型 llama 3.1 和 GPT-4o-mini
模型架构:
- 模型大小:1.5B、3B、7B、32B、72B;
- 架构:dense 模型与 Qwen2 模型类似,采用 GQA + SwiGLU + ROPE + RMSNorm
- tokenizer 采用 byte-level byte-pair encoding (BBPE)
数据:
- 提升到了 18T token 预训练数据。采用 Qwen2-Instruct 过滤数据,同时确保每个 domain 上的数据量差不多;预训练添加了 Qwen2.5-Math, 和 Qwen2.5-Coder 的语料,添加了更多数学和代码语料;添使用 Qwen2-72B-Instruct 和 Qwen2-Math-72B-Instruct 生成了一些合成数据集。
训练:总体训练包括,
- pretraining
- Long-context pre-training,用于拓展上下文, 主要用了 YARN 和 DCA
- post-training:
- SFT: 包括了 Long-sequence Generation, Mathematics,Coding,Instruction-following,Structured Data Understanding,Logical Reasoning,Robust System Instruction,Response Filtering 等其他方面的微调。
- Offline Reinforcement Learning: 用了 DPO。使用 SFT 模型进行采样,采样后样本经过人工+自动化双重筛选,决定是正样本还是负样本。一共有 150k 个训练样本,学习率
7e-7 - Online Reinforcement Learning :用了 GRPO,用与调整模型在例如 Truthfulness, Helpfulness, Conciseness, Relevance, Harmlessness, Debiasing 相关的能力。
QwQ - Qwen with Question
博客:
QWQ-32B-preview:https://qwenlm.github.io/zh/blog/qwq-32b-preview/
QwQ-32B:https://qwenlm.github.io/zh/blog/qwq-32b/
QwQ-Max-preview:https://qwenlm.github.io/zh/blog/qwq-max-preview/
huggingface:https://huggingface.co/collections/Qwen/qwq-674762b79b75eac01735070a
QwQ 系列的模型,强化了推理能力,下图为与 DeepSeek-R1 和 o1 的对比:
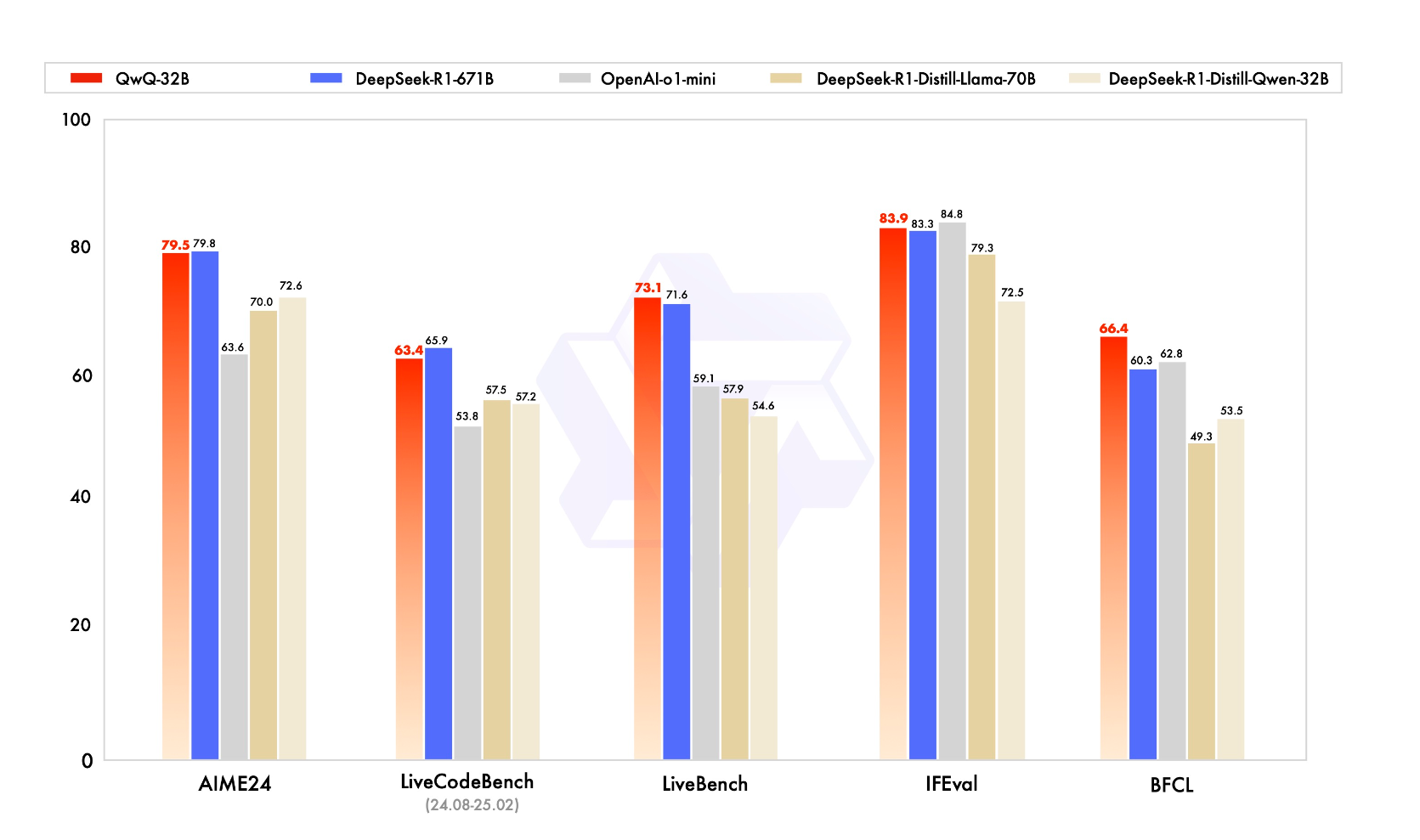
QwQ-32B:
模型架构与 Qwen2.5 差不多,比 Qwen2.5 多添加了 <think>, </think> 之类的符号。
对于以下 API request
{
"messages":[
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!很高兴见到你,有什么我可以帮忙的吗?无论是学习、工作还是生活中的问题,都可以告诉我哦!😊"},
{"role": "user", "content": "(10+10) * 13 等于多少"}
],
"model":"gpt-4o-mini",
"temperature": 0,
"stream": false,
"max_tokens":200
}
模型在 completion 情况下,返回的内容是:
{
"id": "chatcmpl-2fd0a9663c0a4dc48b977507fd553ab7",
"object": "chat.completion",
"created": 1746191230,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "<think>\n 首先,计算括号内的 10 加 10,得到 20。\n\n 然后,将 20 乘以 13,得到 260。\n\n 因此,最终答案是 260。\n</think>\n\n 要计算 \\((10 + 10) \\times 13\\),按照运算顺序进行如下步骤:\n\n1. **计算括号内的加法** :\n \\[\n 10 + 10 = 20\n \\]\n\n2. **将结果乘以 13** :\n \\[\n 20 \\times 13 = 260\n \\]\n\n 因此,最终答案是:\n\\[\n\\boxed{260}\n\\]",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 16,
"total_tokens": 165,
"completion_tokens": 149,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
当使用 QwQ-32B-AWQ 进行 tool 推理时候,模型的输入为:
<|im_start|>system
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"type": "function", "function": {"name": "get_current_weather", "description": "Get the current weather", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}, "format": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The temperature unit to use. Infer this from the users location."}}, "required": ["location", "format"]}}}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call><|im_end|>
<|im_start|>user
what is the whether in shanghai<|im_end|>
<|im_start|>assistant
<think>
对应的输出为:
Okay, the user is asking for the weather in Shanghai. I need to use the get_current_weather function. Let me check the parameters required. The function needs location and format. The location here is clearly Shanghai. But the format can be either celsius or fahrenheit. The description says to infer the format based on the user's location. Since Shanghai is in China, which typically uses Celsius, I should set the format to celsius. So the arguments should be {"location": "Shanghai", "format": "celsius"}. Let me make sure there are no typos. Yep, looks good. Time to put it in the tool_call format.
</think>
<tool_call>
{"name": "get_current_weather", "arguments": {"location": "Shanghai", "format": "celsius"}}
</tool_call>
- 总结
对于涉及 reasoning 的模型,一般还是通过 prompt 中构造 xml 来实现 reasoning 以及 tool 的使用。参考 QwQ 以及 deepseek R1 distill,似乎训练数据中有包含了对输出格式约束的案例。
Qwen 2.5 Vl
博客:Qwen2.5VL , Qwen2.5vl-32B
huggingface: https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
arxiv:https://arxiv.org/abs/2502.13923
Qwen2.5-VL 的主要特点如下所示(摘抄于 qwen 博客):
- 感知更丰富的世界 :Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。
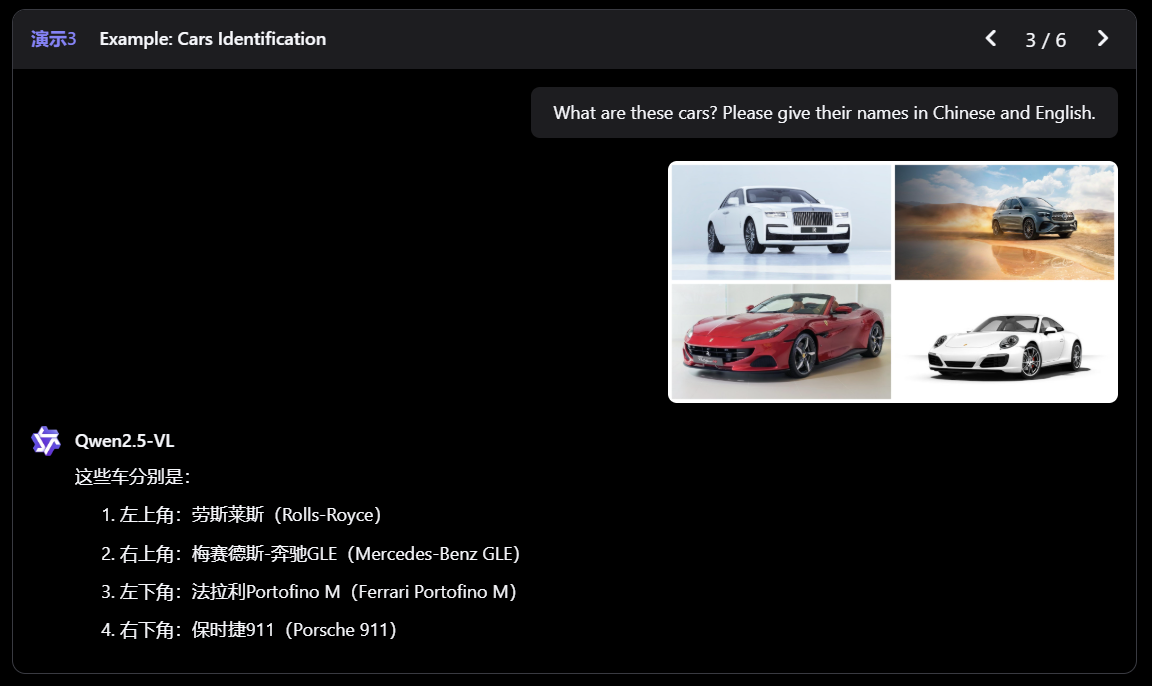
- Agent :Qwen2.5-VL 直接作为一个视觉 Agent,可以推理并动态地使用工具,初步具备了使用电脑和使用手机的能力。如告诉 agent 使用手机 QQ 给某位好友发送新年祝福。
- 理解长视频和捕捉事件 :Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
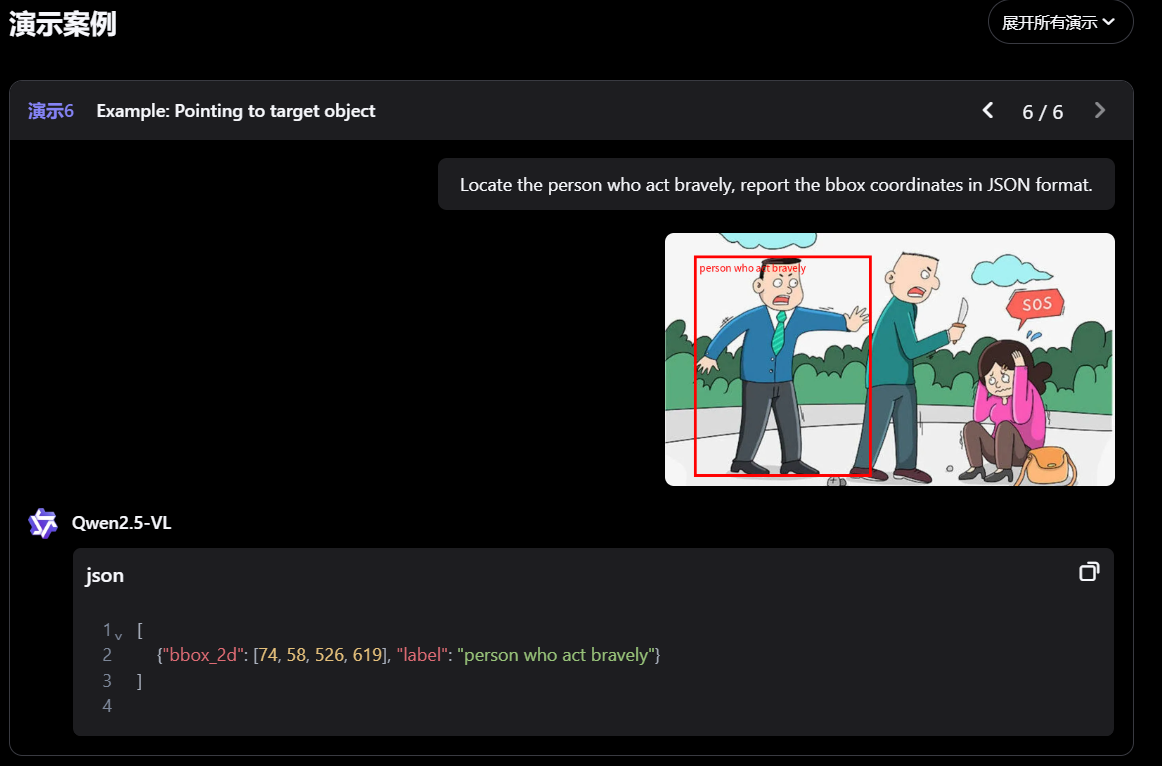
- 视觉定位 :Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。(有点类似目标检测)
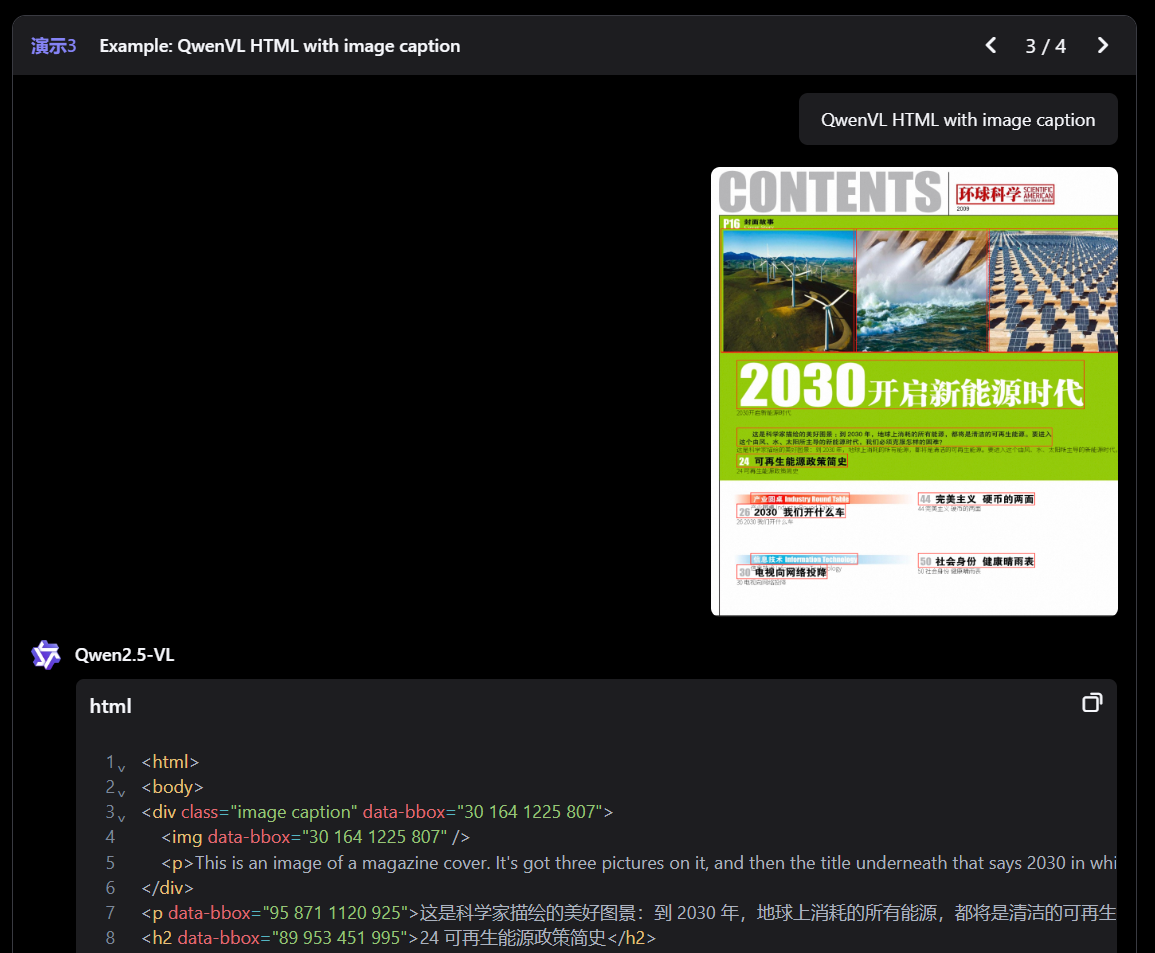
- 结构化输出 :对于发票、表单、表格等数据,Qwen2.5-VL 支持其内容的结构化输出,惠及金融、商业等领域的应用。在 Qwen2.5-VL 中设计了一种更全面的文档解析格式,称为 QwenVL HTML 格式,它既可以将文档中的文本精准地识别出来,也能够提取文档元素(如图片、表格等)的位置信息,从而准确地将文档中的版面布局进行精准还原
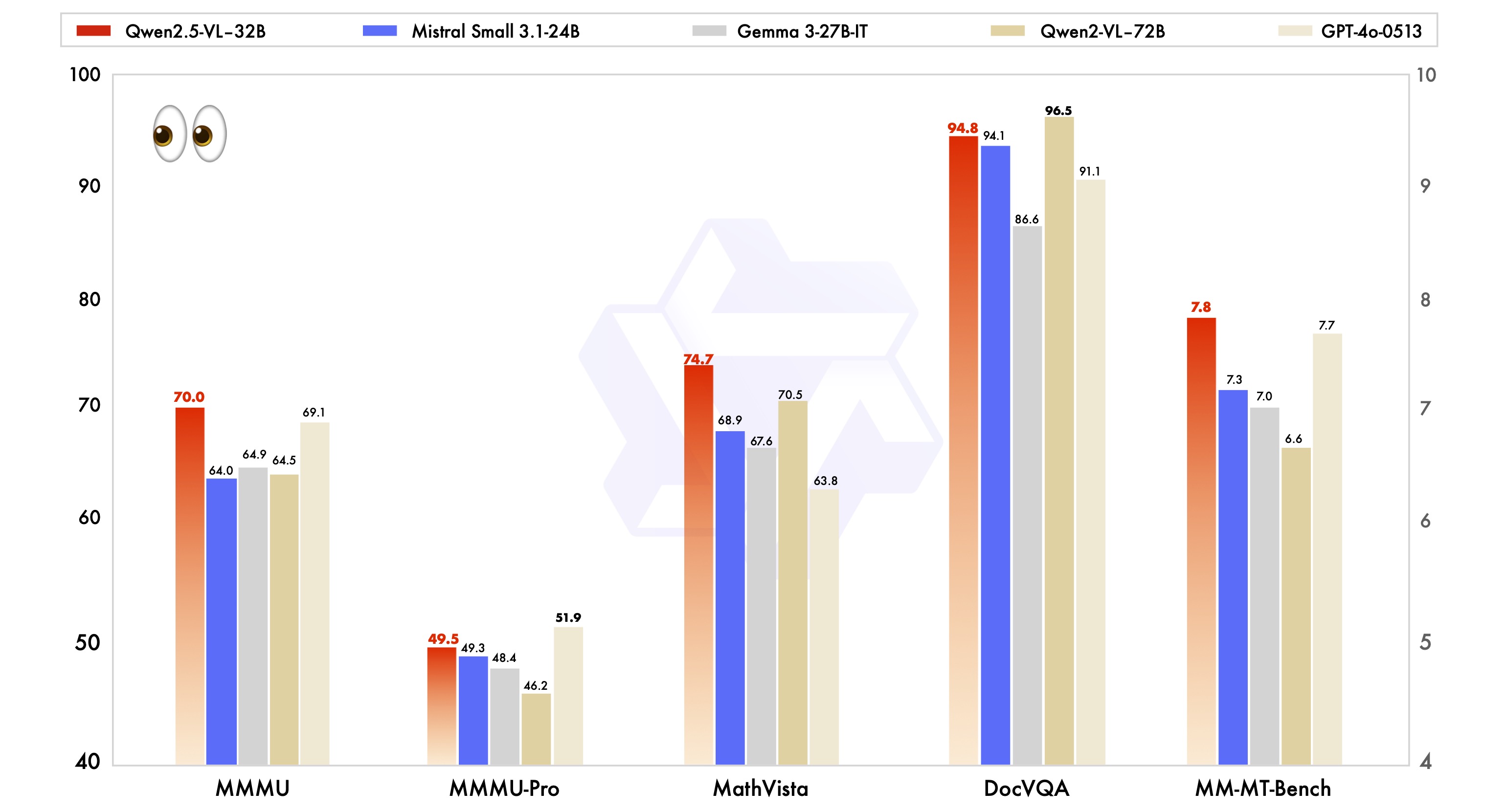
Qwen2.5-VL-32B 在 Qwen2.5 VL 基础上继续强化学习优化, 提升了复杂数学问题求解的准确性,回答规范性,以及图像细粒度理解与推理能力。
- 架构
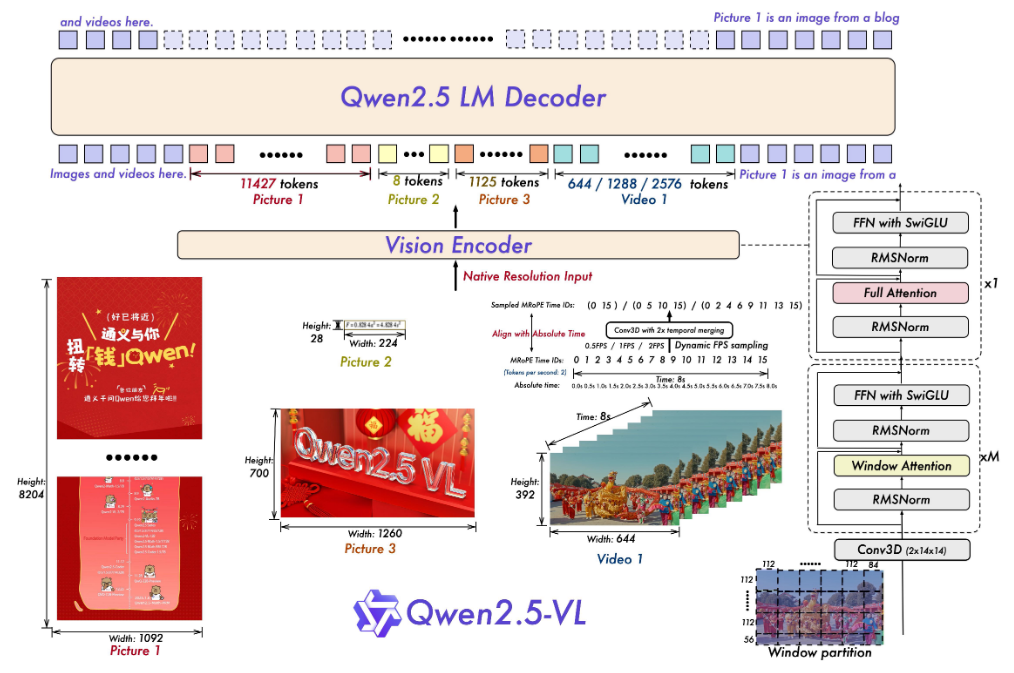
- LLM:Qwen2.5-VL 采用 Qwen2.5 LLM 预训练模型进行初始化的同时,将原本的 1D RoPE 改成了 Multimodal RoPE
- Vision Encoder:采用了重新设计的 ViT,并且从头开始进行训练。包括 CLIP 预训练,视觉语言对齐,端到端微调。
预训练量从 Qwen2-VL 的 1.2 T,便到了 4.2 T。
更多可以参考这篇文章的概括
QvQ - Qwen models for visual reasoning
博客: QVQ: 更睿智地看世界
huggingface:https://huggingface.co/Qwen/QVQ-72B-Preview
QVQ 基于 Qwen2-VL-72B 构建,当时在视觉理解和复杂问题解决能力上取得了一定的成果,但仍有一定的局限性。以下是部分 demo 展示。
QVQ 可以根据图片进行一些推理
后面推出的 QVQ-Max:有依据地思考 在理解和思考能力上有所提升,QVQ-Max 具备以下特点:
- 细致观察:抓住每一个细节 QVQ-Max 对图片的解析能力非常强,无论是复杂的图表还是日常生活中随手拍的照片,它都能快速识别出关键元素。比如,它可以告诉你一张照片里有哪些物品、有什么文字标识,甚至还能指出一些你可能忽略的小细节。
- 深入推理:不只是“看到”,还要“想到” 仅仅识别出图片里的内容还不够,QVQ-Max 还能进一步分析这些信息,并结合背景知识得出结论。例如,在一道几何题中,它可以根据题目附带的图形推导出答案;在一段视频里,它能根据画面内容推测出接下来可能发生的情节。
- 灵活应用:从解答问题到创作 除了分析和推理,QVQ-Max 还能做一些有趣的事情,比如帮你设计插画、生成短视频脚本,甚至根据你的需求创作角色扮演的内容。如果你上传一幅草稿,它可能会帮你完善成一幅完整的作品;上传一个日常照片,它可以化身犀利的评论家,占卜师。
根据官网的 demo ,QVQ-Max 包括了 thinking 部分的推理过程,支持多张图片同时推理。
Qwen2.5-Omni
博客:Qwen2.5 Omni:看得见、听得到、会说话、能写作,样样精通!
arxiv:https://arxiv.org/abs/2503.20215
Qwen 推出的端到端多模态模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音合成输出。
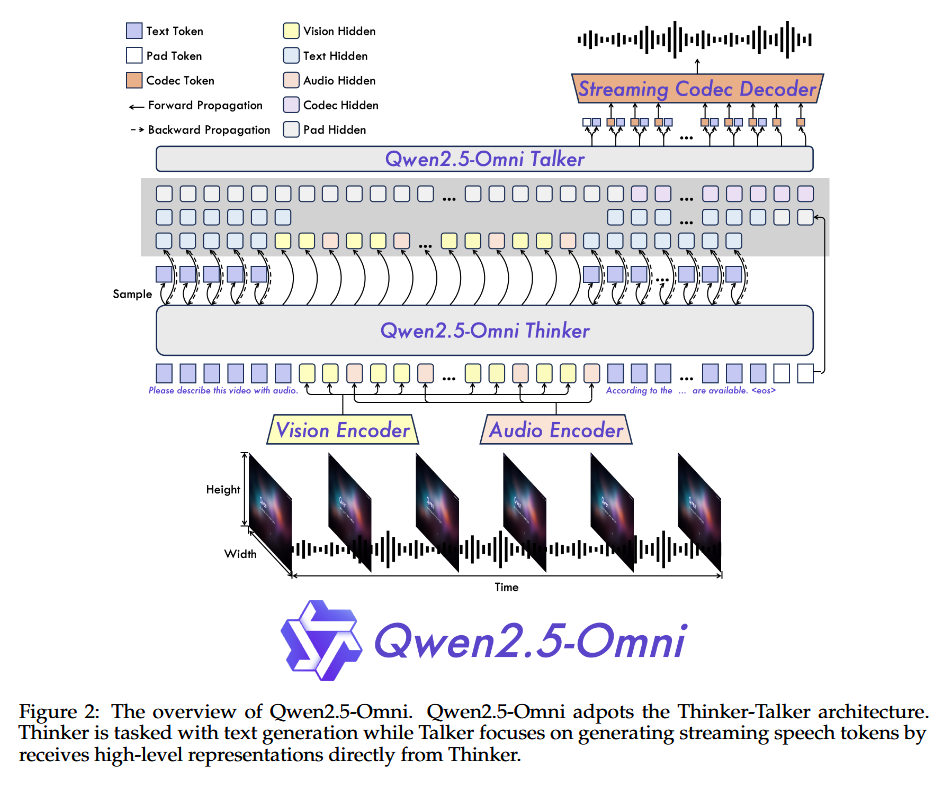
模型采用了 Thinker-Talker 的架构,LLM 用 Qwen2.5-7B,视觉 encoder 用 Qwen2.5-VL,音频编码器与 Qwen2-audio 一样用 Whisper-large-v3。
位置编码采用了 TMRoPE,将原始的 RoPE 分解成时间,高度和宽度。
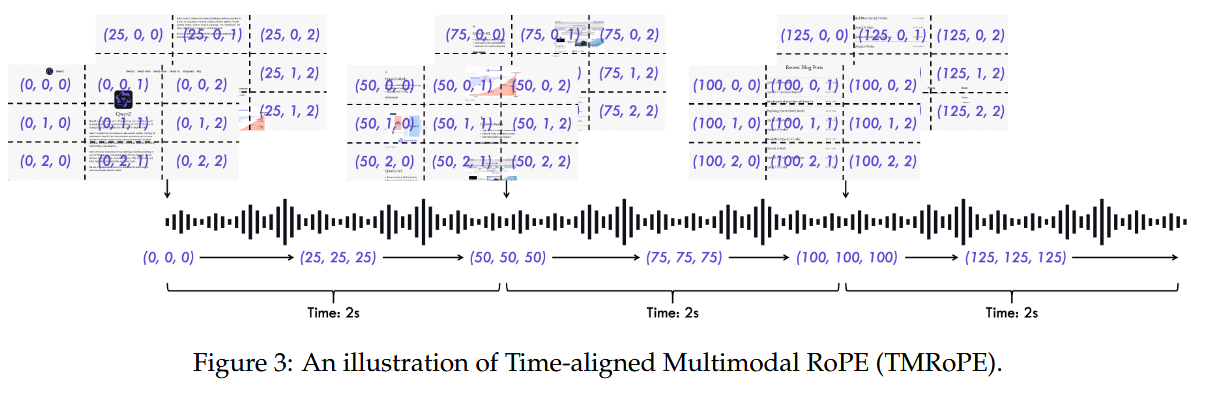
对于视频输入,为了同时处理视频和音频,相比于 MRoPE,加入了时间 ID temporal ID。
将视频与音频的表示按 2 秒为单位 切分。在每个 2 秒片段中,先放置视频帧的表示,再放置对应的音频表示。这样保证模型能在同一时间窗口内同时接收和理解画面与声音。
视频被视为一系列图像,帧与帧之间时间 ID 按实际间隔递增。音频按 40ms 切分位置,与视频的 temporal ID 对齐。当多模态输入同时存在时,每个模态的 position ID 编号在上一个模态的最大 ID 基础上递增,避免冲突。
文本和音频使用相同的 position ID,但音频额外加入绝对时间编码(每 40ms 一个时间 ID)。
图像和视频在 height 和 width 上有独立的 position ID,而视频的 temporal ID 会随着帧率动态调整,保证 1 个时间 ID ≈ 40ms。
在生成过程中,所有的文字内容都是由 thinker 生成,生成方式与大部分的 LLM 一样,talker 接受 text 对应 token 的 embedding,同时也接受 audio 或 视觉输入对应位置所生成的 representations。
- 后训练
后训练的 prompt template 如下
