机械学习|降维
线性回归基础数学。笔记思路源于 shuhuai-白板机械学习 系列教程。
降维
维度灾难
特征数量的增加并不能保证模型效果更上一层楼,大量的特征可能导致样本稀疏率的增加,进而导致过拟合。 在高纬度的情况下,样本之间的欧式距离趋向于无法区分大小:
从几何角度讲:
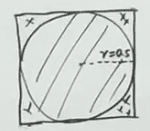
设二维空间下正方形边长为 1,则其内切圆半径为 0.5,因此球体的体积为 ,正方体体积为 1。当维度 增加时,内切超球体体积趋近于零。假设二维空间下的正方体四个角落对应四个类别的样本。在高维空间下,样本稀疏性变大,分类变得困难。
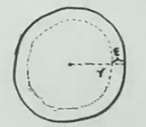
设外圆半径 ,内圆半径为 。 在高维情况下,外圆体积为 ,中间圆环体积为 。当 趋近于无穷大时,中间环的体积趋近于 ,内圆体积趋近于零。因此,高维情况下,环形带占据了几乎整个外圆,就像大脑一样,所有知识分布在大脑皮层上。因此在平面或三维几何上的一些直觉,在高维空间上是不起作用的。
为了解决过拟合,通常使用个的是增加数据量量、正则化和降维。L1 和 L1 两种正则化方法,本质也是为了降维:增加系数惩罚,使得 趋向于零,以此消除一些特征。
样本均值与样本方差的矩阵表示
样本均值表示为:
样本方差表示为:
此处 为 的单位矩阵,令 为 (centering matrix)
H 矩阵有以下性质:
因此
PCA
主成分分析主要思想为:
一个中心: 对原始特征空间的重构,将相关的特征转为无关的特征。将特征空间变成一组相互正交的基。
两个基本点:
- 最大投影方差:找到投影轴,使得投影后方差最大。
- 最小重构距离:以最小的代价将投影后的数据重构回去。
数学推导
从最大化投影方差出发:
- 数据中心化
- 将 投影到
假设 , 即
projection ( 为 与 的夹角)
又因为
所以 projection
由于 已经中心化, 其均值为 0 , 因此投影方差为
- 目标函数
其中 为协方差矩阵 , 因此:
使用拉格朗日乘子法:
从公式可以看出, 为 的特征向量, 为对应的特征值。 这也解释了为啥 PCA 要算特征向量与特征值。
从 SVD 看 PCA
将 左乘中心矩阵 进行中心化后进行奇异值分解:
其中 为 , 为 且
结合第二节的结论:
因此 是 的特征向量,中心化 X 后的 SVD 结果等价于上一节 PCA 的结果。
PCA 步骤
- 数据中心化
X -= mean(X) - 计算协方差矩阵
- 计算特征向量,特征值为 ,则:
L_1 = (S.trace() + np.sqrt(pow(S.trace(),2) - 4*np.linalg.det(S)))/2
L_2 = (S.trace() + np.sqrt(pow(S.trace(),2) + 4*np.linalg.det(S)))/2
# S is the Cov matrix of X
- 特征向量计算 (Cayley-Hamilton theory)
是 维的单位矩阵;;
A1 = S - L_1 * np.identity(2)
A2 = S - L_2 * np.identity(2)
E1 = A2[:,1]
E2 = A1[:,0]
E1 /= np.linalg.norm(E1)
E2 /= np.linalg.norm(E2)
- 最后,选择前 k 个维度作为主要成分。特征值反应了对应维度的重要性