SAS 学习笔记
SAS
基础
变量数据类型:定义方式为:var_name type; 其中 type 包括:
- 数值型: 不分整数小数
- 字符型:
$10。10 表示最大字符数量。最多支持 32767 字符。 - 时间型:
DATA11等
DATA step
基础创建,读取,修改数据
处理方法是逐行处理,相当于定义一个函数,对数据集逐行进行处理。
/*从第三行开始读到 5 行*/ DATA DB; INFILE "PATH TO FILE" FIRSTOBS=3 OBS=5; INPUT "@1 COL1 $10. COL2 3.1 DATE MMDDYY10." /*如果是字符串类型,后面要加字符串, COL2 占用 3 个字符,包含小数点后 1 个数,但是如果出现一个没*/ /*@ 说明从第一个列开始都*/ LABEL ReceiveDate="Date order was received" /*给 col name 换标签*/ Zone = 14; /*直接生成一个新的 COL*/ avg = MEAN(COL1, COL2) INPUT X @; /*我们先读入 x 这个 col,*/ INPUT Y; /*这时候我们就能读入 X Y 两列数据*/ INPUT Z @@; /*记录永久保留,知道被覆盖*/ RETAIN record_max; /**/ MAX_VAL = MAX(record_max, COL2);
SAS 是每行读取的,因此使用 RETAIN 相当于创造了一个临时变量,而不适用 RETAIN 相当于直接创造了新的 col。
读取时候可以在 input 加入 @sym 来提取复杂语句,如下面提取的目标为 123[2022-01-01 -000] GET /mnt/c/log.txt:
DATA DB;
INFILE "PATH TO FILE";
INPUT @'[' Lastdata DATE11. @'GET' File :$20.;
其他输入方式请查看搜索引擎。
PROC step
- 进行复杂操作 相当于函数
操作界面
SAS 带有自己的软件界面,在软件中点击 run submit 就可以提交了。左边是逻辑库(数据文件夹),右下角写代码,右上看日志。
数据导入
一般如果前几行缺失的话,该列会默认识别成字符型。可以在前几行添加一些数字性数据,然后导入后删掉这些行。
永久数据库链接
sas 逻辑库相当于文件夹,用于储存文件。
libname sasdb "path/to/data_dir"
DATA sasdb.db_name
在逻辑库中的数据库名称叫做 sasdb
import 导入
除了用 data 导入常用数据库,也可以用 import
Proc import
DATAfile="pathname"
GETNAMES=NO /*不讲第一行作为 col_name*/
out=sasdb
DELIMITER="," /* 分割符 */
dbms=identifier replace;
Run;
选取部分 col 读入,输出一个数据集时候,效率高:
DATA NEWDB;
Set rawdb(keep/drop=col_name);
Run;
以下能够输出到多个数据集中,但内存中操作的是整个 RAWDB 数据集。
DATA NEWDB1(keep/drop=col_name)
NEWDB2(keep/drop=col_name);
Set rawdb;
Run;
数据选择
Data 语句指定了新数据集名,set 指定要读取的老数据集名。如果不想创建新的,则也可以在 data 中指定老数据集。
DATA NEWDB;
SET OLD_DB;
软件直接导入 View table 窗口
一般如果前几行缺失的话,该列会默认识别成字符型。可以在前几行添加一些数字性数据,然后导入后删掉这些行。
数据操作
变量
如果我们执行这样的操作:
data c;
set b;
new_col+col;
format new_col;
run;
sas 相当与执行了以下 python 操作:
c = new_data()
b = load_data()
for row in b:
col1, col2, col3 = b.columns
if new_col:
new_col += col1
else:
new_col=0
c.append(col1, col2, col3,float(new_col)) # 这一布会添加所有中间出现过的变量
对与 b 表格中的 cols 变量,他会覆盖之前定义过的所有同名变量。
对于中间我们自定义的其他变量,它会保持住上次更新的值。
所有中间变量都会被统一默认 output,当然我们可以自定义 output。
运算符号
**
*
+
-
= /*等于与复制语句有时候很相似*/
^=, ~=
>=
& and
|,! OR
^ not
max
min
|| 字符链接操作
条件运算
data a c;
set b;
if gender=1 then do;
output a;
end;
else if gender=. then do;
tg='gender_missing';
end;
else do;
output c;
end;
Run;
部分逻辑
COL IN('TARGET','TARGET')
Year<1999
循环
DO I = 1 TO 5;
CODE.
END;
日期操作
ARRAY
创建 store 数组,储存四个列的变量
ARRAY store(4) Macys Penneys Sears Target;
/*或用 -- 省略中间列*/
ARRAY store(4) Macys -- Target;
筛选
PROC PRINT DATA="XXX"
WHERE Genro="target genro"
打印
PROC PRINT DATA="XXX";
WHERE Genro="target genro";
LABEL NEW_COLNAME="A LONG COL NAME";
BY COL_LIST; /*筛选 col*/
ID TARGET_ID_LIST; /*筛选 row*/
FORMAT Last_Date DATE9. /*格式化输出*/
FOOTNOTE "F = FRANCE";
其中格式化输出支持自定义格式化。
打印统计指标,包括 mean, std dev, min, max 等值:
proc MEANS DATA= SALES;
BY Month;
VAR TARGET_COLS;
TITLE "TITLE OF PRINT TABLE";
可以使用自带功能打印简单报告
proc report data=xxxx;
options;
计数
对变量进行统计计数,支持单/双变量计数。
PROC FREQ DATA=ORDERS;
TABLES WINDOW WINDOW * COFFEE
RUN;
代码告诉 SAS 打印两个表,一个是 one-way 的频率表 WINDOW,一个是交叉表。交叉表的每个小方格内,SAS 打印了频数、百分比、行百分比和列百分比。左边和右边是累积百分比。注意计算频数时没有考虑缺失值
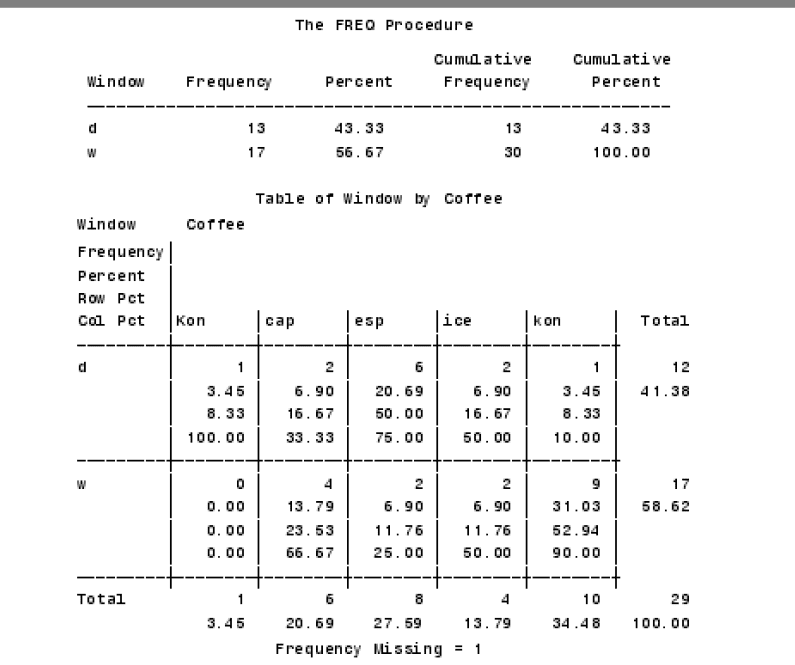
如果要打印三个变量的频率:
proc tabulate data=boats;
class col1 col2 col3;
table col1, col2, col3;
RUN;
其中根据 col1 值打印多个双变量频率表。
除了打印计数之外,还可以打印其他计算结果。 美化输出结果等。
排序
PROC SORT DATA=MESSY OUT=NEAT dupout=dupdata NODUPKEY;
BY State DESCENDING cITY
将 DESCENDING 加在要降序的变量前面。
缺失值比任何值都小。
重复的数据将会输出到 dupdata 中
排序后,默认可以使用 FIRST.COL 和 LAST.COL 提取最小和最大值。因为他们直接指向了第一 row 读取的数和最后一 row 读取的数。
分组
拼接数据集
可以使用 set 实现拼接。SET 语句是一次一个变量地,将一个数据集放入数据步中予以分析。
根据 row 的方向拼接;
DATA NEWDB;
SET OLD1 OLD2;
PROC PRINT DATA=NEWDB;
RUN;
合并数据集
合并前需要 sort 合并的 key
PROC SORT DATA=DB1;
BY col1;
PROC SORT DATA=DB2;
BY col1;
DATA newdb;
merge db1 db2;
by col1;
如上,相当于 db2 向 db1 合并。(db1 为左表)
可以通过 in= 方法来调整合并时候,左右两个表不同的 row 如:
DATA BOTH;
MERGE STATE (IN=INSTATE) COUNTEY (IN=INCOUNTRY);
BY COL1;
IF INSTATE=1;
当前 row 的 col1 在 STATE 数据集存在时,INSTATE=1; MERGE 会遍历所有出现过的 row;
更新数据
根据 col1,将 db2 中非空数值更新到 db1 中
data db1;
update db1 db2;
by col1;
run;
位测试:
if a='..1.000'b than do;
操作语句
MEAN(OF COL1 - COL9)
MEAN(COL1, COL2, COL3)
输出 ODS
ODS 是输出必须经过的一个环节。ODS 支持很多输出美化配置
打印中间变量
ODS TRACE ON;
THE DATA YOU WANT TO PRINT
ODS TRACE OFF;
或输出单一变量
ODS SELECT MEANS.byGroup1.Summary
输出到 HTML
ODS HTML OPTIONS;
data ...
proc ...
ODS HTML CLOSE;
options 需要指定一个路径。HTML 支持很多输出美化。
输出到多个表
data db1 db2;
set rawdb;
if col1=1 then output db1;
else output db2;
run;
output 用于控制合适将观测值写入到 SAS 数据库中。如果数据集中没有 OUTPUT 语句,则暗含在结尾,放置了 output 之后,则结尾的就不再暗含存在。当 SAS 出现 OUTPUT 语句时,则写入一个观测值。
DATA DB1;
DO X = 1 TO 6;
Y=X**2;
OUTPUT;
END;
RUN;
每一次 output 就时一行,output 时候将 output 所有记录的 cols;
输出到文件
PROC EXPORT DATA=data-set OUTFILE='filename';
宏
宏与 C 中宏变量相似,在编译时候被替换。
使用宏指令之前必须将宏系统选项打开,尽管有时默认是打开的。可以用下面代码查看是否打开: PROC OPTIONS OPTION=MACRO; RUN;查看日志,如果看到 MACRO,则打开了;如果看到 NOMACRO,则没有打开。
定义宏变量
%LET iterations=10;
%LET country=New Zealand;
当赋值字符串时,不需要加引号 。除非在开头和结尾有空格,否则从等号到分号的全部内容都是变量值。
引用时候使用 &
do i = 1 to &iterations
可以将一段代码定义成宏:
%MACRO SAMPLECODE;
PROC SORT DATA=DB;
CODES;
%MEND SAMPLECODE
调用时候直接 %SAMPLECODE
可以添加参数
%MARCRO SELECT(X=, Y=);
PROC SORT DATA= DB;
BY &X;
WHERE ID="&Y"
%MEND SELECT;
使用:
%SELECT(X= COL1, Y=TARGETID)
宏中条件
%IF condition %THEN action;
%ELSE %IF condition %THEN action;
%ELSE action;
%IF condition %THEN %DO;
SAS statements
%END;
其他
其他函数
REG # 支线回归
PRINCOMP # PCA
GLM # 协方差分析
ANOVA # 方差分析
如简单的回归
PROC REG DATA=DB;
MODEL Y=X;
PLOT Y*X;
RUN;
根据 X 预测 Y
能够添加缩写,自动指代到