回忆 Scaling laws(2020-24)
相关信息
部分 scaling laws 回忆
Scaling Laws for Neural Language Models
2020 年 openai 发布了文章 Scaling Laws for Neural Language Models ,其中提到了 scaling laws。一开始的 scaling laws 针对的是 Transformer models,但后续一些讨论更倾向于自回归类型(做 NTP)的模型,文中 summary 提到了最初 scaling laws 的几个点:
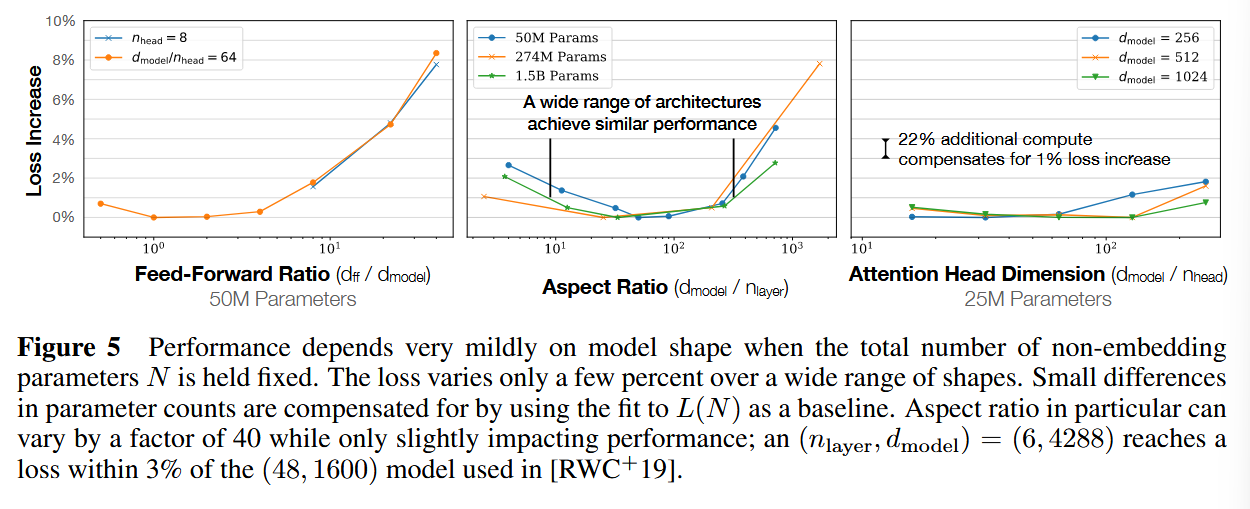
- Performance depends strongly on scale, weakly on model shape
模型的性能更多取决于 参数量 N( 不包含 embedding ), 数据数据量 D, 训练花费的算力 C FLOPs 。其中
相关信息
20 年的 OpenAI GPT 系 列模型架构上变化的确很小,但至今前言 LLM 的架构(如 MoE,attn 之类的)的确与 20 年相比较有较大的改变。此处的 weakly 指的是 n_heads,n_layers,d_ff。
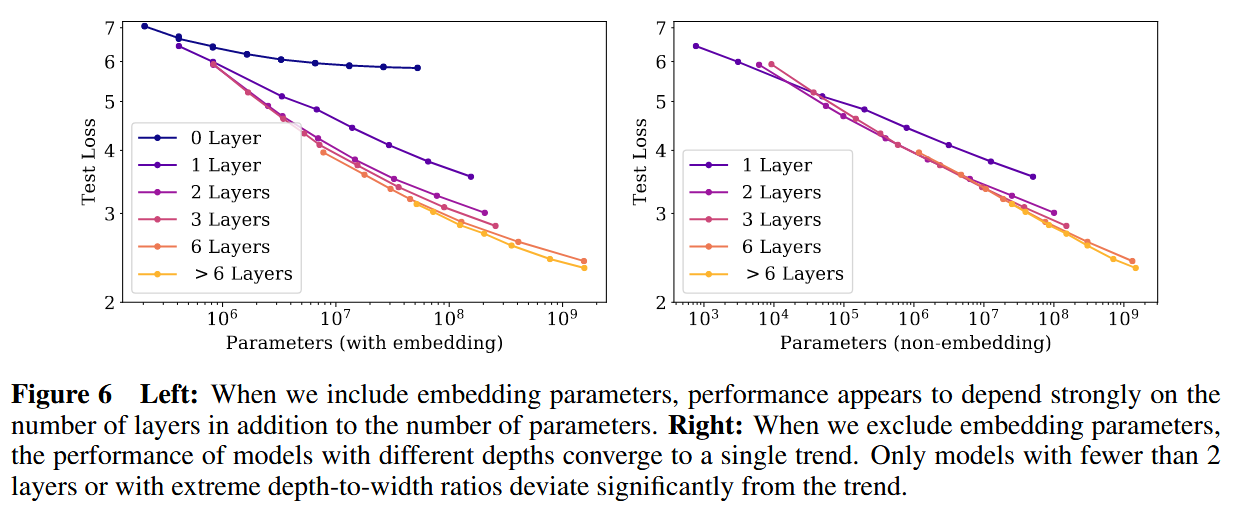
non-embedding 是很关键的,如果包括了 embedding,那么曲线就是下面这个样子:
- Smooth power laws
该处说明下图中的 3 个公式,都是通过拟合得来的:
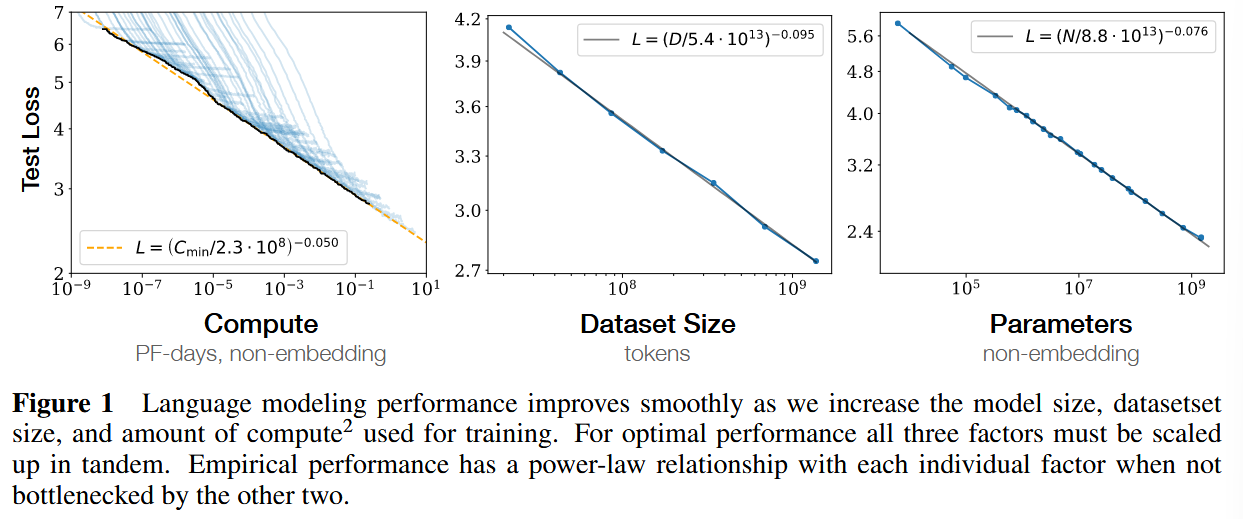
论文后续也指出,值得关注的不是某个常数具体是多少,而是幂律形式本身,以及各个指数的大小量级。
当训练的预算固定时,模型大小、最优 batch size、训练步数、数据集大小都会有一个最优解。
- Universality of overfitting
此处的 scaling law 把 Loss 分成 N 和 D 两部分,然后用公式进行拟合得到具体超参,对应的结果如下:
此处的 overfitting 指代的是由于数据集的限制(信噪比等)而产生的 Loss,也就是 D 的部分。Loss 同时由 N 和 D 决定,模型变大的时候,数据量也应该变大,假设 overfitting 情况下,loss 的 variation 不应该超过 0.2 时,初步估计的 关系大概是:
- Universality of training
通过模型训练早期的 training curve,就能预测长时间训练后的情况。关系拟合结果:
例如 warm up 之后,已经通过 Batch size 训练了 个 Step,那么可以通过上面的十字计算 ,然后接下去可以预测大模型训练的 Loss:
训练时候的 Batch size 与 Loss 相关拟合结果:
相关信息
随着训练推进,数据中的“信号”和“噪声”比例变小了。所以需要增大 batch size。
- Transfer improves with test performance:这种模式下训练得到的模型,泛化能力是有的。
- Sample efficiency: 模型越大,达到同一个 loss 所需要的 token 数量越少。
- Convergence is inefficient: 固定 compute 下怎么最优分配模型、数据和训练步数。
相关信息
Compute-Optimal Frontier 这部分在这几年的 LLM 训练中也有各式各样的讨论。
本文主张固定算力时,把一个小模型训到收敛,往往不是最优。训练一个相对大的模型,即便它没有收敛,也可以比小模型效果更好。最优模型大小与 Compute 的关系拟合如下:
最优训练 Step 与 Compute 关系:
最优 loss 随 compute 进行缩放,也是幂律关系:
文中提到一个内部矛盾:
避免 overfitting 需要 ,但 compute-efficient training 只给出 ,所以这套趋势不可能无限成立,或者说需要更多解释。
通过 C 计算最优参数:
| Compute-Efficient Value | Power Law | Scale |
|---|---|---|
| (N_{\text{opt}} = N_e \cdot C_{\min}^{p_N}) | (p_N = 0.73) | (N_e = 1.3 \times 10^9) params |
| (B_{\text{opt}} \approx B_{\text{crit}} = B_e \cdot C_{\min}^{p_B}) | (p_B = 0.24) | (B_e = 2.0 \times 10^6) tokens |
| (S_{\min} = S_e \cdot C_{\min}^{p_S}) (lower bound) | (p_S = 0.03) | (S_e = 5.4 \times 10^3) steps |
| (D_{\text{opt}} = D_e \cdot C_{\min}^{p_D}) (1 epoch) | (p_D = 0.27) | (D_e = 2 \times 10^{10}) tokens |
Scaling Laws for Autoregressive Generative Modeling
问题:
这些 scaling laws 是否适用于 所有数据模态 ?
训练 loss 的改善,是否真的能转化成 更好的表示 和 下游能力 ?
我们能不能判断某个任务什么时候已经接近“天花板”,继续 scaling 的收益会变小?
这些规律为什么这么平滑、这么精确,甚至看起来有些“普适”?
结论:
- 通用的 power law
所有 domian 都能很好地描述以上这个 scaling law,即便在 reducible loss 很小的区域。
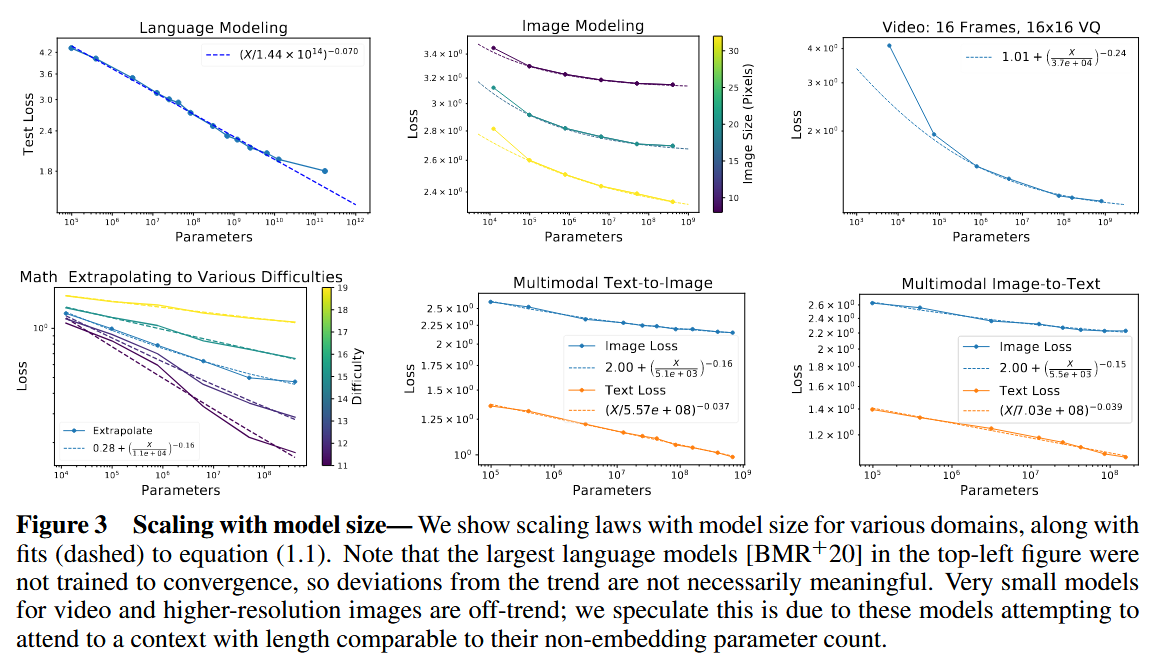
- 固定算力下的最优模型大小
与之前的 scaling law 结论相似,在给定算力下,总有一个最优的模型大小解。作者把训练 compute 近似写成:
其中 是参数量, 是训练 token 数。各个 domain 中,最优 achievable loss 随 compute 增长也 obey power-law + constant 。更重要的是,最优模型大小 obey:
并且这个指数在不同模态里都非常接近。 但在更大规模下,优化效率的变化很可能会让 compute scaling 开始偏离原来的幂律。
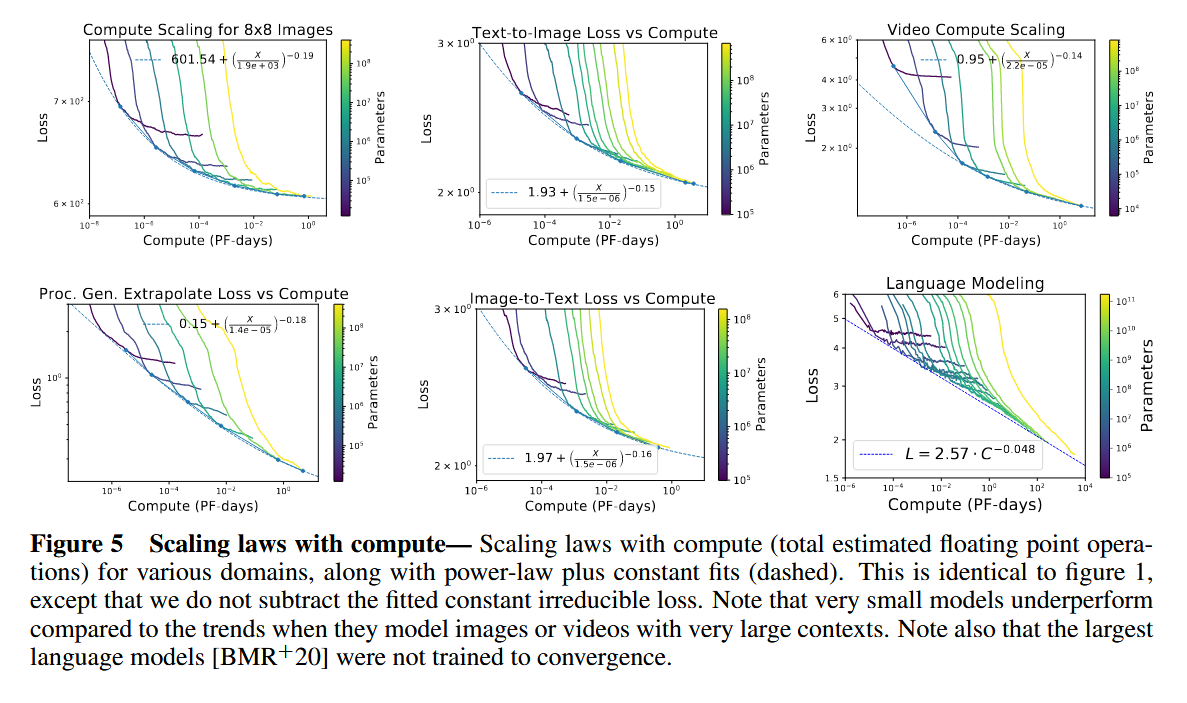
- 不同模态有不同的最优 aspect ratio
不同模态有各自最优的 transformer 纵深比,大部分模态都适合比语言模态更深的 transformer 网络。
不同模态下的 AR 和发现
图像/视频部分的特别发现
- 生成式图像模型在做 ImageNet 分类微调时, 分类 loss 和 error rate 也会平滑 scaling ,即便生成 loss 已经接近 irreducible loss; 这说明“生成 loss 快到头”不代表表示学习价值就到头了
- 单张图片的 loss,也会和整体平均 loss 一样随模型大小平滑变化。
- 不同图像分辨率有不同的 scaling exponent 和 irreducible loss。
- 视频中,loss 还会和 frame index 有关系。scaling law 不只适用于整段视频平均 loss,也适用于具体 continuation 目标。
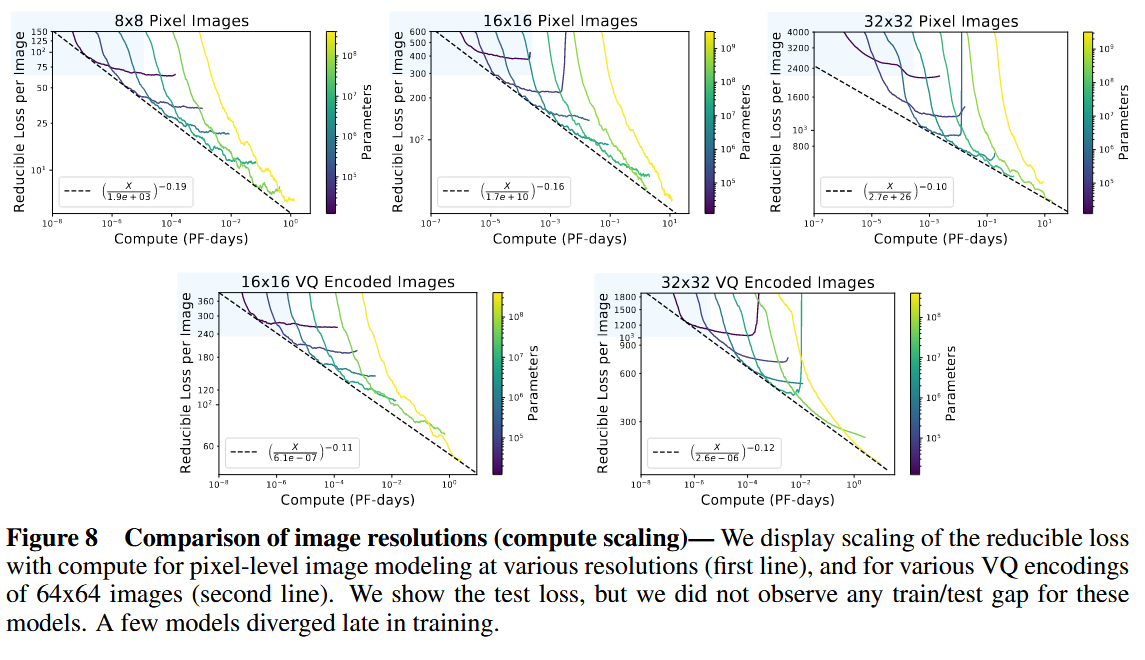
多模态部分的特别发现
- 对于图文多模态,作者说他们考察了 caption 和 image 之间的互信息以及文中定义的 information gain,mutual information 和 infogain 随模型大小的变化大致满足:
- 并且这两者也会随模型大小平滑 scaling。但这些模型的 infogain 随 的增长 非常缓慢 ,作者还借此重新讨论那个很有名的问题: “一张图值一千字吗?” (论文中通过文字和图片的 mutual information gain 大小来判断)
- 这其实非常有意思,因为它把 scaling law 从“模型训练规律”推进到了“不同模态的信息量比较”。
数学题部分的特别发现
- 在程序生成的数学问题上,作者发现:模型对更难题目的 外推能力 ,主要取决于它在训练分布内题目上的表现,而不是额外由模型大小直接决定。换句话说:更大模型通常表现更好;但“大”本身不自动带来某种额外的“强泛化魔法”。
- 这句话很重要。它其实是在提醒读者,不要把 scaling law 神化成“模型越大,就会突然拥有分布外推理能力”。在这组实验里,更像是: 分布内更强,所以外推也相应更强 。
图像在 AR 模型中的处理
- 直接把图像按 raster order 展开成 RGB token 序列
- 或者先用 VQ-VAE 编码,再预测离散 code 序列。
视频在 AR 模型中的处理
- 每帧先做 VQ 编码
- 每帧 256 个 token
- 一共 16 帧
- 所以总 context length 是 4096 token
Training Compute-Optimal Large Language Models
文章观点:在固定训练算力下,最优策略不是一味把模型做得更大却锁定 token 数量不变,而是要让模型参数量 和训练 token 数 一起增长,并且大致同速增长
论文通过大量训练来拟合最优 N 和最优 D 的曲线。
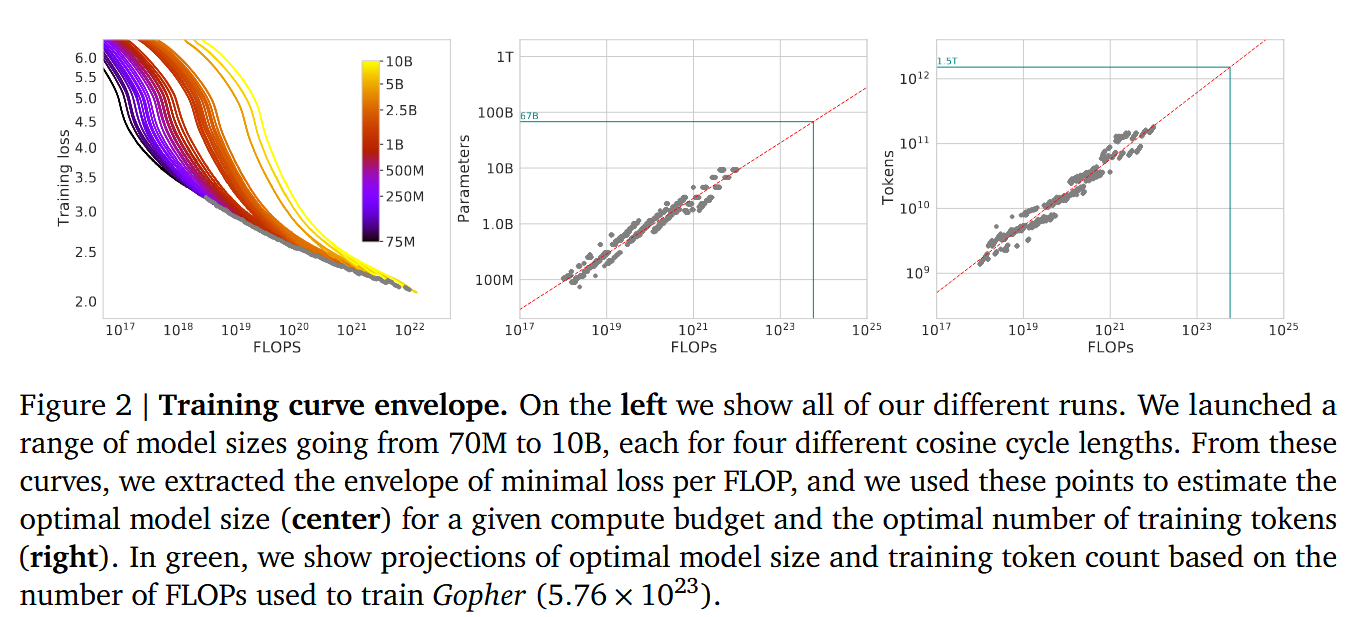
文中也对固定 C 下,不同 N 和 D 的训练曲线进行了研究:
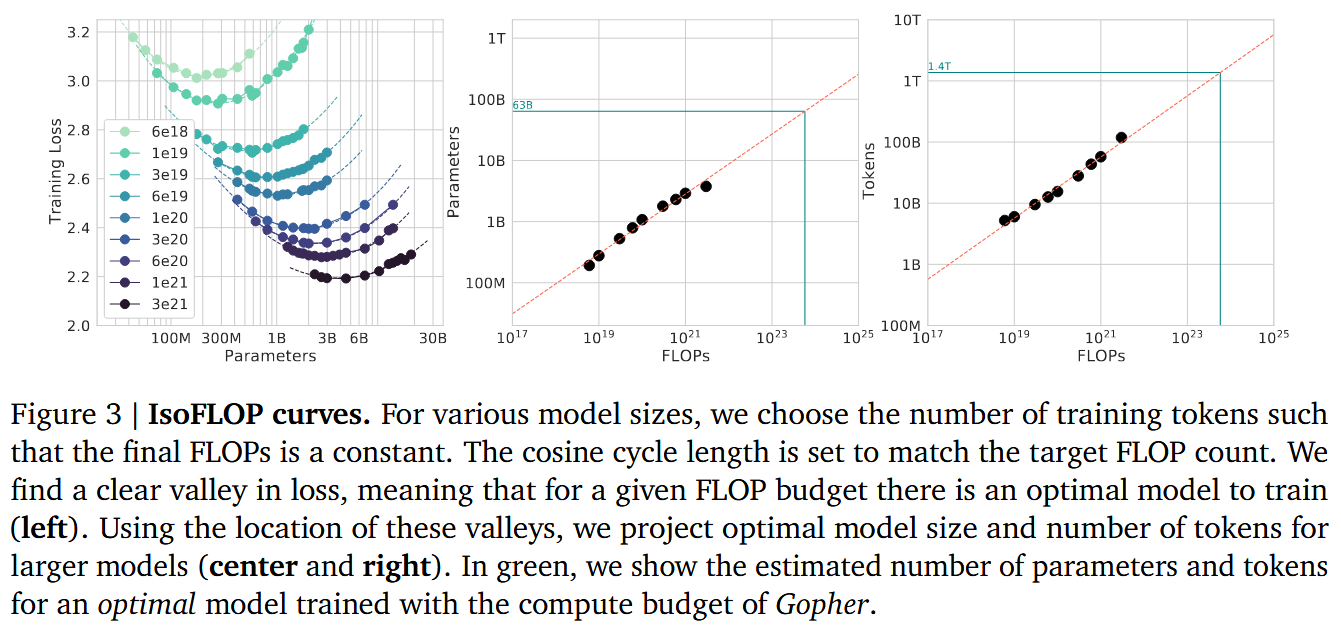
除此外文中也对 loss 进行建模进行了验证,结果与上面 2 个实验匹配。三种方法最后都得出同一方向的结论:
最优模型大小约为
该论文也在同样的 FLOPs 下面训练了 2 个不同大小的模型 Chinchilla 70B(1.4T token) 和 Gopher 280B,然后发现 70B 模型在各个测试任务上的表现超过了 280B 模型。