论文笔记|句向量生成于匹配
概述
语义相似度匹配大致分为孪生网络模型和交互式模型。孪生网络模型主要思路在于先分别获得两个句子的表征,而后通过其他距离指标判断句子的语义相似度。部分学者也将 孪生网络 称为 双塔模型 、 “暹罗”架构 等等。而交互式模型则是将两个不同的句子的中间编码进行交互,直接通过深度学习模型计算出相似度,而非采用距离指标进行判断。
该任务下,常见的数据集有 STS、SICK 等。
paper with code - 文本语义相似度 benchmark
孪生网络模型
孪生网络模型的重点在于,如何对单个句子进行编码。
无监督
Tf-idf
tf-idf 是常用的文本表征方法,主要思想是以下公式:
其中, 为超参,用于控制句子表征分布的平滑程度,通常为 1(当然很多地方只对分母添加平滑因子)。此外, TF 项也能够进行归一化,常见的归一化方案如,除以文档全部单词数量等。
以 sklearn 为例,sklearn 中采用 k==int(smooth_idf) 进行平滑控制。采用 l1 或 l2 来进行归一化。如何配置 TF-IDF 的超惨,也成为了一个玄学。
部分学者会在判断文本相似度的时候采用 TF-IDF 相似度:
即采用用户问题(query)中的每一个词,来根据文档 分别计算对应的 TF-IDF 值后求和。个人认为应该对 query 单独计算 TF-IDF 向量后,在于文档 d 的 TF-IDF 向量求距离,因为这样不会遗漏 query 中每个单词的 idf 权重。
BM25
输入:检索语句 Q 与目标文档 d; 输出:query 与文档 的相似度评分
BM25,可以看做是 TF-IDF 的优化版。用来评价搜索词和文档词之间的相关性的算法,基于概率检索模型提出,可以用来做召回
query 与文档 评分计算方式:
将 切分为单词
每个单词对应权重 ,此处 idf 与 上节中(TF-IDF)的 IDF 部分相同
IDF 公式有许多变种 ,BM25 常用的 为
单词 与文档 相关性 的计算: 为 在文档 中的词频,为 在 query 中的词频。=当前 doc 长度是超参,通常为 。
K 越大表示 d 文档的长度越长,所包含的信息可能就越多。
k1 越大,我们越看重单词在文档 d 中词频的影响。k2 越大,越看重单词在 query 中的词频。
从 BM25 评分公式来看, 可以分为单词 与文档 d 以及 query 的评分两个部分的乘积。因此如果将 Tf-Idf 的 TF 项改为 ,那么 采用 Tf-Idf + cos 相似度计算得来的评分,将于 BM25 相近。
WMD
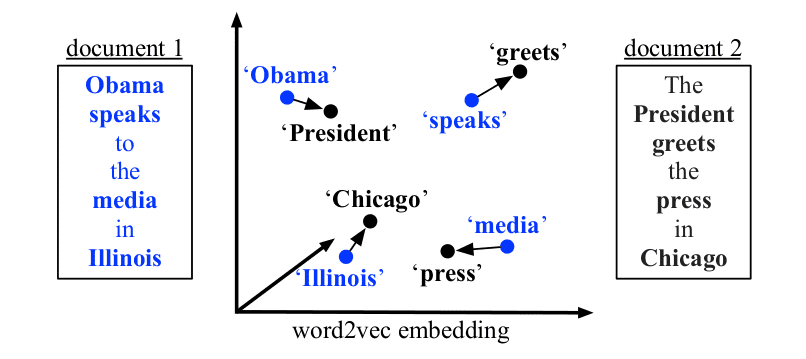
求句子转换之间最小的距离(将句子 A 中的每个词通过词向量移动,转换成为句子 B 的最小总距离。)。 WMD 的计算依赖于单词词向量 ,因此我们需要基于 Word2vec 以及一个 vocabulary 来计算 WMD(可以考虑 faxttext 等分词算法来减少 OOV 问题的出现),那么可能需要进行停用词去除等 Word2Vec 需要的操作。一些缺点是:WMD 只考虑可一一对应关系,没有考虑词与词之间多多对应的关系。网友论文笔记
其中, 为一个文档中第 i 个词的 nBOW(Normalized Bag-of-words)表示。 为该词在该文档中出现次数。
优化方案:
Word centroid distance
通过两个文档词向量中心的距离来计算文档距离下限。
relaxed word moving distance
保留 WMD 其中一个限定条件
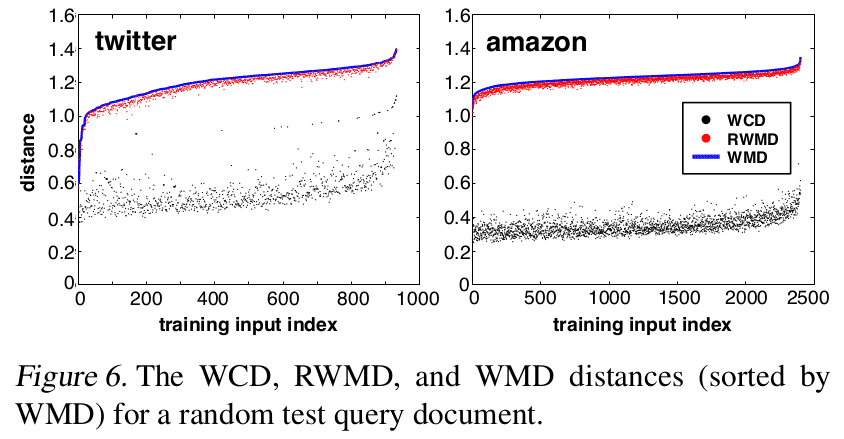
实验表现 WCD 求得的边界比 RWMD 差距更大。
通过 WMD 计算 KNN 时候,可以用 WCD 进行粗排,而后进行精排
代码:gensim
from gensim.similarities import WmdSimilarity
class WMDRetrievalModel:
def __init__(self,corpus,gensim_model_path):
Word2Vec_model = Word2Vec.load(gensim_model_path)
self.wmd_similarity = WmdSimilarity(corpus,Word2Vec_model)
def get_top_similarities(self,query,topk=10):
sims = self.wmd_similarity[query][0:topk]
return sims[0][0],sims[1][0]
有监督
早些年头的论文,大多数关注与 Word Embedding + 各种编码器+各种距离衡量方式进行文本表征计算以及文本匹配。
包括:
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
Applying Deep Learning to Answer Selection: A Study and An Open Task
Siamese Recurrent Architectures for Learning Sentence Similarity
Skip-Thought Vectors
Learning Distributed Representations of Sentences from Unlabelled Data
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
等等。
近些年,学者们似乎都关注在了基于预训练模型+监督学习方法的语义匹配任务上。以下对 SBERT, BERT-FLOW, BERT-Whitening, SIMCSE 等基于 BERT 模型的论文进行笔记总结。
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
SBERT 提出对 BERT 进行额外的句向量生成任务训练,训练方法如下:
采用双塔结构,对两个句子经过 bert 之后的 embedding u 和 v,而后实验了不同的优化指标:
- 分类任务指标:
- 回归任务指标:直接对余弦相似度进行优化
- Triplet 优化任务:经典的孪生网络训练目标。每组训练集需要与 archor、正素材和反素材。
论文中通过各种实验,发现了以下结论:
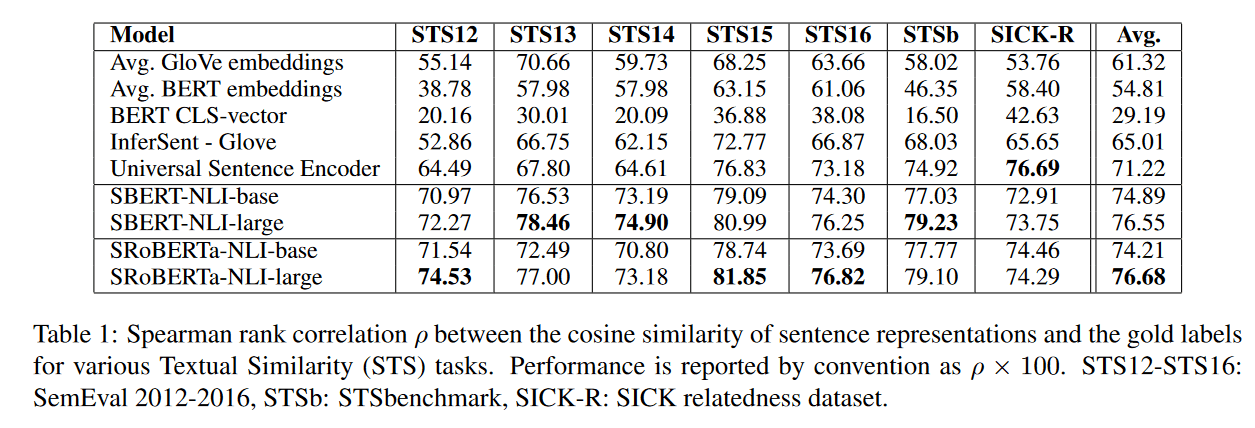
如果只是用预训练后的 BERT 对句子进行 embedding,而后通过 余弦相似度 等方法进行语义匹配的话,效果还不如 GLOVE 来的好。
采用 BERT 的 mean POOLING 效果会比 CLS 好点。
微调时,想对与其他的数据集,在 NLI 上微调,能够带来额外 1-2 个百分点的提升。
BERT-Flow: On the Sentence Embeddings from Pre-trained Language Models
论文开始分析了 BERT 句向量表现差的原因:
- 词频不均匀,导致了各向异性(anisotropic)的存在
- 如下图,实验发现,高频词在表示空间上的距离,要远小于低频词。词频词分布十分稀疏,导致了余弦相似度等距离计算方式无法区分他们(有点维度灾难的感觉?)。
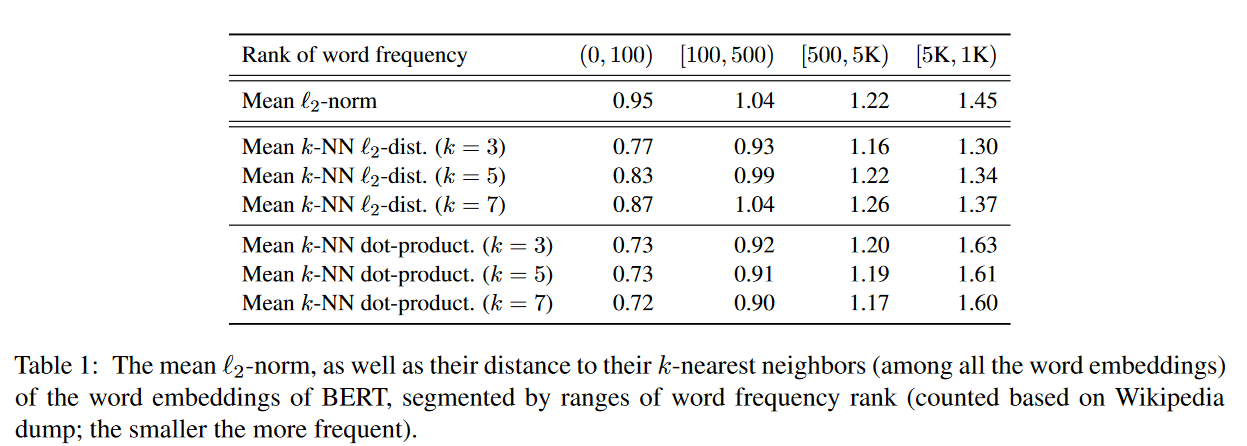
(图:bert 预训练模型的 embedding 间距离,与其对应词频的关系)
BERT-flow 提出,通过 flow-based 的生成模型,将句子表征映射到高斯分布的均匀空间内。效果比 sentence BERT 好 3-4%
在微调时,冻结 BERT 权重,仅对 FLOW 模型进行更新。
关于 FLOW 模型相关阅读:
BERT-Whitening: Whitening Sentence Representations for Better Semantics and Faster Retrieval
苏神在博客中对该论文进行了概述,相对于 FLOW 的复杂计算,改论文采用了简单的线性变换来改善了 BERT 词向量分布问题。
参考链接:你可能不需要 BERT-flow:一个线性变换媲美 BERT-flow
文章指出,预先相似度公式 仅在“标准正交基”下成立,“坐标依赖于所选取的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样”。因此文章猜测 BERT 向量效果不好的原因在于他们所属的坐标系并非标准正交基。
于是文章提出,对 bert 向量进行线性变换,使其均值为 0,协方差矩阵为单位矩阵。
具体数学推导参考论文,numpy 实现为:
def compute_kernel_bias(vecs):
"""计算 kernel 和 bias
vecs.shape = [num_samples, embedding_size],
最后的变换:y = (x + bias).dot(kernel)
"""
mu = vecs.mean(axis=0, keepdims=True)
cov = np.cov(vecs.T)
u, s, vh = np.linalg.svd(cov)
W = np.dot(u, np.diag(1 / np.sqrt(s)))
return W, -mu
BERT-Whiting 的效果是比 BERT-flow 好的。此外,降维(从 768 降到 256)效果更好。
SimCSE: Simple Contrastive Learning of Sentence Embeddings
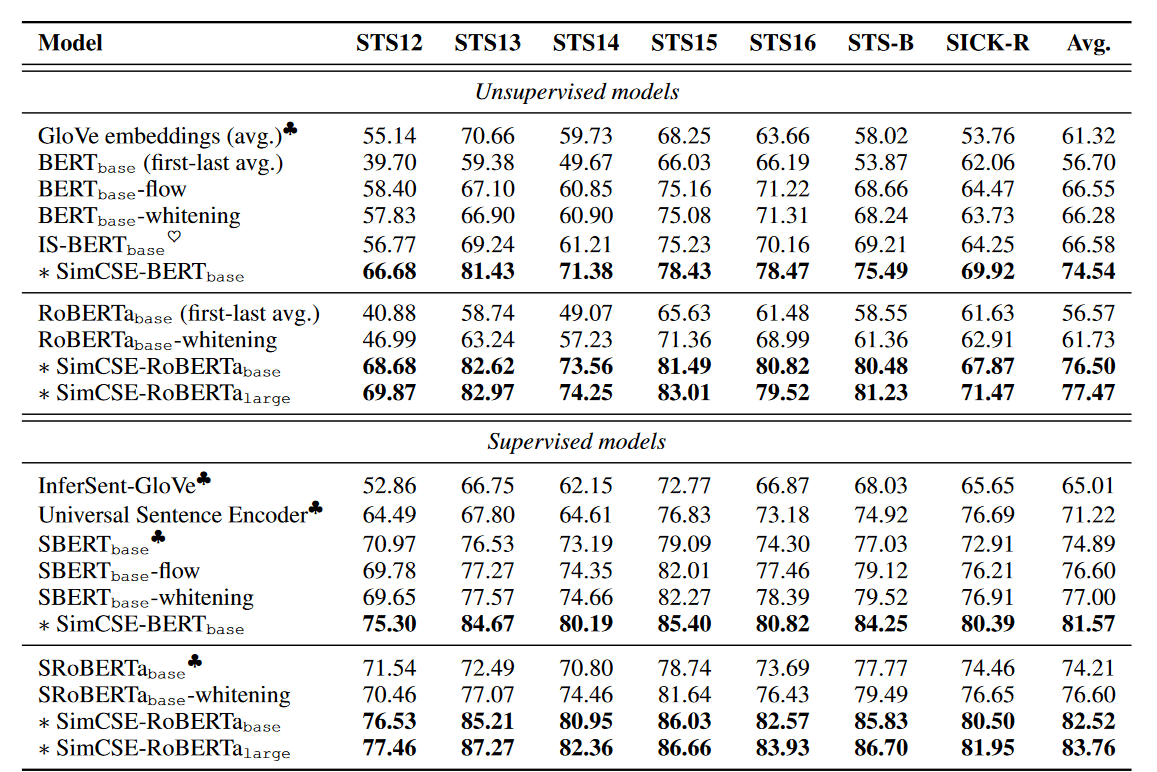
SimCSE 采用了对比学习思想,对于无监督学习,就 dropout 两次。对于监督学习,就采用难度加大。训练时候,对 MLM + 对比学习损失同时优化。对于监督学习和非监督学习,对比学习损失是不同的。
在训练时,作者发现额外添加 1 层 MLP 训练,然后在预测时候扔掉它,效果会更好。这个方法也在许多 CV 领域的对比学习文章中提到。
不同于 SBERT,SimCSE 发现采用 CLS 和 mean pooling 的效果差不多。
此外,对于对比学习在 NLP 句向量表示中的应用,美团的这篇文章做了丰富的实验:ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
参考
相关论文
[1] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
[2] An Unsupervised Sentence Embedding Method by Mutual Information Maximization
[3] Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
[4] Hash Embeddings for Efficient Word Representations
[5] code2vec: Learning Distributed Representations of Code
[6] ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
[7] From Word Embeddings To Document Distances
[8] Inductive Representation Learning on Large Graphs
[9] On the Sentence Embeddings from Pre-trained Language Models
[10] SimCSE: Simple Contrastive Learning of Sentence Embeddings](http://arxiv.org/abs/2104.08821)
其他链接
《细水长 flow 之 RealNVP 与 Glow:流模型的传承与升华》