Spark - 框架理解与使用
内容包括:Spark 搭建本地模式,集群模式(StandAlon, YARN)搭建;认识 Spark 框架、运行逻辑;认识 PySpark 下 SparkCore、SparkSQL 操作。
python 上 Spark 不断个更新,实时关注 官方文档
概述
Spark 用于大规模数据处理的统一分析引擎。其特点就是对任意类型的数据进行自定义计算。 RDD 是一种分布式内存抽象,使程序员能够在大规模集群中做内存运算,并且有一定的容错方式。这也是 Spark 的核心数据结构。知乎解答 - spark 概述
Spark 与 hadoop
Spark 仅做计算,而 Hadoop 生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS 和 YARN 仍是许多大数据体系的核心架构。在计算层面,Spark 相比较 MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于 MR 构架,比如非常成熟的 Hive
spark 框架模型
Spark Core: Spark 的核心,Spark 核心功能均由 Spark Core 模块提供,是 Spark 运行的基础。Spark Core 以 RDD 为数据抽象,提供 Python、Java、Scala、R 语言的 API,可以编程进行海量离线数据批处理计算。
SparkSQL: 基于 SparkCore 之上,提供结构化数据的处理模块。SparkSQL 支持以 SQL 语言对数据进行处理,SparkSQL 本身针对离线计算场景。同时基于 SparkSQL,Spark 提供了 StructuredStreaming 模块,可以以 SparkSQL 为基础,进行数据的流式计算。
SparkStreaming: 以 SparkCore 为基础,提供数据的流式计算功能。
MLlib: 以 SparkCore 为基础,进行机器学习计算,内置了大量的机器学习库和 API 算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX: 以 SparkCore 为基础,进行图计算,提供了大量的图计算 API,方便用于以分布式计算模式进行图计算。
Spark 架构角色
资源管理层面: 管理集群资源:Master 管理单个服务器资源:worker
任务执行层面: 管理单个 spark 任务在运行的时候的工作:Driver 单个任务运行时的工作者: Executor
快速开始
根据 官方指南, spark 提供了多种运行模式:包括本地,集群(StandAlone, YARN, K8S),云模式。
本地 local 模式配置
Local 模式搭建方便,是学习 Spark 入门操作应用的首选模式。Local 模式的本质是启动一个 JVM Process 进程(一个进程里面有多个线程),执行任务 Task。Local 模式可以使用Local[N] 或 Local[*] 限制模拟 Spark 集群环境的线程数量。N 为线程数,* 为 CPU 最大核心数。 在 local 模式下,全部四种 spark 角色都为 jvm 进程本身,且只能运行一个 Spark 程序。Local 模式可以做到开箱即用:解压从官网下载的 Spark 安装包:
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
配置 Spark 需要调整以下 5 个环境变量:SPARK_HOME,PYSPARK_PYTHON,JAVA_HOME,HADOOP_CONF_DIR,HADOOP_HOME
Spark 操作介绍
配置好后测试环境,分别运行:
bin/pyspark 可以提供一个 交互式的 Python 解释器环境, 在这里面可以写普通 python 代码。添加 --master local[*] 参数控制使用线程数量。
bin/spark-shell 提供交互式解析器环境,运行 scala 程序代码。
bin/spark-submit 提交指定的 Spark 代码到 Spark 环境中运行。如 bin/spark-submit /export/server/spark/examples/src/main/python/pi.py 10
Spark 端口
4040: 一个运行的 Application 在运行的过程中临时绑定的端口,用以查看当前任务的状态,当前程序运行完成后,,4040 就会被注销。4040 被占用会顺延到 4041.4042 等
8080 : 默认是 StandAlone 下, Master 角色(进程)的 WEB 端口,用以查看当前 Master(集群)的状态
18080/9870 : 默认是历史服务器的端口, 回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程。
PySpark
官方文档对于大规模数据集处理,安装直接使用 pip install pyspark 即可。
初体验:WordCount 实例
初始化
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
local 模式的话 master='local[n]'
读取数据到 RDD 对象:
wordsRDD = sc.textFile("hdfs://node1:8020/input/words.txt")
# 本地文件读取:file:///home/data/word.txt
RDD 对象处理
flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" "))
mapRDD = flatMapRDD.map(lambda x: (x, 1))
# 以上步骤将在不同的集群节点上执行,参考下图。因此可以并行执行,加快效率。
resultRDD = mapRDD.reduceByKey(lambda a, b: a + b)
res_rdd_col2 = resultRDD.collect()
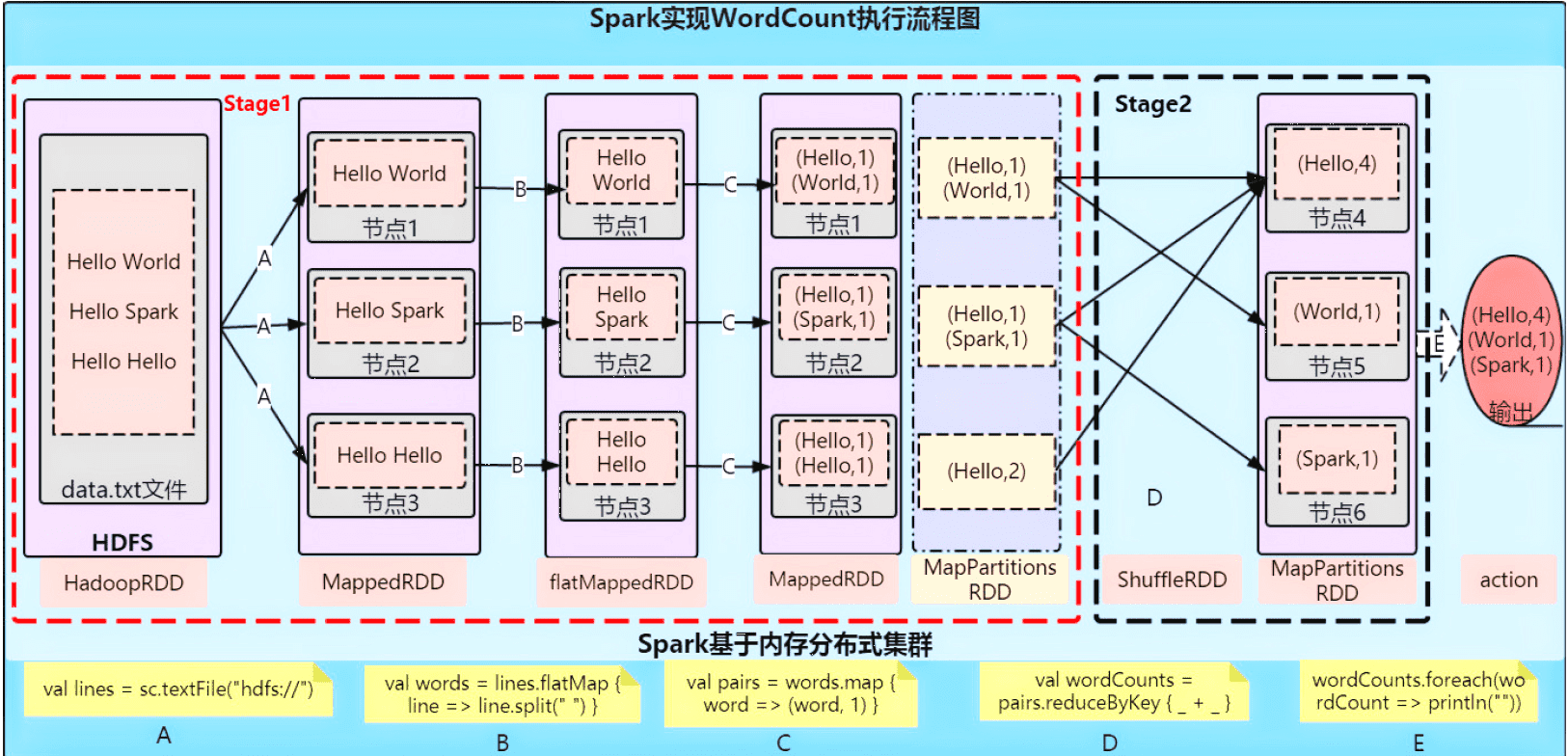
将结果写入文件并通过 spark 储存于 HDFS:resultRDD.saveAsTextFile("hdfs://node1:8020/words_new.txt")
提交代码到集群运行,需要修改初始化方式:conf = SparkConf().setAppName(appName)
而后通过 bin/spark-submit 提交到集群运行:通过 --py-files 提交依赖文件,可以单个文件 .py 或者多个文件 .zip。
/export/server/spark/bin/spark-submit --master yarn ./test.py
该 python 代码底层由 java 实现(通过 py4j 交互)
Spark Core API
分布式框架中,需要由同意的数据结构对象来实现分布式计算所需功能,这个对象就是 RDD(Resilient Distributed Dataset) 。在初体验中 wordsRDD = sc.textFile("hdfs://node1:8020/input/words.txt") 读取的就是 RDD 对象。RDD 是通过 java 实现的抽象类、泛型类型。特征包括:
- 有分区(RDD is a list of partitions)
RDD 的分区是 RDD 数据存储的最小单位,如:
sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8], numSlices=3).glom().collect()
# [[1, 2], [3, 4], [5, 6, 7, 8]]
分区为 3 时,RDD 内数据分为 3 份。
- 可并行计算,计算方法会作用到每一个分区上
resultRDD = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8], numSlices=3).map(lambda x: x*10)
print(resultRDD.glom().collect())
# [[10, 20], [30, 40], [50, 60, 70, 80]]
- RDD 之间相互依赖、迭代的;
针对快速探索中的 wordcount 案例,每个操作步骤都是一次对 RDD 的迭代。一个新的 RDD 由上一步骤的 RDD 计算得来。
- KV 型 RDD 可以由分区器;
对 key-value 型的 RDD,默认采用 Hash 分区,可以手动使用 rdd.partitionBy 设置分区。
- 分区的计算会尽量选择靠近数据所在地
目的是最大化性能,毕竟本地读取效率是大于网络读取的。
创建 RDD
可以从文件加载:sc.textFile("hdfs://node1:8020/input/words.txt"),或者从本地的集合对象(如 list)创建:sc.parallelize(set(), numSlices=3),从文件夹加载:sc.wholeTextFiles("hdfs://node1:8020/input")
RDD 算子
详细算子 官网 可查看,以下总结一些常用的。
Transformation 算子
返回一个 RDD,如果没有 action 算子,那么这类算子是不工作的。
flatMap():对 rdd 进行 map 后接触嵌套。如:
resultRDD = sc.parallelize(["hello hello","nihao nihao "])
resultRDD.map(lambda x:x.split()).collect()
# [['hello', 'hello'], ['nihao', 'nihao']]
mappedRDD = resultRDD.flatMap(lambda x:x.split())
# ['hello', 'hello', 'nihao', 'nihao']
reduceByKey():真能对 KV 型 RDD,对组内数据根据 key 分类并聚合。如:
# 接 flatmap() 例子
mappedRDD = mappedRDD.map(lambda x: (x, 1))
resultRDD = mappedRDD.reduceByKey(lambda a, b: a + b)
# [('nihao', 2), ('hello', 2)]
groupBy():将元素分组,分组后每个组是一个 KV,key 为分组 func 的返回值,value 为该组元素构成的迭代器。
dataRDD = sc.parallelize([1, 2, 3, 4, 5, 6, 7])
mappedRDD = dataRDD.groupBy(lambda x: "even" if x % 2 == 0 else "odd")
resultRDD = mappedRDD.map(lambda x:(x[0], list(x[1])))
print(resultRDD.collect())
Filter(func):过滤元素,传入的函数方法需要返回布尔值。
distinct():数据去重,一般不需要传入参数。
union():合并两个 RDD 并返回,支持不同各类型。union_rdd = rdd1.union(rdd2)
join():同 sql 的 join。支持左右拼接,leftOuterJoin(), rightOuterJoin()
dataRDD = sc.parallelize([("hello", 1), ("good", 2)])
dataRDD2 = sc.parallelize([("hello", 10), ("good", 20), ("world", 30)])
resultRDD = dataRDD.join(dataRDD2)
# [('good', (2, 20)), ('hello', (1, 10))]
# rightOuterJoin 后:[('good', (2, 20)), ('hello', (1, 10)), ('world', (None, 30))]
intersection():返回交集rdd1.intersection(rdd2)
glom() :将 RDD 数据根据分区进行嵌套。
groupByKey():针对 KV 型 RDD,根据 key 分组,但不聚合,类似 grouBy()。使用groupByKey() + 聚合的性能是远差与直接使用 reduceByKey() 的。
sortByKey() 或 sortBy(func, ascending=False, numPartitions=1):排序 func 为排序依据。 如果要全局有序,排序分区数需要设置为 1。
mapPartition(func):func 输入可迭代对象,输出可迭代对象。
def func(iter_tool):
for x in iter_tool:
yield x+1
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd1.mapPartitions(func).glom().collect())
partitionBy(func):func 参数应该为元素 hash 值到分区编号的映射。只能根据 hash 分区,因此非 KV 型 RDD 需要先进行转换。
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8]).map(lambda x:(x,x))
print(rdd1.partitionBy(3, lambda x: x % 3).glom().collect())
repartition(N):将 RDD 重新分为 N 个分区,一般除了要全局排序外,不会进行充分区。
coalesce():对分区数量进行加减,比repartition()常用,rdd.coalesce(4,shuffle=True) 如果 shuffle 为 Flase,那么将忽略分区增加操作,仅支持分区减少。 尽量不要增加分区,可能破坏内存迭代的计算管道。
mapValues(func):仅针对 KV 型 RDD,功能等价于 .map(lambda x:(x[0],func(x[1])))
Action 算子
countByKey():返回一个 collections.defaultdict
collect():统一各分区的数据,形成一个List。 谨慎使用:结果数据集太大的话,Driver 内存会爆炸。
reduce(func):迭代地减小数据维度:
sc.parallelize([1, 2, 3, 4, 5]).reduce(lambda a, b: a + b)
# 返回 15
fold():分别对各分区进行 reduce,然后聚合。reduce 是有初始值的:如:
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd1.glom().collect())
# [[1, 2], [3, 4], [5, 6]]
print(rdd1.fold(10, lambda a, b: a + b))
# (1+2+10) + (3+4+10)+(5+6+10) = 61
first():返回第一个元素。
take(N):返回前 N 个元素,List 形式储存。
top(N):返回降序排序后的前 N 个值,List 储存。
count():返回 RDD 数据数量,int。
takeSample(withReplacement=True, num=10, seed=7)):随机抽取 n 个样本。
takeOrdered(num, key=func):返回 List 为根据 func() 排序后的前 num 个元素
foreach(func):迭代对所有元素进行处理。该执行不经过 Driver。
saveAsTextFile():将 RDD 写入文本文件中。由 Executor 直接执行,执行结果不会发送到 Driver。
foreachPartition():与 foreach() 类似,但调用一次函数处理一个分区的数据。
RDD 持久化
spark 提供了 RDD 缓存 API 以减少重复计算。可以使用 persist() 或 cache() 来缓存,一般用的较多的是:persist(StorageLevel.MEMORY_AND_DISK) 。对于 python,都是用 Pickle 进行序列化缓存,更多缓存等级参考:官方。主动清理缓存的 API:rdd.unpersist()。 缓存并不是安全的,内存不足/断电/硬盘损坏等都可能造成数据出错。
RDD 的 CheckPoint 被设计认为是安全的(不排除物理因素破坏数据),仅支持硬盘储存。checkpoint 可以选择数据备份地址,因此可以存储在 HDFS 中;性能比缓存更好;不管分区多少,风险是一样的(不同于缓存)。
配置 checkpoint 目标地址:sc.setCheckpointDir("hdfs://node1:8020/output/bj52kp");保存时直接调用:rdd.checkpoint()
缓存与 checkpoint 都不是 action 操作,所以后面要加上 Action。
共享变量
每个 excutor 进程可以处理多个分区。当 excutor 处理 RDD 时需要某些 python 变量(RDD 外的 python 变量都由 Driver 处理与储存。),Driver 需要为每个分区发送一份数据。因此每个 excutor 中就有多个相同数据,造成额外网络 IO 开销与内存浪费。
广播变量: 将 python 变量数据 python_val 标记为广播变量:broadcase = sc.broadcast(python_val)。使用时:broadcast.value 提取数据。
累加器: 需求:当不同分区运行时,他们需要对同一个全局变量进行操作。python 的 global 无法满足需求,由于机器不同,无法通过指针等实现。需要使用 spark 提供的累加器。
acmlt = sc.accumulator(66) # 初始化值为 acmlt=66
def map_func(data):
global acmlt
acmlt += 1
累加器需注意: 可能需要加缓存来解决以下问题。
rdd = sc.parallelize([1,2,3,4],2)
acmlt = sc.accumulator(0)
rdd2 = rdd.map(map_func)
rdd2.collect() # rdd2 action 后不保存数据。此时 acmlt 为 4
rdd3 = rdd2.map(lambda x:x) # rdd3 构造需要再次构造 rdd2,此时 acmlt 为 8.
rdd3.collect()
print(accmlt) # 8
内核调度
根据 RDD 的迭代特性,程序的整个计算路程可以通过 DAG 有向无环图表示。每个 Action 操作的执行都会触发该一个 JOB 来计算 Action 之前的子图。1 个 action=1 个有向无环图=1 个 JOB。如果有 3 个 action,那么代码就产生 3 个 JOB,这些 JOB,Spark 称为 Application。
DAG 中 RDD 节点之间的关系分为: 窄依赖 :父 RDD 的一个分区,全部将数据发给子 RDD 的一个分区。 宽依赖/shuffle :父 RDD 的一个分区,将数据发给子 RDD 的多个分区。
stage 根据宽依赖进行划分 ,因此每个 stage 内部都是窄依赖。
每个 task 是一个线程(DAG 上呈现为,一个 stage 中的一条来连通的计算流程线),线程内是纯内存计算,所有线程并行计算,并行程度受全局并行度 spark.default.parallelism、分区数量影响。 spark 一般不要再算子上设置并行度,除了部分排序算子,分区数量让系统自动设置即可 。
集群中,并行度可以设置为 CPU 总核心的 2 到 10 倍。spark.default.parallelism=1000。
基于以上分析,spark 程序的调度流程为:
- 构建 Driver
- 构建 SparkContext
- 产生 DAG,基于 DAG Scheduler 构建逻辑 task 分配
- 基于 Task Scheduler ,将 Task 分配到 executor 上工作并监督他们,executor 工作时汇报进度。
其中 DAG Scheduler 与 Task Scheduler 为 Driver 内部的两个组件。
总结 Spark 层级
一个 Spark Application (如 bin/pyspark)中,包含多个 Job,每个 Job 由多个 Stage 组成,每个 Job 执行按照 DAG 图进行。每个 Stage 中包含多个 Task 任务,每个 Task 以线程 Thread 方式执行,需要 1Core CPU。
- Job: 由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect),会生成一个 Job。
- Stage: Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
- Task: 被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition(物理层面的概念,即分支可以理解为将数据划分成不同部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支上的数据。
在 18080 中选择 刚刚提交的 pi 计算任务。选择 Executors 查看。从 页面结果可以看出,Spark Application 运行到集群上时,由两部分组成:Driver Program 和 Executors
Spark Shuffle
DAG 将一个 Job 划分为多个 Stage,若用 map 或 reduce 来标注每个 Stage,Spark Shuffle 的作用时将 map 的输出对应到 reduce 上。shuffle 分为 shuffle write(map 的最后一步) 与 shuffle read(reduce 的第一步)。因此数据流大致为 stage1 - partition - stage2。
SparkSQL
用于存储海量结构化数据。支持 SQL,HIVE 等。SparkSQL 与 HIVE 都为分布式 SQL 计算引擎,SparkSQL 具有更好的性能。SparkSQL 中共有 DataSet、DataFrame 对象。Python 仅支持 DataFrame 对象,即一助攻二维表结构数据。
快速体验
Spark 2.0 后,推出了 SparkSession 统一编码入口对象,支持 RDD 编程与 SparkSQL 编程。
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder. \
appName("local[*]"). \
config("spark.sql.shuffle.partitions", "4"). \
getOrCreate()
# appName 设置程序名称, config 设置一些常用属性
# 最后通过 getOrCreate()方法创建 SparkSession 对象
df = spark.read.csv('file:///home/data/sql/stu_score.txt', sep=',', header=False)
df2 = df.toDF('id', 'name', 'score')
df2.printSchema()
df2.show()
df2.createTempView("score")
spark.sql("""
SELECT * FROM score WHERE name='语文' LIMIT 5
""").show()
DataFrame
DataFrame 为二维表结构,其中储存四个对象:
StructType :整个表结构的信息 StructField :描述列的信息 Row :行数据 Column :列数据以及列的信息
创建 DataFrame
从 RDD 创建,数据类型根据 RDD 推断。
sc = spark.sparkContext
rdd = sc.textFile("../data/sql/people.txt").\
map(lambda x: x.split(',')).\
map(lambda x: [x[0], int(x[1])])
df = spark.createDataFrame(rdd, schema = ['name', 'age'])
# 或 df = rdd.toDF(['name', 'age'])
其中的 schema 参数可以通过 StructType 定义:
from pyspark.sql.types import StructType, StringType, IntegerType
schema = StructType().\
add("id", IntegerType(), nullable=False).\
add("name", StringType(), nullable=True).\
add("score", IntegerType(), nullable=False)
从 pd.DataFrame 创建:直接使用 spark_df = spark.createDataFrame(p_df)
从外部文件读取:
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")
一般读取的时 json、parquet 类型的话,不需要提供schema。
对于 CSV 等,可能需要提供 option 参数。
df = spark.read.format("csv")\
.option("sep", ";")\
.option("header", False)\
.option("encoding", "utf-8")\
.schema("name STRING, age INT, job STRING")\
.load("../data/sql/people.csv")#
DataFrame 操作
DataFrame 可以通过 sparksession.sql() 直接操作,使用 sql 命令需要先注册成临时表:df.createTempView("temp_name"),以下展示部分处 sparksession.sql() 外的常用操作,详细查看 官方 API
.show(n),.printSchema():查看数据信息。
.select():选择指定的列,传入列名或 Column 对象。
.filter(condition),.where():筛选行,条件如:布尔值的列数据df['score']<9 或 SQL 风格'score'<9
.groupBy():按列分组,传入列名或列对象。返回 GroupedData 对象
from pyspark.sql import functions as F 提供了基础表数据计算功能,如 F.round(), F.avg(), F.min(), F.count 等来直接对二维数据进行计算。
.dropDuplicates():默认对整体去重,传入需要去重的列。
.dropna(thresh, subset):针对 subset 给出的列,有效信息至少为 thresh 个才保留该行数据。
.fillna(): 传入一个填充规则,表示每个列的填充值{'name':"unk","job":0}
读写数据
写出为文件:
df.write.mode("overwrite").format("csv").\
option("sep",",").option("header",True).\
save("../mydata.csv")
对于 json格式直接写出,不需要 option,默认的文件写出格式为 parquet。
使用 JDBC 读写数据库 ,需要驱动mysql-connector-java-5.1.41-bin.jar 不同 mysql 对应版本不同。jar 包存放地址:py 解析器环境/lib/python3.8/site-packages/pyspark/jars
df.write.mode("overwrite").format("jdbc").\
option("url","jdbc:mysql://node1:3306/databese?useSSL=false&useUnicode=true").\
option("dbtable","u_data").\
option("user","root").\
option("password","123456").\
save()
jdbc 连接字符串中,建议使用 useSSL=false 保证正常连接,useUnicode=true 保证传输无乱码。dbtable 为写出的表名。
使用 JDBC 读取数据库:
df = read.format("jdbc").\
option("url","jdbc:mysql://node1:3306/databese?useSSL=false&useUnicode=true").\
option("dbtable","u_data").\
option("user","root").\
option("password","123456").\
load()
SparkSQL 定义 UDF
User-Define-Function,对 python 函数进行注册,返回可用于 DSL 的函数操作,注册的函数名称可用于 SQL 风格。
udf = spark.udf.register("udf1", lambda x: x < 10, BooleanType())
df.filter(udf(df['age'])).show()
对于传递的返回类型参数,需要从 pyspark.sql.types 中选取,数组类型可用 ArrayType(StringType())(即 python 中的 List(Str));字典类型使用 StructType(),此处需要提前声明 StructTrype() 中的结构体信息。
窗口函数
可以将聚合前与聚合后的数据显示在同一个表中。
# 在 * 数据后追加一列窗口,代表学生的平均成绩
spark.sql("""
SELECT *, AVG(SCORE) OVER() AS avg_score FROM stu
""")
# 聚合类型 SUM/MIN/MAX/AVG/COUNT
SUM() OVER([PARTITION BY XX][ORDER BY XX])
# 排序类型 RANK/ROW_NUMBER/DENSE_RANK
RANK() OVER()
# 分区类型 NTILE
NTILE(number) OVER()
SQL 流程
SparkSQL 可以自动优化(依赖于 Catalyst 优化器),提升代码运行效率。SparkSQL 接收到 SQL 语句后,通过 Catalyst 解析,并生成 RDD 执行计划,而后交给集群执行。
Catalyst 优化:
首先生成 AST 抽象语法树,在 AST 中加入元数据信息(以供优化)。优化方式包括:
Predicate Pushdown 断言下推:将 Filter 这种可以减小数据集的操作下推,放在 Scan 的位置,减少无用操作量。(如提前执行 where)
Column Pruning 列值裁剪:断言下推后,对无用的列进行裁剪。(如提前规划 select 数量)
等等许多优化方案 ,具体可查看
org.apache.spark.sql.catalyst.optimizer.Optimizer源码
Spark on Hive
相当于将 HIVE SQL 解释器引擎换成了 SparkSQL 解释器引擎。
Spark 自身没有元数据管理功能,当 Spark 执行 SQL 风格语句如 SELECT * FROM person 时候,如果没有 person 储存位置,person 包含的字段、字段类型的话,则 SQL 语句将无法被解析并执行。
SparkSQL 中将这些元数据信息注册在了 DataFrame 中,而数据库的元数据信息,由 Hive 的 MetaStore 来提供管理,Spark 只是提供执行引擎。因此 Spark 能够链接上 Hive 的 MetaStore 就可以了,MetaStore 需要存在并开机,通过配置 hive-site.xml Spark 能知道 MetaStore 的端口号:
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
代码中只需要增加 3 行代码以继承 Hive
spark = SparkSession.builder. \
appName("local[*]"). \
config("spark.sql.shuffle.partitions", "4"). \
config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris","thrift://node1:9083").\
enableHiveSupport().\
getOrCreate()
分布式 SQL 执行引擎
Spark 的 ThriftServer 服务可以在 10000 端口监听。通过该服务,用户会写 SQL 就可操作 spark。
启动 ThriftServer 服务
$SPARK_HOME/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server.thrift.bind.host=node1 \
--master local[2]
常用的用来链接的客户端工具有 DBeaver, datagrip, heidisql。python 代码链接 Thrift 可使用 pyhive 库。
pip install pyhive pymysql sasl thrift thrift_sasl
from pyhive import hive
conn = hive.Connection(host="node1", port=10000, username="hadoop")
cursor = conn.cursor()
cursor.execute("SELECT * FROM test")
result = cursor.fetchall()
print(result)
其他
Koalas——基于 Apache Spark 的 pandas API 实现
Spark mllib 文档 MLlib 提供基础的机械学习算法,代码风格类似 sklearn。
其他运行模式搭建
Standalone 架构
Standalone 模式是 Spark 自带的一种集群模式,该模式中 master 与 worker 以独立进程的形式存在。 StandAlone 是完整的 Spark 运行环境,其中: Master 角色以 Master 进程存在, Worker 角色以 Worker 进程存在 Driver 和 Executor 运行于 Worker 进程内, 由 Worker 提供资源供给它们运行
StandAlone 集群在进程上主要有 3 类进程:
- 主节点 Master 进程:Master 角色, 管理整个集群资源,并托管运行各个任务的 Driver
- 从节点 Workers:Worker 角色, 管理每个机器的资源,分配对应的资源来- 运行 Executor(Task); 每个从节点分配资源信息给 Worker 管理,资源信息包含内存 Memory 和 CPU Cores 核数
- 历史服务器 HistoryServer(可选):Spark Application 运行完成以后,保存事件日志数据至 HDFS,启动 HistoryServer 可以查看应用运行相关信息。
实例集群规划
尝试使用三台 Linux 虚拟机来组成集群环境进行体验,非别是:
node1 运行: Spark 的 Master 进程 和 1 个 Worker 进程 node2 运行: spark 的 1 个 worker 进程 node3 运行: spark 的 1 个 worker 进程
整个集群提供: 1 个 master 进程 和 3 个 worker 进程
安装
在所有节点上安装 python anaconda ,同时不要忘记 都创建pyspark虚拟环境 以及安装虚拟环境所需要的包pyspark jieba pyhive
为了让 spark 拥有 hdfs 最大权限,spark 安装也使用 hadoop 用户:chown -R hadoop:hadoop spark*
配置配置文件
进入到 spark 的配置文件目录中, cd $SPARK_HOME/conf
配置 workers 文件
# 改名, 去掉后面的.template 后缀
mv workers.template workers
# 编辑 worker 文件
vim workers
# 将里面的 localhost 删除, 追加
node1
node2
node3
到 workers 文件内
# 功能: 这个文件就是指示了 当前 SparkStandAlone 环境下, 有哪些 worker
配置 spark-env.sh 文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑 spark-env.sh, 在底部追加如下内容
## 设置 JAVA 安装目录
JAVA_HOME=/export/server/jdk
## HADOOP 软件配置文件目录,读取 HDFS 上文件和运行 YARN 集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定 spark 老大 Master 的 IP 和提交任务的通信端口
# 告知 Spark 的 master 运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知 sparkmaster 的通讯端口
export SPARK_MASTER_PORT=7077
# 告知 spark master 的 webui 端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu 可用核数
SPARK_WORKER_CORES=1
# worker 可用内存
SPARK_WORKER_MEMORY=1g
# worker 的工作通讯地址
SPARK_WORKER_PORT=7078
# worker 的 webui 地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将 spark 程序运行的历史日志 存到 hdfs 的/sparklog 文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
注意, 上面的配置的路径 要根据你自己机器实际的路径来写
在 HDFS 上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
配置 spark-defaults.conf 文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf
# 2. 修改内容, 追加如下内容
# 开启 spark 的日期记录功能
spark.eventLog.enabled true
# 设置 spark 日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置 spark 日志是否启动压缩
spark.eventLog.compress true
配置 log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties
# 2. 修改日志警报级别 因为 Spark 是个话痨
log4j.rootCategory=WARN, console
将 Spark 安装文件夹 分发到其它的节点上
scp -r spark-3.1.2-bin-hadoop3.2 node2:/export/server/
scp -r spark-3.1.2-bin-hadoop3.2 node3:/export/server/
不要忘记, 在 node2 和 node3 上 给 spark 安装目录增加软链接
ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark
验证环境
先开启 zoopkeeper zookeeper/bin/zkServer.sh start, hadoop s等。 启动历史服务器 sbin/start-history-server.sh 启动全部 workers 和 master:sbin/start-all.sh
分别测试 pyspark, spark-shell, spark-submit 使用情况:
bin/pyspark --master spark://node1:7077
# 提供 --master 连接到 StandAlone,不写默认是 local 模式
bin/spark-shell --master spark://node1:7077
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
运行后通过 web node1:18080 查看历史服务器信息;node1:8080 查看 master。
Spark StandAlone HA
Spark Standalone 集群是 Master-Slaves 架构的集群模式,和大部分的 Master-Slaves 结构集群一样,存在着 Master 单点故障(SPOF)的问题。 如何解决这个单点故障的问题,Spark 提供了两种方案: 1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。 2.基于 zookeeper 的 Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。 ZooKeeper 提供了一个 Leader Election 机制,利用这个机制可以保证虽然集群存在多个 Master,但是只有一个是 Active 的,其他的都是 Standby。当 Active 的 Master 出现故障时,另外的一个 Standby Master 会被选举出来。由于集群的信息,包括 Worker,Driver 和 Application 的信息都已经持久化到文件系统,因此在切换的过程中只会影响新 Job 的提交,对于正在进行的 Job 没有任何的影响。加入 ZooKeeper 的集群整体架构如下图所示。 toadd 基于 Zookeeper 实现 HA
步骤
前提: 确保 Zookeeper 和 HDFS 均已经启动 在spark-env.sh中, 删除: SPARK_MASTER_HOST=node1 在spark-env.sh中, 增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定 HA 模式 基于 Zookeeper 实现
# 指定 Zookeeper 的连接地址
# 指定在 Zookeeper 中注册临时节点的路径
将 spark-env.sh 分发到每一台服务器上
scp spark-env.sh node2:/export/server/spark/conf/
scp spark-env.sh node3:/export/server/spark/conf/
停止当前 StandAlone 集群
sbin/stop-all.sh
master 主备切换
提交一个 spark 任务到当前alivemaster 上:
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 1000
在提交成功后, 将 alivemaster 直接 kill 掉,不会影响程序运行:
当新的 master 接收集群后, 程序继续运行, 正常得到结果。同时新 master 的 8080 界面显示状态从 STANDBY 变为 RECOVERING/ ACTIVE。
HA 模式下, 主备切换 不会影响到正在运行的程序.
Spark On YARN 环境搭建
许多企业不管做什么业务,都基本上会有 Hadoop 集群. 也就是会有 YARN 集群。因此在有 YARN 集群的前提下单独准备 Spark StandAlone 集群,对资源的利用就不高。 Spark on YARN 是最常见的应用框架。 对于 Spark On YARN, 无需部署 Spark 集群, 只要找一台服务器, 充当 Spark 的客户端, 即可提交任务到 YARN 集群中运行。
本质
Master 角色由 YARN 的 ResourceManager 担任 Worker 角色由 YARN 的 NodeManager 担任 Driver 角色运行在 YARN 容器内或提交任务的客户端进程中 真正干活的 Executor 运行在 YARN 提供的容器内
部署
配置 spark-env.sh 中的 HADOOP_CONF_DIR、 YARN_CONF_DIR 环境变量,指向 hadoop 与 yarn 的配置文件目录
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop/
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop/