Transformer 位置编码小述
绝对位置编码
Transformer 的 Multi-Head-Attention 无法判断各个编码的位置信息。因此 Attention is all you need 中加入三角函数位置编码(sinusoidal position embedding),表达形式为:
其中 pos 是单词位置,i = (0,1,... d_model) 所以d_model为 512 情况下,第一个单词的位置编码可以表示为:
BERT、GPT 等也是用了绝对位置编码,但是他们采用的是可学习的绝对位置编码。
相对位置编码
经典相对位置编码
Self-Attention with Relative Position Representations 论文提出了在 self-attention 中加入可学习的相对位置编码,位置 之间的相对位置信息表示为 。注意力计算方式为:
论文认为相对位置信息太长并没有用,因此便对位置距离进行了截断:
其中 , 格式同 ,都是可学习的参数。但后续实验表明,当 时,模型的表现效果差别不大。
华为的 NEZHA 采用的也是以上的相对位置编码方式,不同的是 NEZHA 中的 均使用 sinusoid encoding matrix:
NEZHA 表示这样做是为了能够在预测阶段处理更长的序列。
Transformer-XL
Transformer-XL 主要思想是将 RNN 与 Transformer 结合。给定一个文章中连续的两个长度为 的片段 和 ,对于 的隐状态 ,在计算注意力之前与 去除梯度后的隐状态 拼接(仅计算 KV 时拼接,因此 , ,):
同时论文针对注意力权重进行了修改。Transformer 采用绝对位置编码下的注意力权重表示为:
Transformer-XL 提出了新的相对位置编码方式:
如果从这个角度来看的话,上节中的经典相对位置编码仅采用了 两项。相比于使用可学习参数来表示位置之间的关系,Transformer-XL 中 之间的位置关系矩阵 为 sinusoid encoding matrix(与 NEZHA 相同); 为可学习参数;用 分别对单词编码和位置编码进行映射。因此一个 Transformer-XL 模块可以表示为:
上述 Transformer-XL 的相对位置编码以及 recurrence mechanism 也被应用在了 XLNet 中,同时 XLNet 的 Segment encodings 也采用了相对位置编码的思想,如果位置 在同一个片段内,则 ,反之为 。其中 为可学习参数。在计算注意力权重时,将位置之间的相对段落编码加入: ,其中 为 query 编码, 为加入段落相对位置编码前的原始注意力权重。
TENER
TENER 文中分析了 sinusoidal position embedding 的问题,这种位置编码的方式使得任意两个位置的编码 能够传递位置间的距离信息 。对于位置 的编码 ,他们之间的点积受距离 影响:
但对于 Multi-Head-Attention,位置编码并非直接点积,而是先经过了一次线性变换:。因此距离信息可能在参数学习过程中淡化或者增强。下图表示了 (蓝点)及 (绿、红点)。可以看出对于随机初始化的 ,相对位置信息 并没有明显的特点。这或许能解释为啥作者在设计位置编码的过程(下文 式)中没有使用 。
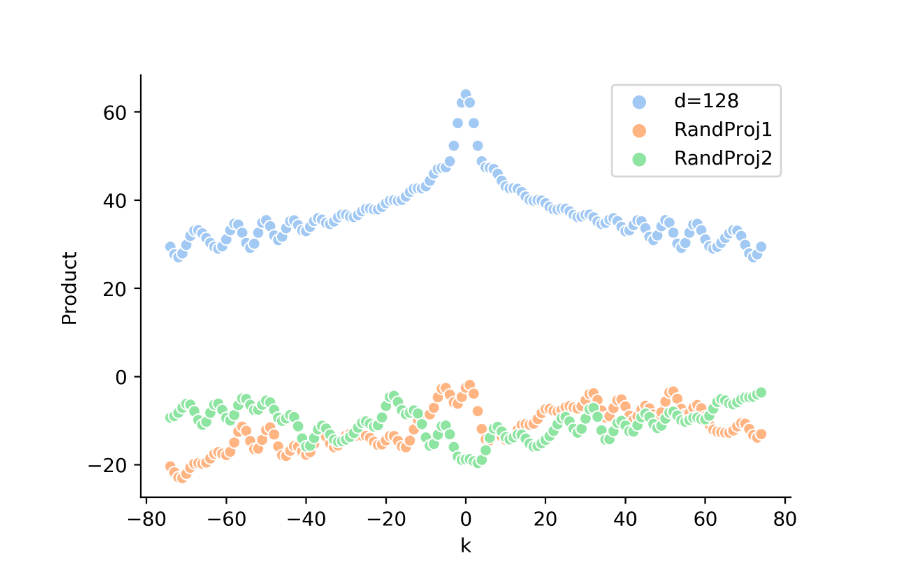
然而正弦位置编码间的点积 无法传递位置方向关系 :
该问题使得 vanilla Transformer 在实体识别任务上表现不如 LSTM 系列模型。单词先后顺序对判断实体类别有重要意义,如在例句 福建省位于东南沿海 中,可以根据位于判断其前后名词类别。TENER 提出了新的相对位置编码方式:
该方案与 Transformer-XL 相似,引入了两个可学习参数 ,以及相对位置信息 ,比较特别的是 ,去掉 是为了减小模型复杂度,增强模型在小规模 NER 数据集上的学习效果。
此外 TENER 还采用了 Un-scaled Dot-Product Attention 没有对 除以 。论文猜测这样实验效果更好是由于 NER 任务中的样本不均衡导致的。但个人猜测以保持注意力运算中二阶矩不变的角度出发,将 除以 效果可能会更好。
T5
T5 中采用了更简单的位置编码方式:。论文称 为可学习参数,所有层之间共享,Attention 中不同头使用的位置编码不一样。但在根据部分博主对源码的描述,T5 使用了固定的 ,并且根据 对 进行了分桶处理。如:, 等。该做法符合直觉:相对距离的边际效应随距离增大而逐渐减小。
DeBERTa
DeBERTa 提出了解耦注意力(DISENTANGLED ATTENTION ),考虑公式 中的分解注意力权重方案,其可分为四项:内容-内容,内容-位置,位置-内容,位置-位置 。经典款中保留了前两者,Transformer-XL 、TENER 保留了全部,T5 保留了内容-内容与位置-位置。在 DeBERTa 保留了前三者:
,,, 为超参:位置距离上限。
其中相对位置信息也采取了截断:
此处对 除以 ,个人猜测是由于作者假设 式中 相互独立,若 方差为 1,期望为 0,那么:
因此 各自方差为 ,要保持输出方差为 1 的话,则需要对 除以 ,hugging face 上的 DeBERTa 代码 scale_factor = 1 + len(self.pos_att_type) 也与该猜想符合,其中 self.pos_att_type=['p2c','c2p] 。(源码别看论文上的 MircoSoft 仓库链接,那边写的 DeBERTa 细节有亿点点不一样。)
此外,DeBERTa 还在模型中加入了绝对位置编码信息,前 m 层 Transformer 模块论文作者总成为 Encoder,只使用相对位置信息。后 n 层 Transformer 模块,论文作者成为 EMD(Enhanced Masked Decoder),加入了绝对位置信息。(但笔者在 hugging face 源码中并未找到相关配置,头疼)。
参考
[1] NEZHA: NEURAL CONTEXTUALIZED REPRESENTATION FOR CHINESE LANGUAGE UNDERSTANDING [2] Self-Attention with Relative Position Representations [3] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context [4] TENER: Adapting Transformer Encoder for Named Entity Recognition [5] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [6] DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION [7] 让研究人员绞尽脑汁的 Transformer 位置编码 [8] 层次分解位置编码,让 BERT 可以处理超长文本