知识图谱| 概念与构建
以 刘焕勇 - 基于知识图谱的医疗问答系统 为例,梳理知识图谱框架、资源整合。
基础概念
图谱是什么
目前知识图谱并有没有一个统一的定义,但大致上是一种大规模语义网络, 包含实体,概念及其之间的各种语义关系。 概念与类相似,实体是概念的实例,实体下通常会有不同的属性值。
图谱分为 通用知识图谱 (General-purpose Knowledge Graph)和 领域或行业知识图谱 (Domain-specific Knowledge Graph)。两者相辅相成,通用知识图谱可以为行业知识图谱的构建提供高质量信息,而行业建成后又可以改善通用知识图谱的质量。部分学者也将两者分别称为 开放领域知识图谱 和 垂直领域知识图谱
具有代表性的图谱有 Cyc, WordNet, ConceptNeet, Freebase, GeoNames, DBpedia, YAGO, openIE, BableNet, WikiData, Google 知识图谱,Probase,搜狗知心方,百度知心,CN-DBpedia 等。
构建
制作一个知识图谱需要有一套可遵循的规范标准来。该标准对 层级关系 、 概念 、 属性 等进行约束;由于标准不同,知识图谱在知识体系的层面上通常可以分为 Ontology、Taxonomy 和 Folksonomy 三中组织方式,其中 Ontology(本体)最为严格。本体可以通过定义概念、类、关系、函数、公理及实例等来解决唯一性和可推理能力(如何定义并没有统一的标准)。
图谱构建大致分为:
术语收集 - 术语用于表示一些基本的概念、实体、属性词及关系词。如医疗领域图谱案例中的术语有:诊断检查项目、医疗科目、疾病、药品、疾病症状、治疗方式等实体类型术语;及关节镜检查、烧伤科、京万红痔疮膏等实例术语。
定义本体概念层级 - 基于收集好的术语,定义概念层级,包括:
- 区分概念和实例:实例是不可再分的最细粒度信息承载单位。如将"药品"作为概念或实体类别;将“京万红痔疮膏”作为实例。案例项目 中收集有 44111 个实体,7 个概念,相同类别的实例储存在同一文件中,文件名为对应的概念名称。
- 概念间关系定义:如 <疾病,有症状,症状>等。
概念通常无法一下子全面定义,需要在图谱搭建、或者今后的业务执行过程中不断完善。
定义本体属性关联 - 属性与属性之间的推理、关系与关系之间推理。
定义本体约束条件 - 概念实例与属性条件限制
相关资料:知识图谱入门:知识图谱构建中的本体设计、关键流程与开源本体工具总结
知识图谱 schema
以下是由 每天都要机器学习 根据 刘焕勇-医疗知识图谱 定义的 schema 实例。其中大致表示了图谱中概念与概念之间的关系。
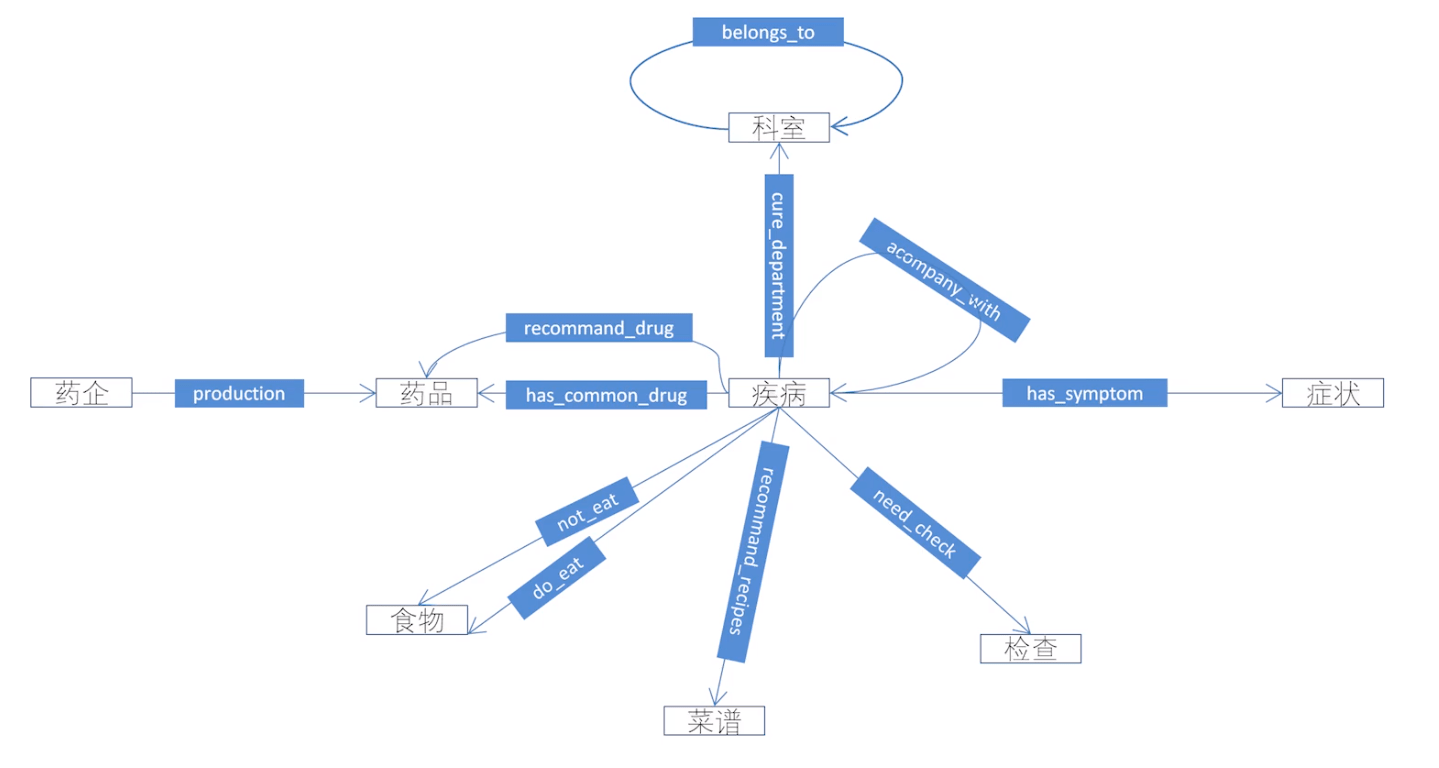
(图:医疗知识图谱 schema)
schema 可以自顶向下构建,从确定好的业务与领域出发,逐层向下分类细化,最后对实体归类;也可以从下往上,首先对实体进行组织,然后逐层向上抽象出类别。
知识抽取
如果能够收集到项目相关的结构化数据,那么可以直接通过规则将数据映射到图数据库两种。但优质的结构化数据太难找,大部分情况下,我们需要从非结构化的预料中提取 <实体-关系-实体> 信息,对应的任务包括 命名体识别、关系抽取、实体链接、指代消解、同义词挖掘等。
命名体识别
命名体识别任务即从语料中抽取出对应的实体词,通常作为序列标注问题解决,除此外还可以通过规则进行提取(如邮件)或阅读理解 QA 的方式。
相关数据及任务:CoNLL03, OntoNotes;相关工具:jieba, hanlp, stanfordnlp(英文)
相关资料:
命名实体识别(bert/lstm-crf)实践与探索知识图谱入门:知识图谱构建中的实体识别常用范式、关键问题与应对措施总结
关系抽取(识别)
关系抽取的结果为三元组(主体,关系谓词,客体)。该问题可以分为 给定关系抽取实体、给定实体判断关系 或 开放式抽取。
关系抽取常用的数据库有,ACE-2005,SemEval-2010 task 8 等。或由远程监督思想构造的 NYT 和 KBP 数据集。NYT 是目前学术研究中被广泛采用的评测数据集。
相关资源:
知识图谱入门:实体关系识别与标准化对齐开源工具、常用方法、关键问题总结nlp 中的实体关系抽取方法总结NLP 关系抽取 — 概念、入门、论文、总结
实体消歧与链接
实体链接将不同来源的、相同意义的实体进行匹配。是知识库扩充,知识问答,信息整合等任务中十分重要的环节。
相关资源:
知识图谱入门:实体链接的实现流程、关键问题与开放数据集总结Entity Linking with a Knowledge Base: Issues, Techniques, and Solutions 笔记知识工场 | 让机器认知中文实体 —复旦大学知识工场发布中文实体识别与链接服务【知识图谱构建系列篇】实体链接 Entity Linking 综述+20 篇文献调研
数据采集
案例项目从 寻医问药 爬取数据,对网页源代码解析后将概念、属性等信息保存于 MongoDB,最后通过 python 存入 Neo4J。
相关资源:知识图谱入门:图谱构建中的数据采集、文本解析处理、数据分析常用工具总结
数据储存与可视化
提取好信息后,可以储存为 RDF 三元组。由于该案例项目较特殊,大部分信息围绕疾病展开,因此可以采用 json 格式储存,如下:
{ "_id" : { "$oid" : "5bb578b6831b973a137e3ee8" }, "name" : "苯中毒", "desc" : "苯(benzene)是从煤焦油分馏及石油裂解所得的一种芳香烃化合物,系无色有芳香气味的油状液体。......", "category" : [ "疾病百科", "急诊科" ], "prevent" : "对于急性中毒患者,可以立即脱离现场至空气新鲜处,脱去污染的衣着,并用肥皂水或清水冲洗污染的皮肤。......", "cause" : "吸入苯蒸气或皮肤接触苯而引起的中毒,有急性、慢性之分。....", "symptom" : [ "恶心", "抽搐", "感觉障碍" ], "yibao_status" : "否", "get_prob" : "0.065%", "easy_get" : "多见于制鞋工人及接触化工染料的工人", "get_way" : "无传染性", "acompany" : [ "贫血" ], "cure_department" : [ "急诊科" ], "cure_way" : [ "药物治疗", "支持性治疗" ], "cure_lasttime" : "根据不同病情一般为 2-4 周", "cured_prob" : "75%", "common_drug" : [ "布美他尼片", "十一味金色丸" ], "cost_money" : "根据不同病情,不同医院,收费标准不一致,市三甲医院约(5000——8000 元)", "check" : [ "血常规", "骨髓象分析", "先令氏指数" ], "do_eat" : [ "鸡蛋", "大豆", "猪肉(瘦)", "樱桃番茄" ], "not_eat" : [ "海蟹", "海虾", "海参(水浸)", "辣椒(青、尖)" ], "recommand_eat" : [ "豆腐干炒韭菜", "素炒小白菜", "白菜蛋花粥" ], "recommand_drug" : [ "布美他尼片", "十一味金色丸",..., "地塞米松磷酸钠注射液" ], "drug_detail" : [ "桂林南药布美他尼片(布美他尼片)",...,"皇隆制药注射用呋塞米(注射用呋塞米)" ] }
其中包括了疾病属性:
| 属性类型 | 中文含义 | 属性类型 | 中文含义 |
|---|---|---|---|
| name | 疾病名称 | cure_lasttime | 治疗周期 |
| desc | 疾病简介 | cure_way | 治疗方式 |
| cause | 疾病病因 | cured_prob | 治愈概率 |
| prevent | 预防措施 | easy_get | 疾病易感人群 |
以及概念间关系:
| 实体关系类型 | 中文含义 | 实体关系类型 | 中文含义 |
|---|---|---|---|
| common_drug | 疾病常用药品 | recommand_drug | 疾病推荐药品 |
| do_eat | 疾病宜吃食物 | recommand_eat | 疾病推荐食谱 |
| need_check | 疾病所需检查 | has_symptom | 疾病症状 |
| no_eat | 疾病忌吃食物 | acompany_with | 疾病并发疾病 |
| belongs_to | 属于 | drugs_of | 药品在售药品 |
drug_detail 中存有药品与在售药品信息。cure_department 中存有科室间关系,如:cure_department:["内科","消化内科"]
案例项目从以上 json 数据整理出节点列表与关系三元组,而后导入到了 Neo4J 中。
节点导入
from py2neo import Graph,Node
def create_diseases_nodes(self, disease_infos):
for disease_dict in disease_infos:
node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],
prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],
easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],
cure_department=disease_dict['cure_department'], cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])
self.g.create(node)
关系匹配
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
# 去重处理
set_edges = []
for edge in edges:
set_edges.append('###'.join(edge))
all = len(set(set_edges))
for edge in set(set_edges):
edge = edge.split('###')
p = edge[0]
q = edge[1]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.g.run(query)
except Exception as e:
print(e)
return
# self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')
相关资源:知识图谱入门:知识图谱存储、融合、可视化、图表示计算与搜索常用工具总结
知识问答
首先,程序需要对用户问题进行理解,该任务包括 意图识别、领域识别、关系识别、命名体识别、指代消解、实体链接、槽位填充、对话状态追踪等模块。
而后对不同的业务类型及自然语言理解的结果,采用不同的方式进行回复。
一般对于信息查询或咨询类问题
可以 基于图数据库 进行回答。通过实体、关系等信息生成数据库检索语句,然后使用规则或者自然语言生成模块输出回复语句。涉及的技术有子图召回、数据库检索语句生成、自然语言生成等;
或者 基于问答数据库 ,将用户问题与事先准备好的“问题-答案”对进行匹配。涉及到文本向量化表示、邻近搜索、倒排索引等检索相关技术。
案例分析
意图识别
输入用户问题,输出该问题的领域分类及关系识别结果。
原作者采用了暴力匹配领域特征词的方式(采用 AC 自动机加速)进行用户意图识别。
定义 领域词 (region_word):领域词定义为所有概念术语的集合、包括疾病、部门、药品、食品等。
领域分类 :使用 AC 自动机检索用户问题中存在的领域词。根据领域词将问题进行多标签分类,如出现 苯中毒、板蓝根,则标记为 疾病、药品。
关系识别 :利用领域分类与问题中出现的询问词,建立关系识别规则。如:
self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']
question_types = []
if self.check_words(self.symptom_qwds, question) and ('disease' in types):
question_type = 'disease_symptom'
question_types.append(question_type)
如果问题中有 ['症状', '表征', '现象', '症候', '表现'] 中的词,并且问题被标记为 疾病 领域,那么就将问题标记为寻求 疾病症状 关系。
答案解析
输入意图识别得出的 领域分类、关系识别结果
- 生成 Cypher 语句 :建立规则,基于问题的领域分类与问题中的实体术语,生成图数据库检索语句,如:
if question_type == 'disease_cause':
sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
针对询问疾病症状的问题,对每一个问题中出现的疾病,生成一个查询对应症状的语句。
- 生成回复 :执行 Cypher 查询语句,通过语句模版生成结果。如:
if question_type == 'disease_symptom':
desc = [i['n.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
上述例子通过规则实现了简单的问答,除此外各个模块也有不同的实现方法:
实体规范化
文本纠错
参考 医疗健康领域的短文本理解
利用已有的词典或语言模型的统计结果,结合句法分析的规则来确定错误的字。常见的做法就是利用同音、同型字典把出错的字替换掉,然后生成一个候选集合。最后对候选集进行打分。
mention 提取
类似实体提取
意图识别
关系识别
参考 美团 KBQA ,采用预训练模型(剪枝、蒸馏、预精调),将多分类问题转换为匹配问题,解决数据库中边关系不断增加问题。同时加入领域识别结果与句法信息。
依存分析
依存分析是句法分析的一种。在 刘焕勇 - 基于知识图谱的医疗问答系统 中并没有依存分析模块,假设用户问题为:苯中毒怎么治疗?血栓闭塞性脉管炎又是什么病。根据案例项目的规则,系统会将问题正确标记为 “询问疾病治疗方案” 及 “询问疾病详情” 。但由于缺少依存分析,系统会多给出 “苯中毒是什么” 和 “血栓闭塞性脉管炎怎么治疗” 两个回答。
经典的依存分析模型有: Deep Biaffine Attention for Neural Dependency Parsing
相关资源:
SemEval-2016 Task 9 Chinese Semantic Dependency ParsingCoNLL 系列任务 (如 2017/18 Multilingual Parsing from Raw Text to Universal Dependencies。07/08/09 年也有类似任务)
工具:FudanNLP,spaCy,StanfordCoreNLP,hanlp
槽位填充
槽位填充的目的与依存分析较为相似,都是找到目标关系对应的实体。相关模型:
Slot-Gated Modeling for Joint Slot Filling and Intent PredictionBERT for Joint Intent Classification and Slot FillingJoint Multiple Intent Detection and Slot Labeling for Goal-Oriented Dialog
子图召回与答案排序
通过
多轮对话
可以继承上文的实体分析/槽位填充 或者 意图识别结果
苯中毒是什么? ... 血栓闭塞性脉管炎呢?
苯中毒是什么? ... 怎么治疗?
文本检索
通常用于检索问答。
Elasticsearch
solr 搜索平台
复杂问题理解
其他资源
回顾·知识图谱在贝壳找房的从 0 到 1 实践知识结构化在阿里小蜜中的应用基于知识图谱的问答在美团智能交互场景中的应用和演进医疗健康领域的短文本理解美团知识图谱问答技术实践与探索