CV 领域 Transformers 相关笔记
对 CV 领域的 Transformer 相关任务做个小整理。
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
不同于 NLP 中的 transformer,ViT 的输入为不同图片的 patch。
如原始图片 224*224,每个 patch 大小为 16*16,那么输入的序列长度为 14*14。
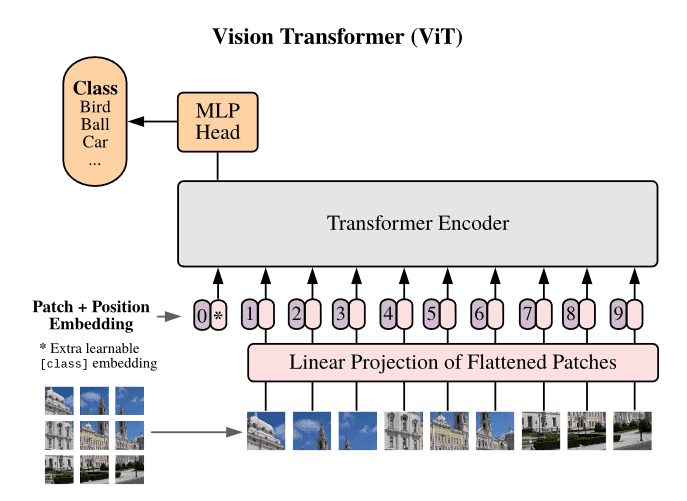
每个 patch 都会在 flatten 后通过线性变换,映射到一个与 NLP 相同的 token embedding 上。Transformer 中的其他操作不变。
文中发现用 1-D 和 2-D 位置编码,效果似乎都差不多。因此就用了 1-D 可学习位置编码。
ViT 在大规模的数据集上预训练+微调的效果要好于 resnet,但是在 few-shot 的场景下,与 resnet 还是有点差距。
ViT 中的自监督学习为:随机对 patch 进行掩码:80% 概率用 [mask] 遮盖掉 50%原始 patch 的 embedding。10%概率用其他 patch 的 embedding 替换,10% 概率保持不变。
预测的方式选一个:1. 预测整个 patch 的 3bit mean color. 2. 对 patch 进行 downsampling,而后对缩小像素后的每个部分单独预测 mean color。3. 对每个像素预测,使用 L2 + regression。
实验发现第三种效果最差。
Training data-efficient image transformers & distillation through attention
ViT 的一个问题就是预训练开销太大。包括预训练图像集未公开,预训练超参配置难,训练周期长等。
论文提出采用蒸馏的方式训练一个 DeiT,只需要 4 个 GPU 训练 3 天即可。
首先在 ViT 输入末尾加入一个蒸馏 Token,其位置对应的 logits 将被用来计算蒸馏损失。
蒸馏时对分类任务交叉熵以及蒸馏任务同时进行优化,分类任务交叉熵采用 cls 位置对应 logits 计算。蒸馏任务损失可采用教师模型输出的 label 离散值,或者输出的 softmax 分布作为标签,进行优化。模型优化方式与 NLP transformer 大同小异。
整个蒸馏采用 Regnet 作为教师模型。训练出来的 DeiT 模型比同规模的 ViT 要好,并且能够媲美教师模型。
此外,使用蒸馏 token + CLS token 进行分类任务的效果要比单独使用任意一个 token 要好。
此外,论文通过数据增强方案实现了 data efficient training,大部分的数据增强方案都能够提高模型效果。
BEIT: BERT Pre-Training of Image Transformers
为了实现类似于 BERT 的 Masked Auto Encoder,论文提出了先额外训练一个 dVAE,将图片的 patch 于离散的 dVAE 隐变量对应,以进行基于掩码的自监督学习。如下图:
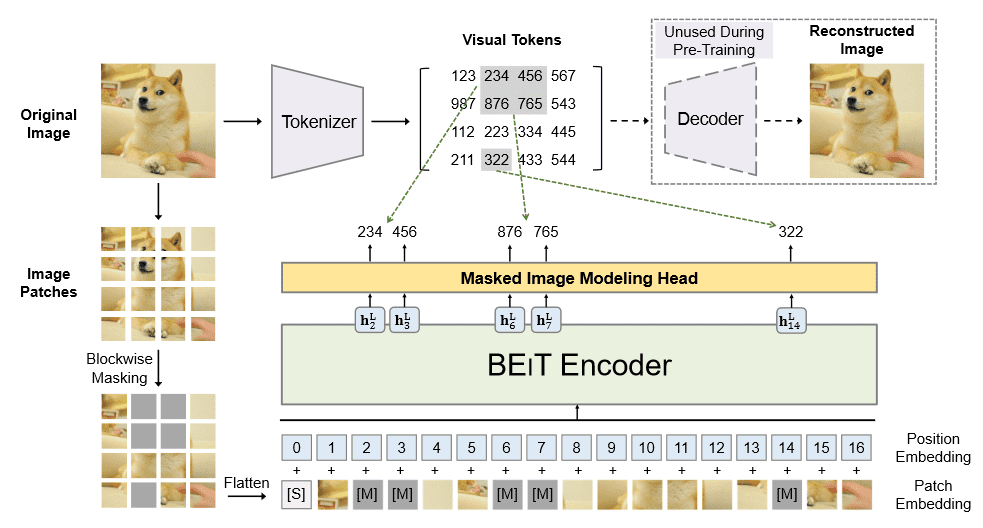
在预训练阶段,最多 mask 40% 的 patch,预训练在 16 卡 V100 上花了 5 天。预训练后,能够将模型用于微调,微调时抛弃 dVAE 部分。
MAE
论文提出,图像与语言之间的差异,是的 Masked Auto Encoder 在两个任务上的执行方式不同。
- 将 Transformer 应用在图片上,显得不是很自然,但这个问题在 ViT 等工作上得到了一定的研究与缓解。
- 语言的信息密度更大,一句话可以有很多中含义,因此基于掩码的自监督任务在语言上会更难,而在图片任务上会相对简单。
- 论文表示,要在图片任务上应用好 MAE 任务,主要的关键在于需要一个 decoder,来负责细腻度的表征学习与像素还原。而 encoder 则负责高纬度的抽象表征学习。
预训练方案:
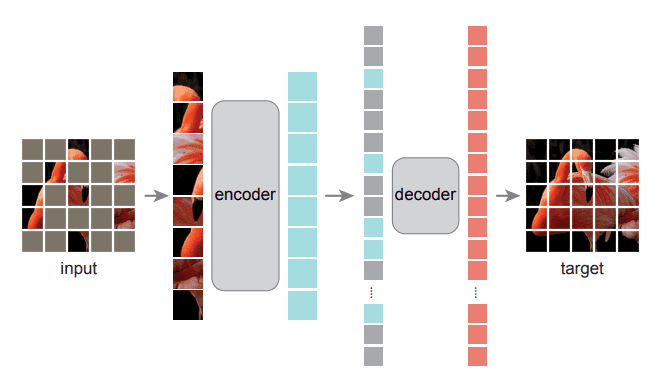
- 对图片进行 patch 分割,而后随机 masked (论文提出 75%是个好比例) 的 patch,masked 的 patch 丢弃掉,将剩下的 patch 放入到 ViT 中进行编码。
- 将得出来的结果按原图顺序进行排序(直接对上一步中为了随机掩码而做的 shuffle 工作进行逆处理即可),添加上对应的 position embedding,传入 decoder 中,预测图像被遮掩部分的像素。
- 优化目标采用了 MSE,对 masked 部分的 pixel 进行优化。
论文中也对比了不同的 mask 方案,如 blick,grid 等,但发现随机掩码的效果最好
其他论文
[1] Masked Autoencoders Are Scalable Vision Learners
[2] BEiT: BERT Pre-Training of Image Transformers
[3] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[4] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[5] Training data-efficient image transformers & distillation through attention
其他论文包括 MobileViT,Swim-ViT,DERT 等