YOLO 发展史笔记
YOLO 发展史
传统的物体检测需要经过两个 stage:
Stage 1:寻找备选框(regison proposal,如 RPN,经典的 RCNN,fast RCNN 等)
Stage 2:根据备选框寻找答案
One-Stage 的代表作有 SSD, YOLO 系列, RetainNet 等
物体检测框架
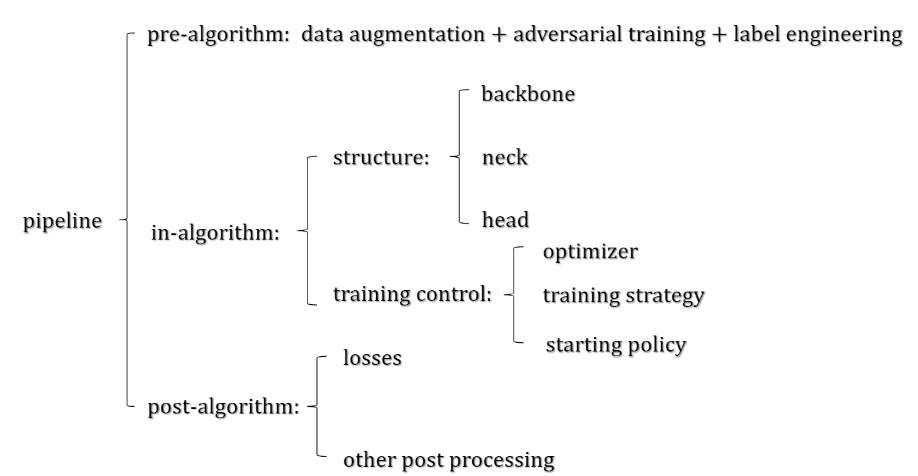
- label engineering 包括如 label 修正,label smoothing 等
- backbone 包括如 resnet,vgg,fpn 等;head 用于下游任务的解码;neck 就是中间承接的部分
- losses 是一个重点的,庞大的操作;
- 其他 post processing 包括 NMS 等
YOLO 1
- 输入
448 * 448,将图片分成7*7各 patch。图片中心在哪个格子,那个各自就负责预测那个物体。 该情况无法应对多个物体中心重叠的状况。 - 每个格子预测
b=2个 BBOX,bbox 包括[x, y, w, h]每个 bbox 对应一个置信度 - 输出结果: 对于 YOLO V1 就是 :两个
[c, x, y, w, h]+[20 classes]。然后图片分为7*7patch。
- 在代码中,可以直接用线性层统一进行前向传播,最后 reshape 成
[batch size, 7, 7, 30]即可。
- 将得到的带有 score 的 bbox 通过 NMS 或其他 post process 方法解码,得到候选框。大致流程是:
- 计算所有 bbox 的
score=c * p_class。 该步骤导致训练与预测时候,存在不一致。训练时候的 classification 与 regression 时分开训练的。 - 重复该步骤: 选出剩余 bbox 中,具有最大 score 的 bbox,去除掉其余 bbox 中,与其 IOU 大于某个阈值的 bbox。
- 计算所有 bbox 的
- loss 的计算方式:
其中 相当于 mask,仅对存在 label 的 grid 进行计算梯度。
宽度于长度采用根号,是希望能够通过非线性,来更好地对小物体和大物体进行回归。
物体检测存在样本非平衡情况,需要调整正负样本间的损失权重。
缺点总结:
- 对中心点重叠的物体、拥挤情况的场景不好。无法进行预测。
- 对小物体不好,对形状变化大的物体不好
- 没用 BN
- 基本上没有使用 YOLOv1 了。
YOLO 2
You Only Look Once: Unified, Real-Time Object Detection
相对于 YOLO 1,的改进:
batch norm
精度更高的分类器
- YOLO 2 将图片分为了
13*13个 patch,每个区域有 5 个 anchor,如果有 20 个目标类别需要预测,则输出格式为:[N, 13, 13, 5*(5+20)]。 - YOLO 1 是在
224*224的图片上训练的, YOLOv2 直接在448 * 448的分辨率上进行训练。
多尺度训练
预先分配好不同储存的图像集,如 320, 352, ... 608 等等,每经过 10 个 epoch,就随机选择一个新的图像尺寸来进行训练。这中多尺度输入,使得模型在预测试,支持各种大小尺寸图片的预测。
Fine-grained 特征
- 用不同程度的下采样,来学习浅层、深层信息。模型在
26 * 26分辨率的采样层,添加了一个类似 resnet 的通道,将浅层网络学到的一些宏观信息保留了下来。并为模型整体带来了 1% 的效果提升。
【重点】Anchor
相比于 YOLO 1 没有依据地进行预测,基于一个先验知识的 anchor 来预测,使得任务更加容易。Anchor 分为锚点与 anchor box,一个锚点可以对应多个 anchor box(如 fast rcnn,一个 anchor 锚点对应 9 各 anchor box)。R-CNN 中 Anchor 相当于 先验知识 ,是通过对 VOC 和 COCO 数据集的 bbox 进行 kmean 聚类后得出来的。 Faster-RCNN 中的 Anchor 的宽高和大小是手动挑选的)
Anchor 的作用大致为:
- 位置提示: 预测目标距离更近了
- 形状提示: 长宽比(aspect ratio)
- 尺度提示: 尺度与预测物体接近。
采用了 Anchor 后,loss function 的改变,预测目标从 yolo 1 的 [c, x, y, w, h] 更换为了计算从 Anchor 变换到 GT 的偏移量 [t_x, t_y, t_w, t_h],通常称为 offset。
计算 loss 时,与 gt 与 Anchor 的偏移量计算梯度。
YOLO 2 中的 Anchor 通过 Kmeans,从不同数据集中聚类得到,k=5 相当于选了 Avg IoU 曲线 elbow 处的 k 值。在源码中,Anchor 以 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, ... 的方式储存,如上例 16,33 代表第一个 anchor 的 w 和 h。
YOLO 2 的输出
基于 Anchor box ,我们需要对需要预测的 bbox 进行预处理:
raw bbox:
[x_0, y_0, w_0, h_0]normalize bbox by image W and H:
[x_0/W, y_0/H, w_0/W, h_0/H]缩放到
13*13尺度:x_s = 12 *x_0/W,其余指标同理根据 grid 对 x 和 y 计算偏移量:
t_x = x_s - x_grid根据 anchor 对 w 和 h 计算偏移量:
t_w = log(w_s/w_anchors)
因此 YOLO 2 的输出就是基于 grid 和 anchor 的偏移量
YOLO 2 损失
原始 YOLO 2 损失为 t_x, t_y, t_w, t_h各项的 MSE 以及分类器,confident 等 MSE 损失和。
其中 , 为预处理后的 gt bbox 坐标, 为 grid 坐标。,其中 为预处理后的 gt bbox 宽度, 为 anchor 宽度。得到输出后,可以通过 和 得到预测的 bbox 位置。
YOLO v3
YOLOv3: An Incremental Improvement
YOLO v3 开始,网络结构逐渐形成了模块化,出现了 backbone, neck, head 的形式。YOLO v3 的主要特点:
- 同样采用 Kmeans 提取 anchor box,但这次提取了 9 个。
- 采用了 logistic regression 进行物体分类。
- 采用了 3 个尺度进行 bbox 预测。
YOLO v3 架构与输出
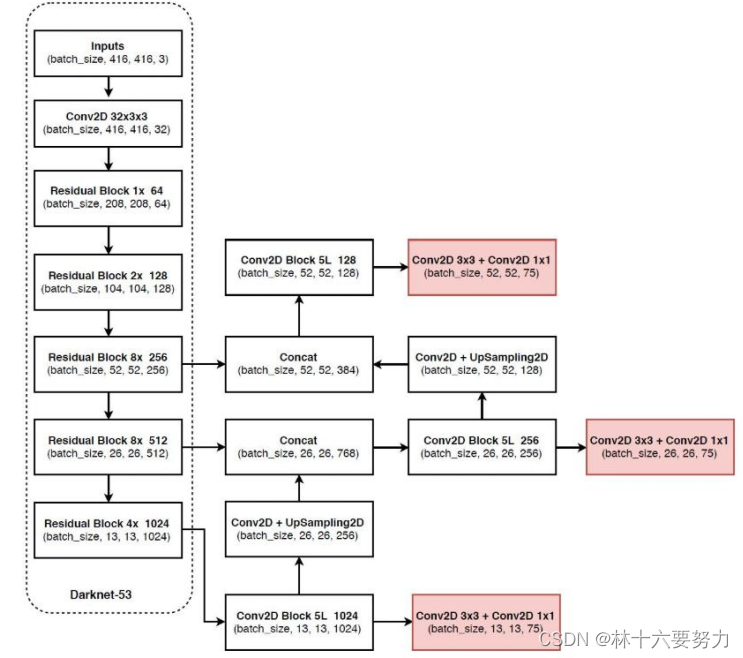
先对 input 进行 backbone 编码,原论文采用的是 Darknet。
将 backbone 最后 3 层的结果,传入 neck,原文中为 YOLO_FPN(体现为上图中的多次
Conv2D Block 5L+UpSampling2D),得到 3 个不同尺寸的yolo_feats。(UpSampling采用了普通的interpolate)将上步中 3 种不同的 yolo feats 传入到不同的 head 中(文中采用了简单的 conv 头),如上图红色框,最后得到预测结果。
3 种 scale 分别预测 3 个不同的 anchor box,每个 anchor box 预测 80 个类别和偏移量 5 元组,输出结果格式为
[c_x, t_x, t_y, t_w, t_h]+[class]*80。因此一个图片的输出结果为:
[13, 13, 3*(4+1+80)]
[26, 26, 3*(4+1+80)]
[52, 52, 3*(4+1+80)]
其中 3 为每种 scale 下预测 archor 的数量,为超参数。(13*13 用于预测大物体更具有优势)
- 最后采用 NMS 等方式进行解码。
【重点】输入处理方式
- 将 gt 的 bbox 分别进行归一化。
- 假设 anchor 与 bbox 中心点重叠,根据 anchor 的 w 和 h,计算每个 anchor 对应每个 bbox 的理论 IOU 值。
obj_mask的计算:每个 bbox 对应的obj_mask目标形状为[b, A, c, x, y]。通过floor(g_x), floor(g_y)确定预测该物体对应的 cell(即x, y值),A为 bbox 对应具有最大 IOU 的 anchor。对于以上确定好的[x, y, A]其对应的obj_mask目标值为 1。对应的non_obj_mask为 1。- 对
non_obj_mask,如果 bbox 与 anchor 的 IOU 大于某个阈值,则将对应的 target 目标设置为 0。(计算损失时候,我们将不计算这个 cell 的损失。)
YOLO 4
YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLO 4 开始,YOLO 原作者就退群了。YOLO v4 中,新作者对影响 YOLO 效果的两中方面进行了实验测试:
Bag of freebies:不影响 inference,只影响训练过程的方法,如数据增广,对抗学习,损失函数等。
Bag of specials:影响 inference 的效果提升方法,如 post-processing 方案等。
YOLO v4 采取的方案
Bag of Freebies (BoF) for backbone:
CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
PS:论文中有大量的实验对比数据。
Bag of Specials (BoS) for backbone
Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
Bag of Freebies (BoF) for detector
CIoU-loss, CmBN(Cross mini-Batch Normalization), DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler , Optimal hyperparameters, Random training shapes
Bag of Specials (BoS) for detector:
Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
Backbone:
CSPDarknet53:相当于在 resnet 外面再加一层残差链接。
Neck:
- 采用 SPP 替代了 FPN。
SPP:通过不同的步长和 window size 编码同一个 features,而后将结果进行拼接输出,比如用不同配置的 MaxPooling 拼接出多种维度的输出。
- 修改后的 PAN,用 concat 方式替代了原本 PAN 相加的方式。PAN 出自 Path aggregation network for instance segmentation。相当于再 FPN 的基础上,做了进一步的路径增强。
Head:
YOLOv3 head
Bag of Freebies 笔记
数据增广
- Mosaic: 用四张图片拼接成一张图片。
- mixup: 将多张图片,通过不同的透明度融合起来。实验发现融合两张图效果就不错了,此外在同一个 batch 中做 mixup 就能有足够好的效果。图片类别差别越大,mixup 效果越好。
- cutout: 随机遮盖一部分的像素。
- CutMix: 随机用另一张图上的一部分像素,遮盖原图的一部分像素。
标签工程 label engineering
- label smooth
- disturbLabel 人为地标错一些 label。
损失函数
L1/L2 loss: 缺点在于预测的整体性被破坏了,假设 x 变大,y 变小,那么总 loss 可能还是不变的,但实际上预测出来的位置偏移了很多。其次,L1 与 L2 loss 各自在训练时都有不稳定或难收敛的问题。
IoU Loss: 存在指标无法反映,或区分模型预测结果好坏的问题。如同时当 IoU 相同,但是形状不同的情况;或 IoU 都为 0 的情况。
GIOU loss: 寻找一个能够包含两个 bbox 的矩形。(不能解决两个 bbox 互相包含的问题。)
DIoU Loss: 寻找一个能够包含两个 bbox 的矩形,计算其对角线 c。计算两个 bbox 中心点距离 d。 。(无法解决形状带来的问题)
CIoU Loss: 其中
其中 用于调整训练过程中 的重要程度。
- generalized Focal Loss: 尝试解决模型训练与 NMS 解码过程中的不一致问题。
- distribution bbox: 尝试解决目标边框模糊问题。
正则化改良
- DropBlock: 由于 Conv 存在 local info share 情况,因此普通的 dropout 对 Conv 效果是不好的。因此可以采用 DropBlock,基于 patch 进行 dropout。
Bag of specials
只影响 inference 的效果提升方法,如 post-processing 方案等。
激活函数
relu 是 non-zero centered 的,在 bp 时候容易 zigzag,影响训练速度和效果。
改良:swish/silu()、mish
YOLO v4 中还尝试了 leaky-Relu,ReLU6, parametric-ReLU 等
框架
head 中的解耦
- YOLO HEAD 中,classification 与 IOU 损失不可兼得
- 训练中,classification 越来越好
- 在 YOLOX 中,head 中有了比较成熟的解耦方案,将 classification,regression 与 IOU 分解开来。
FC 和 CONV 的区别
- FC 对 classification 效果好,Conv 对 regression 效果好。
深层解耦
- tsd 方案:效果好,但速度很慢。
YOLO 5
YOLO v5 github 找不到论文。
YOLO v6
美团的作品,有一部分争议。YOLO V6 github
论文:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
主要点在于:
- 训练时候尝试了 self-distillation strategy。训练时候,用与寻来你的模型作为教师模型,蒸馏新任务下的模型。
- 相对于 YOLO v4,尝试了一些更新的精度提升方案。包括解耦检测头等
- 尝试了 RepOptimizer(Reparameterizing Optimizer)。
- 采用了 anchor free 方式(anchor point)
YOLO v7
Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLO V7 整体基于 YOLO v5 升级。训练时候的输入像素为 1280 * 1280 或 640*640
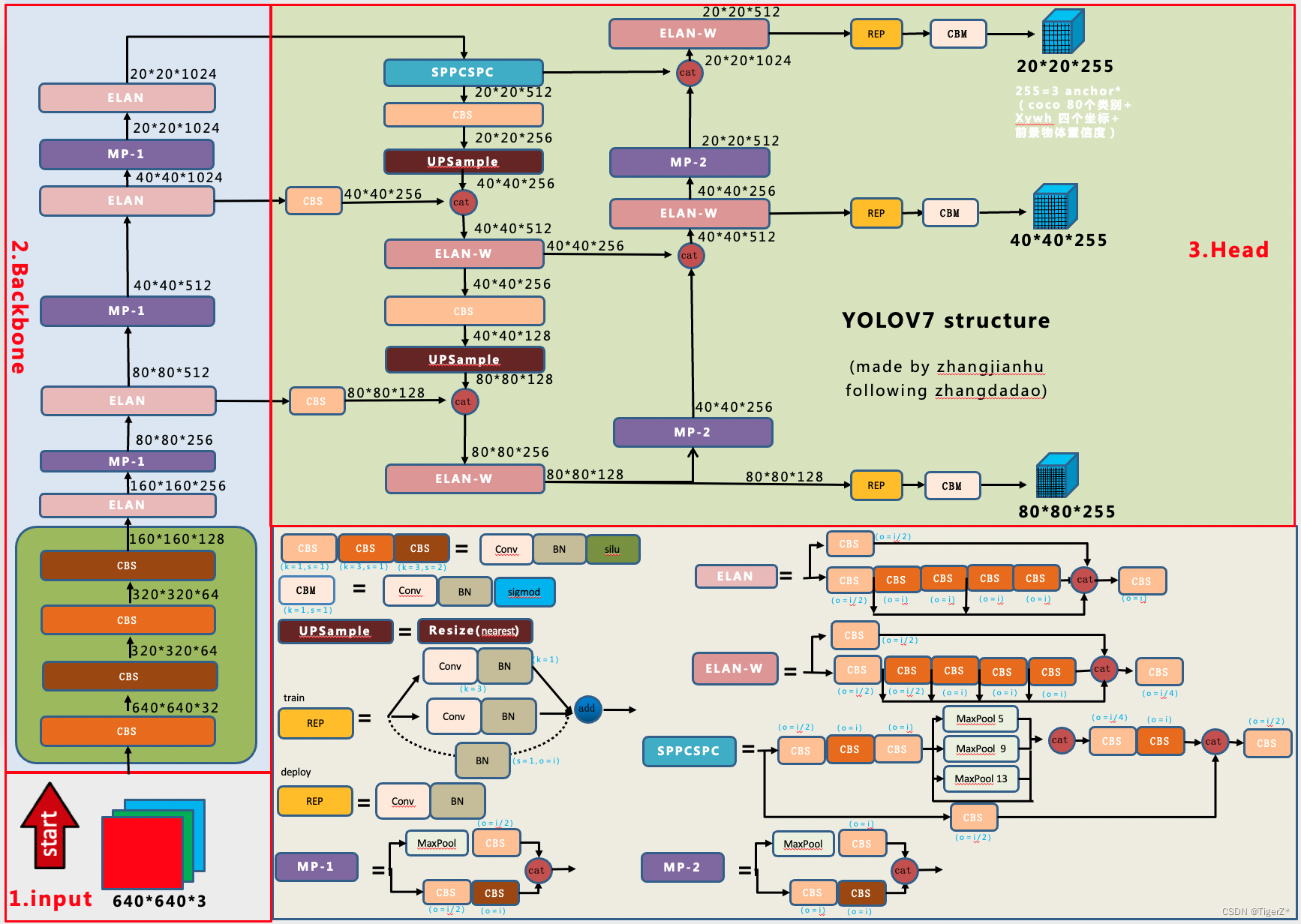
Backbone
由 stem + ELANNet + SPPCSPC 组成。
Stem
由多层 CBS(conv + bn + silu) 组成,tiny 模型 2 层,常规模型 4 层。
ELAN NET
整个 ELAN NET 可以看作 ELAN + 3 个 MP + ELAN 模块的拼接。
从 VoVNet 到 ELAN 模块
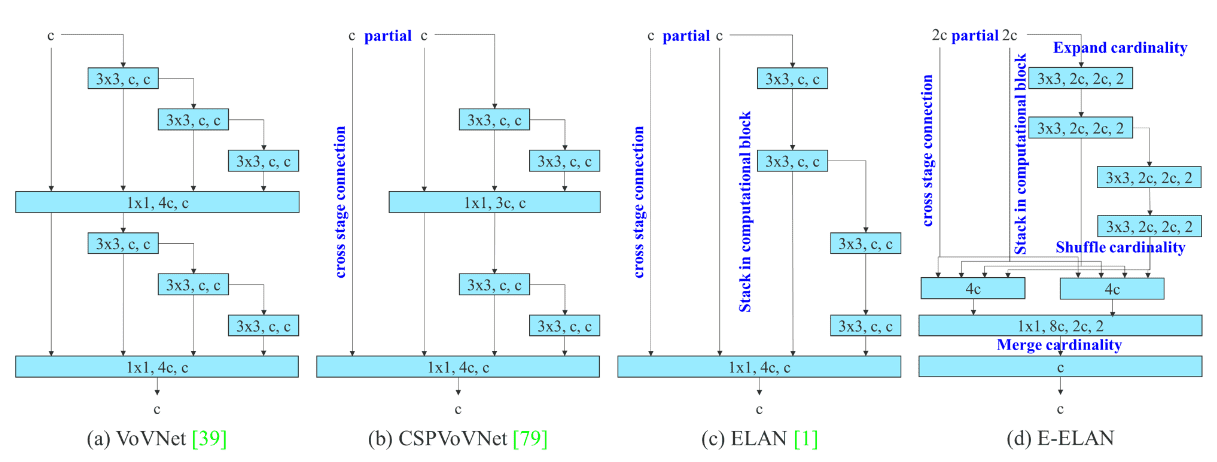
VoVNet
- densenet 每层之间都有 resdual connection,但是计算效率太慢,于是提出了 VoVNet,在做 features aggregation 同时,提高效率。
CSPVoVNet
- 参考 CSP 思想,再 VoVNet 外层加入了额外的通道。
ELAN & E-ELAN
- 参考了 ShuffleNet v2 的思想,简化 CSPVoVNet,目的在于更高效的模型训练和推理。:
- Tensor 的输入输出 channel 数越近似,推理速度越快。
- Channel 分组数量越小越好
- 网络分支(fragment)减少了并行度
- 实验说明,Elementwise 的操作很耗时。
因此 YOLO v7 的基础单元采用了 ELAN,而 E-ELAN 只在 aux head 中使用了。 ELAN 模块可以使用以下方式优雅的实现:
outs = []
x_1 = self.conv1(x)
x_2 = self.conv2(x)
outs.append(x_1)
outs.append(x_2)
idx = [i + self.num_blocks for i in self.concat_list[:-2]]
for i in range(self.num_blocks):
x_2 = self.bottlenecks[i](x_2)
if i in idx: # idx = [1, 3]
outs.append(x_2)
outs = outs[::-1] # [-1, -3]
x_all = paddle.concat(outs, axis=1)
y = self.conv3(x_all)
MP 模块
x_1 = self.conv1(self.maxpool(x))
x_2 = self.conv3(self.conv2(x))
x = paddle.concat([x_2, x_1], axis=1)
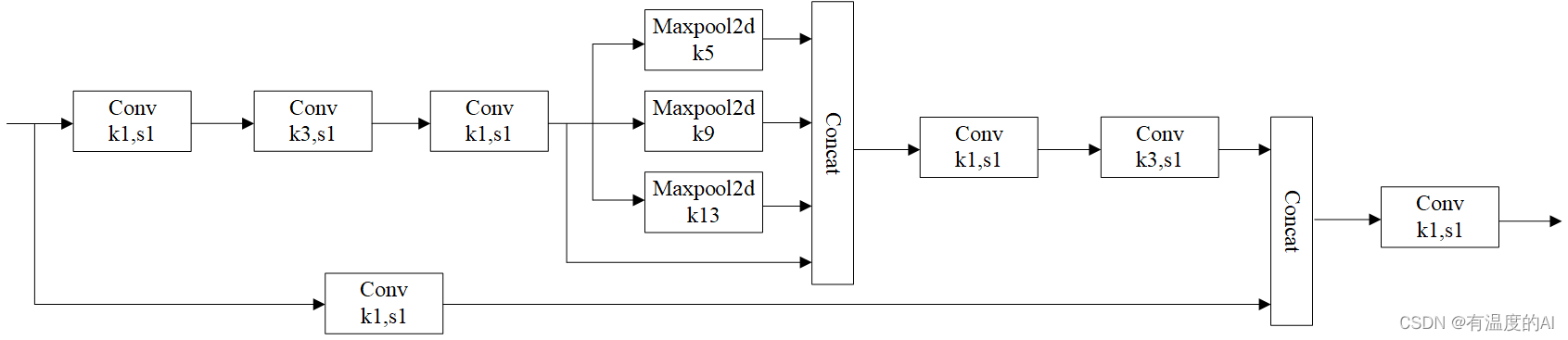
SPPCSPC
顾名思义:SPP + CSP + Conv:
Neck
Neck 部分 为经典的 PAFPN。其中的单元模块变成了 ELAN-W + CBS。
HEAD
与 YOLO v3 大致框架相同,同样的分成了 3 个不同的 scale 来进行预测,每个 scale 有 3 个 anchor。
添加了 RepConv 通道
再 PAFPN 的各层输出处,链接上 RepConv 来作为检测头。该思想来源于 RepConvN 原作者解读。Resnet 由于有 shortcut,训练效果好,但是推理速度不快。RepConvN 提出了可以训练一个多分支模型,而后再推理时候,将多分支模型转换为单路模型,以提高推理速度和精度。实现方法就是:
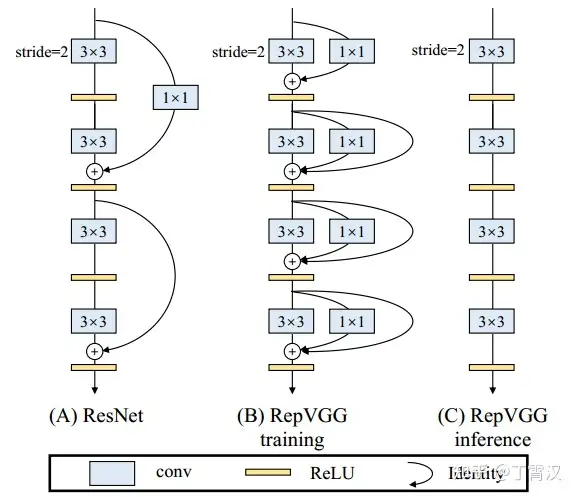
其实非常简单,因为 RepVGG Block 中的 1x1 卷积是相当于一个特殊(卷积核中有很多 0)的 3x3 卷积,而恒等映射是一个特殊(以单位矩阵为卷积核)的 1x1 卷积,因此也是一个特殊的 3x3 卷积!我们只需要:1. 把 identity 转换为 1x1 卷积,只要构造出一个以单位矩阵为卷积核的 1x1 卷积即可;2. 把 1x1 卷积等价转换为 3x3 卷积,只要用 0 填充即可。
因此,一个 RepConvN 就可以通过结构重参数化编程单路网络了。
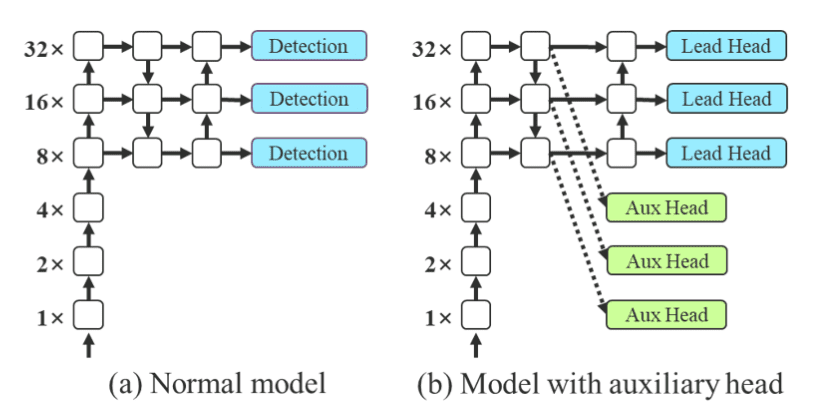
Auxliary heads
再中层特征和浅层网络加 loss,可以引导网络的学习。因此额外添加了 Aux Heads,并再训练时,针对他们计算额外的 loss,并进行优化。
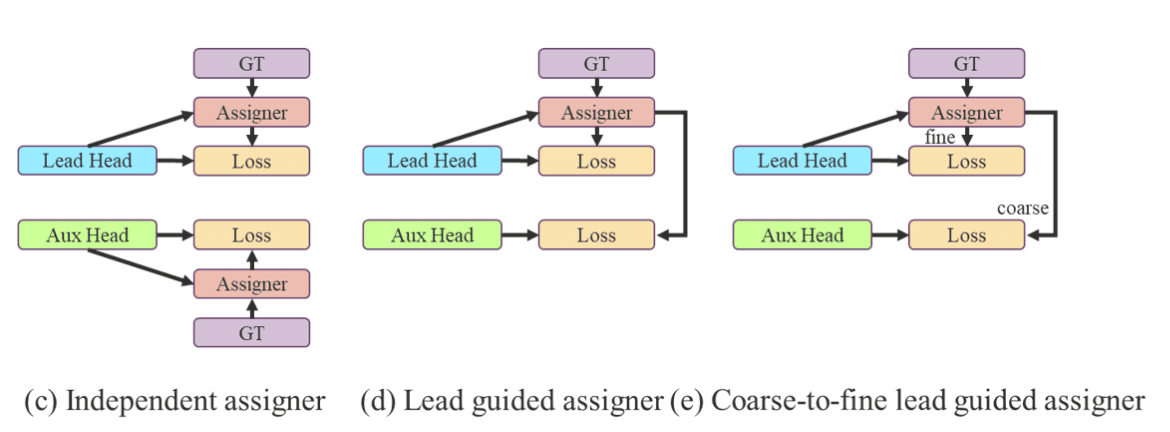
Label Assigner
参考了 YOLOX 的 SimOTA 思想,扩充了正样本的数量:从 1 各 GT 的 bbox 配一个 Anchor,变成为 1 各 Anchor 配多个 Anchor(当 GT bbox 的长宽比与 anchor 长宽比大于某一个阈值时,就让 anchor 负责这个 gt 的检测)。而后根据 GT 框的中心位置,将最近的两个 grid 也作为预测网络。
- Coarse-to-fine auxiliary loss
aux head 负责 coarse 的回归(提升 recall 效果),而 lead head 负责 fine 的回归。因此 Label Assigner 会将扩充的正样本(soft label)更多的分配到 aux head 的检测范围内,但该方案提升较小。
参考论文
[1] RepVGG: Making VGG-style ConvNets Great Again
[2] YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
[4] YOLO9000: Better, Faster, Stronger
[5] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[6] YOLOv3: An Incremental Improvement
[7] You Only Look Once: Unified, Real-Time Object Detection