音频格式与编码
- 声音是什么?
- 物理层面 :空气分子的振动 → 声压随时间变化的波。
- 模拟信号 :连续的波形,既有时间连续性,也有幅度连续性。
但计算机只能处理离散的数字,所以要“采样 + 量化”成数字信号。
- 采样与量化(数字化的第一步)
声音本质:连续的模拟信号
大约 10 分钟
但计算机只能处理离散的数字,所以要“采样 + 量化”成数字信号。
声音本质:连续的模拟信号
# server.py
from mcp.server.fastmcp import FastMCP
from mcp.server.fastmcp.prompts import base
# Create an MCP server
mcp = FastMCP("Demo")
# Add an addition tool
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
# Add a dynamic greeting resource
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
"""Get a personalized greeting"""
return f"Hello, {name}!"
本文梳理了 DPO,GRPO 的主要特点、亮点以及相关资源链接。
先来回顾以下 PPO,采用 PPO 的 RLHF 会经过 reward model tuning 和 Reinforcement Learning 2 个步骤:
AUTOGEN 是一个开源平台,主要用于创建和管理自动化对话代理(agents)。这些代理可以完成多种任务,比如回答问题、执行函数,甚至与其他代理进行交互。
本文旨在介绍 Autogen 中的关键组件 Conversation Agent,并对其中的 Multi-Agent 功能实现做简单的源码分析。
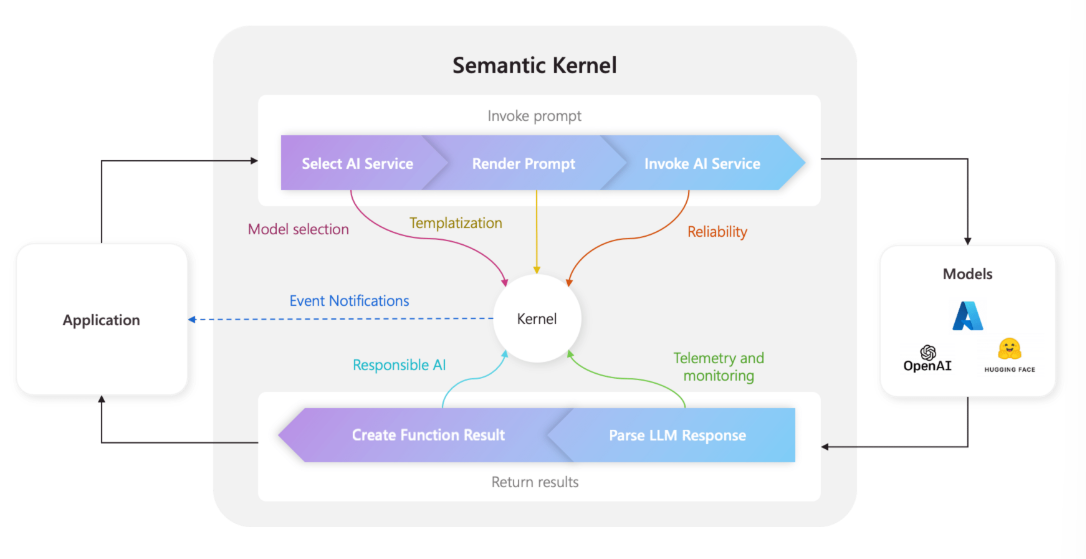
本文对 Semantic Kernel 中的 Kernel,Plugin,KernelFunction,Semantic Memory,Planner,Services,reliability 等进行概念介绍。
本文基于 HuggingFace 推出的 Reinforcement Learning Course 进行了整理,旨在记录强化学习的基础知识,为理解 RLHF(Reinforcement Learning from Human Feedback)打下基础。需要强调的是,以下内容仅涵盖强化学习的基础概念及 RLHF 基础,并非全面的强化学习教程。
块存储(Block Storage)
大模型上下文在前段时间有点火,TODO 里堆积的论文也越来越多(。
本文记录了 LLM 在长度外推方面的文章笔记,包括位置编码相关的 ALiBi 、 ROPE 和 线性插值(PI) , NTK ;注意力相关的 GQA , SWA , LM-INFINITE , StreamingLLM ;以及 meta 的综述 Effective Long-Context Scaling of Foundation Models 记录。