Fooocus
https://github.com/lllyasviel/Fooocus
python entry_with_update.py --language zh --port 8000
大约 4 分钟
https://github.com/lllyasviel/Fooocus
python entry_with_update.py --language zh --port 8000
本文介绍 IP-Adapter,结合笔者的使用体验,在垫图方面,IP-Adapter 效果比 Controlnet reference only 及 SD 原生的 img2img 效果要好很多。并且可以配合 controlnet 的其他风格(如 canny 或者 depth)来实现多维度的图片生成控制。
回顾 LDM 中的 img-to-img 部分,LDM 中图像与文字交互的方式为单纯的 cross-attention:
对于 Consistency Model,Latent Consistency Model 及 LCM-LoRA 的原理解读,十分推荐这篇文章:
https://wrong.wang/blog/20231111-consistency-is-all-you-need/
具体细节建议参考上面推荐的文章链接,以下对大致思路进行总结:
来自论文:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL 不论在模型架构还是 diffusion pipeline 上都与 SD 不同。十分推荐 Rocky Ding 的 SDXL 分享:
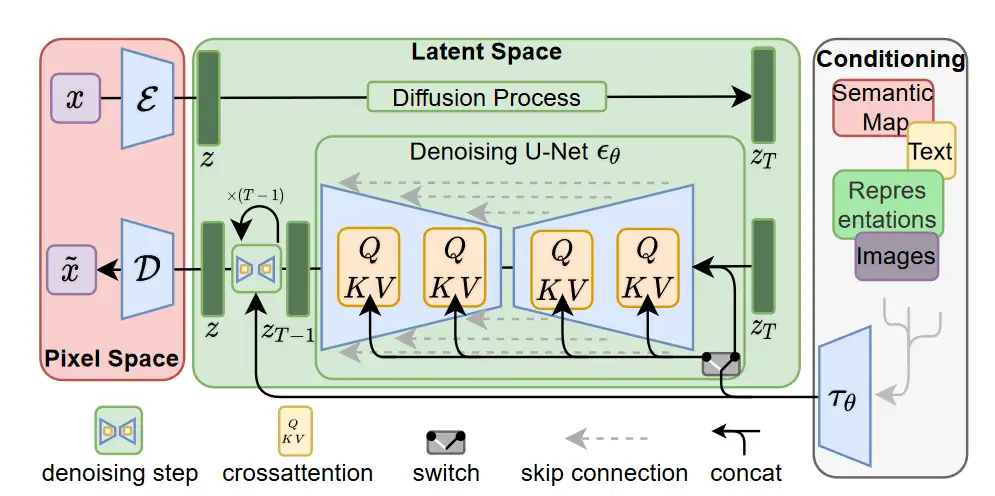
相对于 DDIM, DDPM 以及 SDE,High-Resolution Image Synthesis with Latent Diffusion Models 一文重点在于 latent Space 和 Conditioning Cross Attention,而非 diffusion pipeline 流程。
以此不同于前几份笔记,本文主要参考 huggingface/diffusers 中 Latent Diffusion Model 及 Stable Diffusion 的实现,对 LDM 架构及其中的 Conditioning Cross Attention 做梳理。
妙鸭的热度过了一阵子了,网上对妙鸭背后的实现逻辑有这种各样的猜测,不少网友认为妙鸭只是简单的采用 SD + Lora。本文主要对 SD + Lora 方案进行探索,分析妙鸭采用 SD + Lora 方案的可能性。
推荐使用现有的 GUI AUTO1111/stable-diffusion-webui 。安装指南可以参考官方仓库下的安装方案,或者其他网友笔记,比如 AUTOMATIC1111/stable-diffusion-webui 安装教程_咔!哈!的博客-CSDN 博客 。
论文 SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS
从 stochastic differential equations 的角度,尝试提出了一个统一的模型框架,来概括 DDPM,SMLD 等 score-based generative models。
该论文的作者 宋飏 在他的博客中也详细地介绍了该模型的理论,并且提供了基于 torch 的 Colab 教程。本文主要基于宋飏的博客,对该论文提出的模型思路进行了重新整理。
论文:DENOISING DIFFUSION IMPLICIT MODELS